
谢邀。
虽然你在线程池的用途上有些混乱,但是这个问题其实蛮不错的,所以详细说一下希望对有需要的朋友提供一点帮助。
我们来详细讨论一下:
不管是 per thread per epoll 还是一个 epoll+线程池,应该抓住关键点。
我们一步步地梳理一下逻辑哈:首先假设您的侦听socket只有一个,这个侦听 socket 必然要绑定且只能绑定到一个 epoll 上(不管是侦听 socket 还是普通与客户端连接的 socket 同时绑定到多个epoll 上不仅处理起来麻烦,也是非常不好的做法),所以这里可以有且只有一个线程来对应这个 epoll,我们暂且把这个线程叫做线程 A,把这个 epoll 叫做 epollA; 接着 epollA 检测到新客户端请求连接,并接受客户端连接产生客户端 socket,这个 socket 我们叫做 B、C、D 等等(可能有许多)。这些与客户端连接对应的 socket 挂到哪里去?有两种思路:
第一种思路:挂到原来的 epollA 上,这样的话,线程A不仅要接受客户端连接(侦听 socket 上的事件)),还要处理客户端的来的数据(普通客户端端 socket B、C、D 等等),这种当连接数量比较多、来往数据比较多的时候,可能一个线程 A 忙不过来,效率不行。这种结构如下图所示:
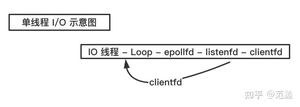
Redis 就是这种单线程模型。
第二种思路:将 socket B、C、D 等以某种策略挂到新的 epoll 上,这些新的 epoll 我们暂且称为 epollB、epollC、epollD,当然分别对应线程 B、线程 C、线程 D 等等(具体数量根据你的需求来确定,但不能无限多,一般也就几个),比如轮询策略,即新来一个 socket B,挂到 epollB 上,接着来了 socket C 挂到 epollC 上,又来了 socket D 挂到 epollD 上,再来了 socket E 又挂到 epollB 上。因为产生 socket B、C、D 是在线程 A,而需要挂到 epollB、epollC、epollD 所在的线程上(在各个 epoll 上面移除 socket 同理),这里挂接和移除操作可能需要锁。这就是所谓的 per thread per epoll,或者叫 per thread per loop(一个线程一个循环),这里就是一组线程了,其中每个线程都有一个 epoll,只不过第一个 epoll 只绑定侦听 socket,其他的 epoll 绑定客户端 socket(当然,如果你觉得第一个 epoll 比较闲,也可以在上面绑定一些客户端 socket)。这两种结构如下图所示:
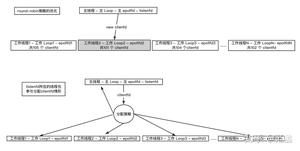
这两种结构是现在大多数服务器的结构。
说到这里咱们再深入一点,每个线程循环的结构如下:
while (!m_bQuit) { //步骤一:使用select或者epoll_wait等IO复用技术检测socket上是否有读写或出错事件 // 对于第一个循环,只检测侦听socket是否有事件 epoll_or_select_func(); //步骤二:检测到某些socket上有事件后处理事件,比如收数据,对于第一个循环可能是 //接受客户端连接,接收完数据解数据包进行业务逻辑处理 handle_io_events(); //步骤三:做一些其他事情 handle_other_things(); } 这是这个结构的最基本逻辑,在这基础上可以延伸出很多变体,例如:不知道你有没有发现,步骤二中如果解数据包或者业务逻辑处理过程比较耗时(计算密集型),那么会导致 thread 在这个步骤停留时间很长,导致很久以后才能走下一次循环,影响网络数据的检测和收发。所以 handle_io_events() 这个步骤中,我们又可以拆出一部分功能出来,比如将数据解包完后,产生的业务数据再交给另外一批线程(又来一个线程池),这批线程我们叫做业务线程(业务线程具体做什么顾名思义根据你的程序业务来决定),这个过程业务数据从网络线程组(生产者,epoll 线程组)流向业务线程组(消费者)的时候,也要加锁,因为业务线程会不断取出业务数据进行处理。
如果你能清晰明白地看到这里,说明你大致明白了一个不错的服务器框架是怎么回事了。
如果你有兴趣,咱们可以再进一步:
