
预测包括,数值拟合,线性回归,多元回归,时间序列,神经网络等等
对于单变量的时间序列预测:模型有AR,MA,ARMA,ARIMA,综合来说用ARIMA即可表示全部。
数据和代码链接:
以预测美国未来10年GDP的变换情况为列:
目录
第一步进行数据导入
第二步进行平稳序列分析
第三步进行不平稳序列的差分运算
第四步进行模型定阶和模型选择及拟合
第五步进行模型结果分析和模型检验
第六步进行模型预测
PS:自动化AUTO-ARIMA的比较
ARIMA流程图如下:

结果如下: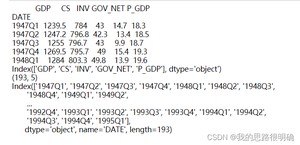
我们研究分析的时间序列,即面板数据,只有是宽平稳的才有研究意义,如果是非平稳序列需要将其差分转换为平稳序列才能进行分析,对于严平稳序列,性质不变化,即序列为白噪声序列,这样的序列没有研究意义。
所以这里拿到GDP的时间序列数据后,先进行原序列的白噪声检验,利用LB统计量,若p值小于显著水平a=0.05,即认为原序列为非白噪声序列,有研究的意义。
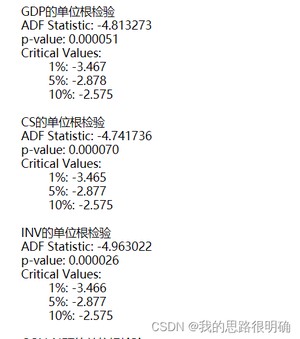
接着画时序图,主观上判断GDP时间序列的平稳情况,若呈现明显的趋势性,则为非平稳序列;若没有明显趋势,或者出现你不好判断平稳的情况,这时候你需要借助ADF单位根统计量来进行辅助判断它是否平稳。对于ADF统计量,你可以比较统计量的值来判断,也可以比较p值来判断,如显著水平a=0.05时候,如果你变量的ADF统计量小于a=0.05对于的ADF统计量,则说明该变量对应的时间序列为平稳序列;还一种更为直接的方法是,只需要判断该变量的p值如果小于0.05,则也说明为平稳序列。
代码结果:
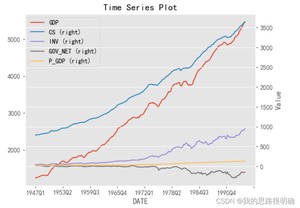
一般时间序列的差分不会超过三阶,对原始数据进行差分运算,重复第二步的时序图和ADF单位根检验操作,若发现差分后的序列为平稳序列,则记下差分的阶数,这里GDP的差分阶数1,通过了平稳序列检验。再次对差分后的序列进行白噪声检验,若通过为非白噪声序列,则进行下一步操作。
代码结果如下:
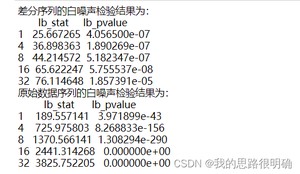
模型定阶先采用自相关图和偏自相关图进行初步判断:
自相关系数 偏自相关系数 差分
AR 拖尾 p阶截尾 0
MA q阶截尾 拖尾 0
ARMA 拖尾 拖尾 0
ARIMA 拖尾 拖尾 d
总之,上述的模型都可以用ARIMA(p,d,q)来实现,AR,MA,ARMA都是ARIMA的特殊情况。
对于拖尾和截尾的经验判断:
拖尾:负指数单调收敛到0,或者呈现余弦式衰减
截尾:迅速衰减到0,并且在0附近波动
截尾比拖尾趋近于0更加迅速,截尾在后期不会再有明显的增加
在利用图表进行初步判断后,依旧无法拿准模型的阶数,可以利用AIC和BIC准则进行辅助判断,或者叫做优化。比如我判断模型的阶数可能为2,1,4,或者3,1,3,这时候我拿不准,你可以先做ARIMA(2,1,4),如果发现后续的模型显著性检验和参数检验都通过了,那么你可以直接利用ARIMA(2,1,4)进行预测并得到结论,但你或许也去尝试附近的几个阶数,发ARIMA(3,1,3),ARIMA(2,1,3)等等也通过了,但是ARIMA(3,1,3)的AIC和BIC的值是最小的,即该模型的拟合精度更高,是一个相对最优的模型,这一步便是模型的优化。
这边的定阶和优化在python里的实现是:从q为0到(数据长度/10),从p为0到(数据长度/10),一般阶数不会超过(数据长度/10);然后进行q*p次模型拟合,利用模型拟合的结果比较AIC和BIC的值,BIC值越小越小的那个模型就是相对最优模型,再用该模型的阶数作为最终模型拟合的阶数。
代码结果:
模型检验分为模型参数检验和模型显著性检验。
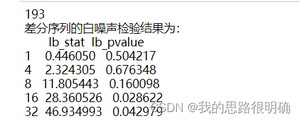
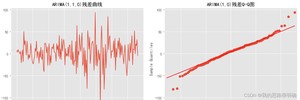
模型显著性检验:即残差的白噪声检验,若残差为白噪声序列,即原序列信息提取充分,看LB统计量,python中模型结果的LB统计量即为残差的LB统计量,若p值小于0.05,则为非白噪声序列,若p值大于0.05,则说明残差为白噪声序列,这是我们想要的结果。这里你可以单独拿出模型的残差值,自己绘制残差的时序图,图,正态分布图,或者自己进行白噪声检验辅助判断。白噪声序列即服从正态分布,时序图是平稳波动,图上的数值点在对角线附近。
模型的参数检验:检验每一个未知参数是否显著为0,检验模型是否最精简。参数不显著非零,则可以从拟合模型从剔除,看t统计量。
模型结果部分解释:
const:常数项
ar.L1:自回归项系数
ma.L1:移动平均项系数
sigma2:方差
各个参数下的P>|z|这一行,若小于a=0.05则拒绝原假设,认为参数显著非0,即不需要简化模型。
Ljung-Box:LB统计量,这里需要注意的是LB的P值需要>0.95,即判断残差序列为白噪声序列,小于0.05为非白噪声序列。
Jarque-Bera:JB统计量
Heteroskedasticity检验的结果表明方差稳定情况
代码结果为:

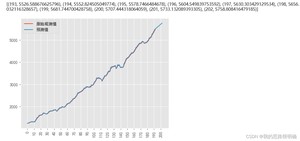
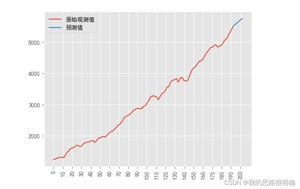
模型预测即利用上述的相对最优模型进行原始数据变量后续时间对应的值的预测。
注意在python中,predict函数如果是对差分数据进行预测,注意start的起始和end的中止情况,比如一阶差分的数据是从第二个观测值
开始进行,对应的残差也是如此,在后续绘图的时候需要注意到差分模型绘图的情况。
代码结果:
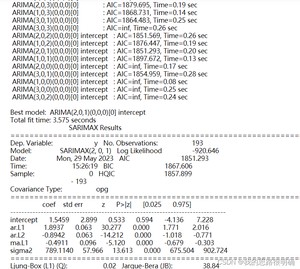
这一块个人没有深入研究,auto的方法有优点也有缺点, 也算提供一个写代码的思路。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/2334.html