
Selenium是广泛使用的模拟浏览器运行的库,它是一个用于Web应用程序测试的工具。 Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,并且支持大多数现代 Web 浏览器。下面就进入正式的学习阶段。
激活虚拟环境
通过pip安装
2.1 确定浏览器版本
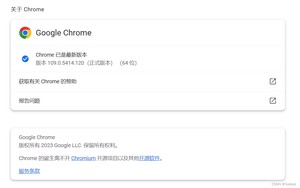
点击chrome浏览器最右侧的“三个点”图标,然后点击弹出的“帮助”中的“关于Google Chrome”,查看自己的版本信息。这里我的版本是94,这样在下载对应版本的 Chrome 驱动即可。
2.2 下载驱动
打开 下载Chrome驱动网页。单击对应的版本。

根据自己的操作系统,选择下载。
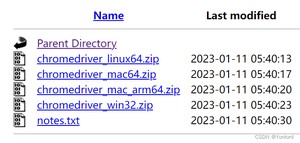
下载完成后,压缩包内只有一个 exe 文件。
如果能弹出Chrome浏览器,则说明安装成功。
1.1 初始化浏览器对象
前期我们将Chrome驱动添加到环境变量了,所以我们可以直接初始化界面。(或者也可以通过指定绝对路径的方式)
1.2 访问页面
进行页面访问使用的是get方法,传入参数为待访问页面的URL地址即可。
1.3 设置浏览器大小
set_window_size()方法可以用来设置浏览器大小(就是分辨率),而maximize_window则是设置浏览器为全屏。
1.4 前进后退
前进后退也是我们在使用浏览器时非常常见的操作,这里forward()方法可以用来实现前进,back()可以用来实现后退。
1.5 获取页面基础属性
当我们用selenium打开某个页面,有一些基础属性如网页标题、网址、浏览器名称、页面源码等信息

使用 selenium 定位页面元素的前提是你已经了解基本的页面布局及各种标签含义,当然如果之前没有接触过,现在我也可以带你简单的了解一下。
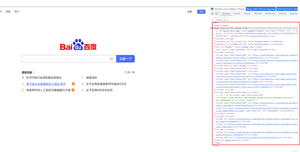
以我们熟知的 百度为例,我们进入首页,按 【F12】 进入开发者工具。红框中显示的就是页面的代码,我们要做的就是从代码中定位获取我们需要的元素。
我们在实际使用浏览器的时候,很重要的操作有输入文本、点击确定等等。对此,Selenium提供了一系列的方法来方便我们实现以上操作。通过webdriver对象的 find_element(by=“属性名”, value=“属性值”),主要包括以下这八种。
还是以百度举例子
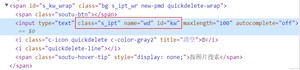
可以看到这个对应的class,name以及id分别是这些,通过以下语句都可以定位到这个元素。
既然是模拟浏览器操作,自然也就需要能模拟鼠标的一些操作了,这里需要导入ActionChains 类。
3.1 常用操作
这个其实就是页面交互操作中的点击click()操作。
引入Keys类
4.1 常用操作
5.1 强制等待
就很简单了,直接time.sleep(n)强制等待n秒,在执行get方法之后执行。
5.2 隐式等待
implicitly_wait()设置等待时间,如果到时间有元素节点没有加载出来,就会抛出异常。
5.3 显式等待
设置一个等待时间和一个条件,在规定时间内,每隔一段时间查看下条件是否成立,如果成立那么程序就继续执行,否则就抛出一个超时异常。
WebDriverWait的参数说明:
driver: 浏览器驱动
timeout: 超时时间,等待的最长时间(同时要考虑隐性等待时间)
poll_frequency: 每次检测的间隔时间,默认是0.5秒
ignored_exceptions:超时后的异常信息,默认情况下抛出NoSuchElementException异常
until(method,message=‘’)
method: 在等待期间,每隔一段时间调用这个传入的方法,直到返回值不是False
message: 如果超时,抛出TimeoutException,将message传入异常
until_not(method,message=‘’): 与until相反,until是当某元素出现或什么条件成立则继续执行,until_not是当某元素消失或什么条件不成立则继续执行,参数也相同。
6.1 窗口切换
在 selenium 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 selenium 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
窗口切换需要使用 switch_to.windows() 方法。
首先我们先看看下面的代码。
上面代码在点击跳转后,使用 switch_to 切换窗口,window_handles 返回的 handle 列表是按照页面出现时间进行排序的,最新打开的页面肯定是最后一个,这样用 driver.window_handles[-1] + switch_to 即可跳转到最新打开的页面了。
那如果打开的窗口有多个,如何跳转到之前打开的窗口,如果确实有这个需求,那么打开窗口是就需要记录每一个窗口的 key(别名) 与 value(handle),保存到字典中,后续根据 key 来取 handle 。
6.2 表单切换
很多页面也会用带 frame/iframe 表单嵌套,对于这种内嵌的页面 selenium 是无法直接定位的,需要使用 switch_to.frame() 方法将当前操作的对象切换成 frame/iframe 内嵌的页面。
switch_to.frame() 默认可以用的 id 或 name 属性直接定位,但如果 iframe 没有 id 或 name ,这时就需要使用 xpath 进行定位。下面先写一个包含 iframe 的页面做测试用。
cookies 是识别用户登录与否的关键,爬虫中常常使用 selenium + requests 实现 cookie持久化,即先用 selenium 模拟登陆获取 cookie ,再通过 requests 携带 cookie 进行请求。
webdriver 提供 cookies 的几种操作:读取、添加删除。
get_cookies:以字典的形式返回当前会话中可见的 cookie 信息。
get_cookie(name):返回 cookie 字典中
key == name 的 cookie 信息
add_cookie(cookie_dict):将 cookie 添加到当前会话中
delete_cookie(name):删除指定名称的单个 cookie
delete_all_cookies():删除会话范围内的所有cookie
比如下拉进度条,模拟javaScript,使用execute_script方法来实现。
1.1 判断元素是否存在
1.2 滑动滚轮到页面底端
1.3 滑动滚轮至页面元素出现
将上面两者结合,就可以实现。
1.4 滑动至动态元素可见
当我们需要定位的元素是动态元素,或者我们不确定它在哪时,可以先找到这个元素然后再使用JS操作
XPath语法通配符
2.1 文本定位
使用text()元素的text内容 如://button[text()=“登录”]
2.2 模糊定位
2.3 逻辑定位
使用逻辑运算符 – and、or;如://input[@name=“phone” and @datatype=“m”] 可以根据一个元素的多个属性进行定位,确保唯一性
2.4 轴定位
轴定位是根据父节点,兄弟节点等节点来定位本节点,使用语法: 轴名称 :: 节点名称,使用较多场景:页面显示为一个表格样式的数据列
selenium的基础用法已经介绍完了,让我们实际操作起来吧,有什么问题欢迎在评论区留言,希望大家能够点赞收藏!!!
selenium用法详解【从入门到实战】
selenium的基本操作——入门级(快速上手)
2 万字带你了解 Selenium 全攻略
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/2341.html