由于 CPU 核数有限,当线程数量超过 CPU 核数时,各个线程(网络线程和业务线程)也不是真正地并行执行,那么即使开了一组业务线程也不一定能真正地并发执行,那么我们不如就在网络线程里面处理。
上文也说了不能在步骤二的 handle_io_events(),但是我们可以放到 handle_other_things() 中处理呀,但是这里有个疑问,我产生了一个业务任务需要 handle_other_things()这个函数立即执行,而循环可能还挂在步骤一的 select 或者 epoll_wait 上,怎么办?没关系,我们可以使用一些"技术"手段立即唤醒他们,比如给 epoll 或者 select 额外绑定一些“功能” socket,Linux 还可以绑定 eventfd 或者 socketpair。当我们网络数据解包后产生业务任务后,只要往这些 socket 或者eventfd 上随便写一个数据,epoll_wait 或 select 因为检测到这些“功能” socket 可读事件就会立刻返回了,接下来的流程就走到 handle_other_things(),对我们的业务任务进行处理了。
特别说明一下:
这种所谓的技巧在handle_other_things()里面不会有耗时的任务的才可以替代专门开业务线程,如果有耗时操作还是老老实实开业务线程吧。
这就是目前主流的网络库的设计思想和基本框架原理,如 libevent 和 muduo。当然这些框架可能在上面的结构上稍微再加点东西,比如定时器,这样程序就变成了:
while (!m_bQuit) { //步骤一:检测是否有定时器到期并处理定时器事件 check_and_handle_timers(); //步骤二:使用select或者epoll_wait等IO复用技术检测socket上是否有读写或出错事件 // 对于第一个循环,只检测侦听socket是否有事件 epoll_or_select_func(); //步骤三:检测到某些socket上有事件后处理事件,比如收数据,对于第一个循环可能是 //接受客户端连接,接收完数据解数据包进行业务逻辑处理 handle_io_events(); //步骤四:做一些其他事情 handle_other_things(); } 之所以把定时器放在最前面是为了尽量减少定时器的事件的过期时间间隔。
说了这么多,希望你能理解:
- per thread per loop 思想
- 何时该用线程池
- 这个框架的优点与瓶颈所在
更具体的做法,您可以参考这里:
服务器端编程心得(一)-- 主线程与工作线程的分工
服务器端编程心得(二)-- Reactor模式
服务器端编程心得(三)-- 一个服务器程序的架构介绍
当然,如果您对网络编程或者高性能服务器开发感兴趣,可以关注我的微信公众号『CppGuide』与我进一步沟通交流~
有同学私信问我,你这些知识从哪里学习的呢?
如果你是网络编程零基础或者觉得自己网络编程存在夹生饭问题,推荐看看尹圣雨的《TCP/IP 网络编程》,这本书同时兼顾 Windows 和 Linux 两个平台,使用的是 C 语言和操作系统的 Socket API,通过这本书你能学会常用的操作系统 Socket API 和常用的网络模型,认真学完之后,你不会再纠结同步异步、阻塞非阻塞等概念。
TCP/IP 网络编程
链接: https:// pan.baidu.com/s/1ZeTJrX xbZfNNdYHT3NZmdw 提取码: ix4v
接着如果你想编写高性能的网络框架或者高效的服务,推荐游双老师的《Linux 高性能服务器编程》一书。
链接: https:// pan.baidu.com/s/1UaW_R5 NpTGr6b0nhSv3zhg 提取码: 11e9
这两本书的获取方式可以参见这里:
计算机必看经典书籍(含下载方式)
当然,我自己也出版了一本书《C++ 服务器开发精髓》,在这本书凝聚了我从客户端到服务器、从 Windows 到 Linux 的经验总结,你还将从本书中系统地学习到 C++ 开发编译调试完整技术链、多线程编程技术、作者精心凝炼的20多个网络编程重难点知识、网络故障排查与定位知识、如何设计可兼容可扩展的通信协议、如何设计高性能网络框架、如何设计高性能服务框架、如何开发服务常用组件等知识。
在 2021 年写一本 C++ 图书是一种什么体验?
在这里你可以了解:
- 为啥大家说的进程的意思有出入?
- 为啥并发那么难理解?
- 为啥高并发不仅仅是“高”+“并发”的意思?
- 为啥这些概念到了现实当中就不一样了?
假如你想铺一条长1000m,宽50m的路。为了解决这个问题,你先构想出来假如你自己1个人做,整个过程第一步干什么,第二步干什么等等。这个干活的过程,可以被称作一个【进程】(Process),或者你可以理解为“一个做事的办法/步骤/方案“。进程的英文Process本意就是“过程”的意思,是一个抽象的概念。这个活有没有真得干并不重要,重要的是你已经预先想好了这个活该怎么干,有了一个可行思路。注意,这里【进程】仅仅是描述这个方案的。至于这个方案是在脑海里,还是已经被执行了,是不重要的。
把这套铺路的方案用纸张写出来就得到一个【程序】。在软件开发中也是如此,只不过用的不是纸笔,而是键盘+存储器+某种编程语言。
当然,大家更加熟知的进程往往指的是另外一个意思,是指“程序在操作系统中运行的实例“。所谓“实例”是指同一个程序可以同时在操作系统里实际的运行。就像是如果你的铺路程序写好了,可以铺好几条路。每一个具体的铺路工作是一个“实例”。
所以wiki是这么给定义的:
In computing, a process is the instance of a computer program that is being executed by one or many threads.
见 https://en.wikipedia.org/wiki/Process_(computing)
为了避免混淆,我在下文中将操作系统的这个进程概念称为【OS进程】。而对上一节里面讲的“想办法”的进程称为【P进程】。
【OS进程】到底怎么实现呢?铺路的工作真的开干时,要不断记录买了什么料,已经花了多少钱,哪一块已经铺好了,哪一块刚铺完沥青得晾着等等。这些信息只有工作真的开干才会有。【OS进程】也是一样,因此比如Linux将进程实现为“task_struct",里面记录了CPU要完成这个工作的一整套数据。比如一个事情A,CPU没做完,被程序员要求做另外一件事情B。就得找个地方记录做了一半的A的那些数据,以便于CPU回过头来再做A时能够继续。
再次强调下,【P进程】和【OS进程】并不是一个意思,尽管会有一些关联。所以在阅读各种资料时一定要根据上下文分清楚进程到底是什么意思。我再总结下:
- 【P进程】指的是如何想明白做一件事情的过程。他用来帮助你理清做事的思路。这个事情做与没做,对于【P进程】这个概念不重要。
- 【OS进程】是指程序真的运行起来的实例,可以被实现为存放调度给CPU的任务和状态的数据结构。
软件设计里有一个经典的4 + 1 View,其中一个View叫做“Process View”,里面的Process就是指这里的【P进程】。“Process View”的目标就是“把怎么解决问题的方案说明白”。
上面wiki的定义指出一个【OS进程】是由一到多个【线程】组成。这里的【线程】(Thread)是一个抽象概念。
但在Linux中,【线程】是被实现为“轻量级进程”的。也就是说在Linux中的进程和线程实现的本质是一样的。只不过在以下2点上有显著区别:
- 在资源消耗上进程的消耗多,线程消耗相对少,以及;
- 内存空间上有一些不同:进程的虚拟内存彼此隔离,而线程则共享同一虚拟内存空间有些不同。
但Linux中【OS进程】和【线程】都用作任务调度单位。因此,Linux这种实现方式和理论上的概念不是很吻合,但是大量的程序已经跑在这个模式上了。而且大家早就已经习惯了。其他操作系统对【OS进程】和【线程】的实现会有所不同。如果碰到了不要惊讶。
【并发】(Concurrency)是由【P进程】引申出来的抽象概念。
上面说到了你可以假设自己一个人按照一定的步骤来铺路,一个人从头干到尾,这是一个“串行”的【P进程】。
但你也可以假设有2个人铺路。比如你可以按照长度分两半,一人铺500m * 50m;也可以按宽度划分,一人铺1000m * 25m;你还可以说让一个人负责铺全部路面的前5个步骤,另外一个人负责铺路面的余下5个步骤。然后你可以进一步想,假如不是雇2个人,而是雇20个人概如何分工呢?你可以混搭按长度,宽度,步骤等各种方式进行拆分。你甚至可以考虑这20个人不是完全一样的,有的能力强,有的能力弱,可以适当的调整工作量的比例等等。
不管怎样拆,都意味着你得到了【并发】的【P进程】。换成说人话就是,你有一套方案,可以让多个人一起把事情做的更高效。注意是“可以“让事情更高效,而不是“必然“让事情更高效。是不是更高效要看到底是怎么执行的,后边会讲。
举个写代码的例子,你有一个很长很长的数组,目标是把每一个数都*2。一个并发的做法就是把数组拆为很多个小段,然后每个小段的元素依次自己*2。这样的程序写出来就是一个【并发】的【程序】。这个程序如果运行起来就是【并发】的【OS进程】。
这时就会出现一个问题,当你想把一个【并发】的【P进程】写成程序时,你怎么用编程语言告诉操作系统你的程序的一些步骤是【并发】的。更确切地说,你需要一个写法(可能是语法,也可能是函数库)表达:
- 几个任务是【并发】的
- 【并发】的任务之间是怎么交互协作的
为了解决这两个问题,人们总结了一些方法,并将其称为“并发模型”。
比如:
- Fork & Join模型(大任务拆解为小任务并发的跑,结果再拼起来)
- Actor模型(干活的步骤之间直接发消息)
- CSP模型(干活的步骤之间订阅通话的频道来协作)
- 线程&锁模型(干活的人共享一个小本本,用来协作。注意小本本不能改乱套了,所以得加锁)
- ……
以Java中的线程为例,大家想表达【并发】就启动新的Thread(或者某种等价操作,如利用线程池);想让Thread之间交互,就要依靠共享内容。但是【并发】的Thread如果同时修改同一份数据就有可能出错(被称为竞争问题),为了解决这个问题就要引入锁(Lock,或者一些高级的同步工具,如CountdownLatch,Semaphore)。
特别强调下,Java的线程是表达并发的概念的类。这个类在绝大部分操作系统上使用操作系统内核中的【线程】实现。二者之间还是有一些细微的差异。即用开发者用Java Thread写代码表达思路,和操作系统调度线程执行是两个层面的事情。请努力认识到这一点。
再比如Erlang是基于Actor的并发模型(其实这是原教旨主义的OO)。那么就是每个参与【并发】的任务称为Process(又一个进程……,和【P进程】以及【OS进程都不太一样】,叫【E进程】好了,Erlang中的"进程“)。【E进程】之间通过消息来协作。每个【E进程】要不是在处理消息,要不就是在等新的消息。
如果你用go,那么表达并发的工具就是goroutine,goroutine之间协作要用channel。(当然也可以用Sync包加锁,不展开)。
对于并发模型《7周7并发模型》这本书讲的非常好。推荐阅读。书中展示了七种最经典的并发模型和大量的编码实例。
现在我们已经有了一个【并发】的想法,然后进入执行层面。
回到上面铺路的例子,你虽然假设有20个人可以一起干活。但你不一定真的能雇得到20个人。假如说你实际上最终只雇到1个人。但你有一个为20个人一起干活设计的方法。能不能用呢?当然能,只要让这个人先干第1人份的活,再干第2人份的……
但如果你真的雇了10个人,就可以很容易的让第1个人干第1人份和第2人份的活,第2个人干第3和第4人份的活…… 而这10个人同时在工地上干活,就是【并行】(Parallelism)。
在软件系统中,【程序】是否能【并行】运行,要看物理上有多少个CPU核心可以同时干活(或者再扩展一下,有多少台可用的物理主机)。
比如你写了个Java程序,同时启动了4个线程,但CPU只有单核,那么同一时刻只有一个线程在运行。如果有4个CPU核心,那么可以做到4个线程完全【并行】运行。如果有2个核心,那么就处于一种中间态。比如你可以用“并发度=4“,”并行度=2“形容这种情况。
把事情设计为【并发】有什么好处呢?假如能同时干活的人只有1个,其实并没有什么好处。【并发】的方法的总耗时总会>=串行的方法。因为【并发】或多或少总会引入需要协作和沟通成本。最小的代价就是不需要沟通,此时【并发】的方法和串行的方法工作量是一样的。
但是【并发】的巨大优势是在可以干活的人数量变多时,马上得到【并行】的好处。假如我们可以得到一个【并发】的【P进程】,并且真的为其配备足够多的人,那么做事的效率就会高很多。回到软件系统,假如有一个【并发】的【程序】,它在只有1个CPU的核心的机器上可以跑,在2个的CPU的也可以跑,在4核CPU上也可以跑。物理上可用CPU核心越多,程序能够越快执行完。而不管在哪里跑,程序本身不用做变化。编程是一件成本很高的事,能够做到程序不变而适应各种环境,可以极大的降低开发成本。你能想象下为1核心CPU开发的Office软件和4核心的不一样吗?
【并发】(Concurrency)这个词的本意是指两件事没有谁先谁后的关系,或者说关系不确定。举个通俗的例子,自然数任何两个数字都可以比较大小。我们可以明确地说5 > 3。但是如果换一个领域,并不是任何两个元素都有明确的顺序关系,或者说“谁在前面谁在后面都是可以的“。
对于任务执行这个领域,对于两个任务A和B,如果我们说他们俩是【并发】的,这就要求不能在任务B里使用A的结果,也不能让A执行时使用B的结果。因此在执行层面,A可以在B之前执行,也可以在B执行,或者A和B交替执行,或者A和B【并行】的执行。不管执行层面怎么折腾,结果都是对的。
反过来,如果A的执行需要B的结果,那也就意味着A和B不是【并发】的,必须让B先执行完,A才可以开始。在实现层面,就可以用加锁、channel等方式来表达“先B后A”。
Rob Pike在一个Talk里(https://blog.golang.org/concurrency-is-not-parallelism)提到了很重要的两个观点:
- Concurrency is not Parallelism
- Concurrency enables parallelism & makes parallelism (and scaling and everything else) easy
前一个观点【并发】和【并行】不是一件事,我们都可以理解了。【并发】说的是处理(Deal)的方法;【并行】说的是执行(Execution)的方法。
后一个观点指的是,如果想让一个事情变得容易【并行】,先得让制定一个【并发】的方法。倘若一个事情压根就没有【并发】的方法,那么无论有多少个可以干活的人,也不能【并行】。比如你让20个人不铺路,而是一起去拧同一个灯泡,也只能有一个人踩在梯子上去拧,其他19个人只能看着,啥也干不了。
对于一个问题,能不能找到【并发】的办法,取决于问题本身。有些问题很容易【并发】,有些问题可以一部分【并发】其余的串行(比如对数组排序就是,无论怎么拆,最终也要把每个拆开的问题结果合并到一起再排序才行),有些问题则根本上就不能【并发】。找不到【并发】的方法也就意味着不管有多少CPU核心,也没法【并行】执行。
换一个极端,假如为最多20个人设计了【并发】的方法,结果来了40个人,就意味着40人里有20个人是闲着的,是浪费。也就是说【并行】的上限是由【并发】的方法的设计决定的。这就解释了你吃鸡的时候,4核CPU和8核差别不大,因为这个游戏压根就没设计成可以利用这么多个CPU核心。(BTW,但游戏被设计为能充分利用显卡的多核心)
其实上面只是将CPU核心当作是“做事的人“,再广义一点,比如显卡,网卡,磁盘都是独立的可以干活的人。这些组件之间也可以并行的跑。因此,在设计程序的时候,可以比如把计算和IO任务拆开设计一个【并发】的方法,然后利用CPU和网卡是两个零件来【并行】的跑。
你可能看到过下面的论断:
并发是多个任务交替使用CPU,同一时刻只有一个任务在跑; 并行是多个任务同时跑
这个理解不能说全错,但是合到一起就形成了错误的理解。这个错误的理解就是:并发和并行是两个并列的,非此即彼的概念,一个状态要不就是并行的,要不就是并发的。这是完全错误的,实际上看到上面的解释你就会发现【并发】和【并行】描述的是两个频道的事情。正如Rob Pike所言,一个是“如何处理”,一个是“如何执行”。因此,对于:
并发是多个任务交替使用CPU,同一时刻只有一个任务在跑
其实正确的理解是:针对一个问题,想到了一个可以拆解为多个【并发】的任务,这些任务执行时因为只有一个CPU只能“切换”的跑。
对于:
并行是多个任务同时跑
其实的意思是:如果这些并行执行的任务是解决同一个问题的,那么他们既是【并发】的,同时也是【并行】的。
那么可不可以做到只【并行】,而不【并发】呢?当然可以,但这也就意味着【并行】的程序之间没有什么关联,各干各的,就像大街上来来往往的陌生人一样。这的确是【并行】,并且是这个世界的常态。但是一群不认识的,各干各的人是不能一起解决问题的,要一起就得有同一个目标,制定一套沟通的方法,形成【并发】的方案。这种形式在现实当中就是“公司”。
将并发理解为一种解决问题的方法,其主要用意是表达:一个问题的解决方案是可以由许许多多的并发任务组装(compose)到一起的。这有点像OOP里表达一个类可以由其他类的成员组装到一起一样。
将大的任务拆解为许许多多小的可以并发的任务是重要的编程思想。
比如当你在编写一个GET /user/:userId接口时,实际上底层要去3个地方取用户的基本信息(头像、昵称),活动的积分,当前已经下的订单,再组装到一起返回,用nodejs大概可以写成:
const userId = await doGetUserIdByToken(token); const [userBasic, userScore, userProcessingOrders] = await Promise.all([ // 并发执行下面3个任务 doGetUserBasic(userId), doGetUserScore(userId), doGetProcessingOrders(userId) ]); const user = {...userBasic, ...userScore, ...userProcessingOrders}; return user; 这段代码表达的就是这样的流程:
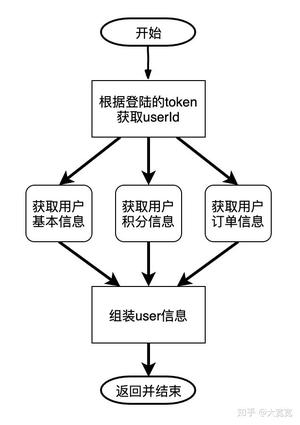
如果把一个并发任务以函数的方式去写就刚好把函数式编程(FP)与并发编程结合起来,就容易得到写起来很舒服,并且有利于并行执行的代码。这也是为什么很多FP语言都天然很适合做并发程序设计的原因。
我们做事的最终目标是1)能够得到正确的结果;2)能够尽量高效。高效有两个手段:一是优化做事的办法,这相当于改进算法,比如排序用快排而不是冒泡排序,这一点本文就不赘述了;另外一种方式就是让多个worker【并行】干。而为了【并行】,必须先得找到一个【并发】的方案。
我把这个思路的流程画成一张图供大家参考。
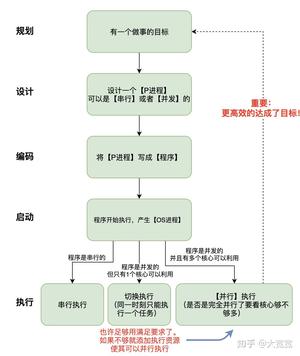
如果你理解了我在说什么就会发现,不管是写程序还是做任何事情,关键点是想到一个好的做事办法,一个可以Scale的,未来如果资源足够可以容易扩展到并行的办法。有了这个办法,具体怎么实施,用什么工具是次一级要考虑的问题。
最后再说说【高并发】。其实【高并发】的意思和前面说的【并发】的意思不止是差了一个“高”字,而是个宽泛得多的概念。【高并发】是指可以让软件系统在一段时间内能够处理大量的请求。比如每秒钟可以完成10万个请求。这是互联网系统的一个重要的特征。
不像【并发】说的是“处理”,【并行】说的是“执行”,【高并发】说的是最终效果。只要能达到效果,不管怎么实现都行。因此,极端一点【高并发】甚至并不一定需要【并行】,只要处理速度快的足够满足要求就可以。如启动一个nginx的【OS进程】,它只能用到一个CPU核心,也就不可能【并行】。但是他如果能每秒能处理10万个请求,而业务需求只要求8万个请求就可以了,那么这个单进程的nginx本身就算【高并发】了。
有时我面试别人的时候,对方简历上写做过高并发。仔细一问才发现只不过使用了nginx或者redis这种性能表现很好的系统实现功能。其实并没有做什么困难的工作。这样的同学写简历时一定要慎重,吹水是没有好结果滴。
当然,现实当中【高并发】的要求会相当“高“(双十一都刷过吧),说的也是完整的业务流程请求,而非简单的HTTP转发。这样的系统大量应用各种【并发】的集中人类智慧的各种方法,并尽可能的【并行】。
除了【并发】和【并行】,【高并发】还需要:
- 数据表普遍被分库分表,否则单机放不下,或者查询性能不足
- 解决分布式事务
- 因为机器都可能坏,为了保证少数机器坏掉不会影响处理的性能,必须引入HA机制
- 因为系统都有极限,超过极限响应能力就会急剧下降。因此必须引入限流的方案来保护系统
- 这么复杂的系统会涉及到N个service,N个存储,N个队列…… 这些资源的管理又成为了新的问题,这又需要对集群和服务做管理
- 这么多服务,肯定要解决分布式的Tracing和报警问题
- ……
当面试的时候提起【高并发】,大概率是希望面试者聊聊上面这些主题。但请特别特别留意,不同领域的【高并发】实际的意思(怎么算“高”,如何达成,哪些问题是关键问题)会非常不同。电商的高并发,抖音的高并发,12306卖火车票的高并发,基金交易系统的高并发,海量数据处理的高并发,这些问题其实都很不同。所以我很建议每次都讨论具体的问题,而非泛泛谈论【高并发】这个名词。
拓展一下,从商业上考虑【高并发】,其实际的意思是“用尽可能少的资源实现足够满足需要的并发请求数量,以形成竞争优势“。能用有限资源短时间内处理大量请求,也就意味着:
1)单个请求处理成本的降低。比如传统企业处理一单交易成本是10元,而互联网企业压低到了0.1元。这就形成了“规模经济下的低成本结构“,是一种碾压式的竞争优势。
2)提高转化效率。为了获客,市场部门都会拼命做如做拼团、发红包的工作。假设两家公司花同样的预算做获客。公司A的下单系统只能支持1000单/s;而B公司能做到成本不比A公司多很多的情况下实现10000单/s,那么过一段时间,A公司将被彻底打垮。如果你是老板,并且对用户需求很有信息,你会玩命砸技术投入,避免系统成为商业闭环的瓶颈(如果发生了,真坑啊)。
这也就是为啥有些公司突然火起来,然后玩命招技术人员。而做技术的同学能够有工作机会的原因。

但如果【高并发】并非是一个公司的商业闭环的关键问题。公司的商业价值是建立在客户关系之类的事情上,或者单笔交易金额比较大,没必要搞很多用户(比如卖保险)。就没有必要在技术上投入大量资源了。相反,聘请许多好的销售,公关人员才是更重要的。我想你一定看过房产中介公司每天早上喊口号对吧。因此,想要在技术上精进的同学最好也要避免去那些公司。不管在哪里做事情,一定要保证自己做的直接和商业价值挂钩的事情才能有更多机会成长。
恭喜你看到这里,因为你已经打败了世界上99%的用户。非常高兴你没有被讲懵逼。但为了验证一下你到底懂没懂,我这里有个问题,请不要打我:)
本文中到底提到了哪几种Process?分别都是什么意思?
答案:共3种
- 表示“做事方法”
- 操作系统里表示程序执行实例
- Erlang语言中的并发单元,彼此相互隔离,又俗称“Actor”
简单说下,有空细聊:
1.丢弃订单:最早期,量太大扛不住,直接前端随机reject一些,返回给抢单失败,简单粗暴,但是有效,比如10万人抢100个iPhone,只要能提前预测有大概1万以上的人参与(通过资格确认、报名等方式收集信息),那么直接请求进来以后随机挡回去99%的流量都没有啥问题。
2.优化吞吐:中间有段时间,提前准备一大批机器,服务化、分库分表搞定后端性能,让前端业务可以加一定量的机器,然后搞稳定性,依赖关系,容量规划,做弹性,提升吞吐量。
3.异步队列:然后就是使用可堆积的消息队列或者内存消息队列了,如果抢单具有强顺序,那么先都进队列,然后拿前N(就是库存数)个出来平滑处理,剩下的所有都可以作为失败进行批处理了,甚至还可以做一个定长的队列,再往里写直接提示失败。队列把并发变成串行,从而去掉了锁。
4.内存分配:一些具体的业务,也会考虑预热,提前在每个机器节点内存分配好库存数量,然后直接在内存里处理自己的库存数即可,这样可能也会在极端情况下啊,
5.独立部署:针对不同类型、不同商家、不同来源的商品,部署不同的前端促销集群,这样就把压力分散开了。具体到每个商家,其实量就不大了,双十一销售第一名的商家,并发也不是特别高。
6.服务降级:越重要的抢单,大家越关心自己有没有抢到,而不是特别在意订单立即处理完,也就是说,下单占到位置比处理完成订单要更有价值。比如12306春运抢票,只要告诉用户你抢到了票,但是预计1个小时后订单才会处理完,用户有这个明确预期,就可以了,用户不会立马使用这张票,也不会在意1分钟内处理完还是1小时处理完。
需要注意的是其中部分模式会导致销售不足或者超卖,销售不足可以从抢购里加一些名单补发,也可以加一轮秒杀。超卖比较麻烦,所以一般会多备一点货,比如抢100个iPhone,提前准备105个之类的,也会证明在实际操作里非常有价值。
python的多线程还是不建议用的, 要高并发的话, 多进程 + 协程的组合的并发性能远高于多线程。我在这篇文章中对python的并发方案有过比较。 像你是要发各种请求的,其实和爬虫类似, 协程的方案比较合适,能达到很高的并发。
大龙:Python高效爬虫方案总结
同时,我在这篇文章中解释过python多线程为什么不能带来很好性能的原因:
大龙:Python线程、协程探究(1)——Python的多线程困境
在这篇文章中介绍过Python的协程调度的原理:
大龙:Python线程、协程探究(3)——协程的调度实现
最后,感兴趣的话, 可以关注我的专栏~
一亩三分地
对于高并发秒杀、抽奖之类的业务,任何提到数据库、xx锁、redis等关键词的回答都是在扯淡。
我之所以戾气这么重,是因为有太多团队、尝试了太多牛逼哄哄的技术方案,最后终于返璞归真地发现,最高效的方案恰恰是最简单、最没技术含量的那个。
不信?我们来试试:
1亿用户,在1秒钟内秒杀1个商品。
够“大数据”、“高并发”了吧?
把这1亿个用户id在塞进内存排成一个内存队列,取前100个id(排队模式,先到先得)、或者随机取100个id(抽签模式,绝对公平),剩下的直接丢弃。最终在1亿人中抢到商品的那个锦鲤用户,就在这100个id中产生。1秒后,把商品在内存中标记为“售罄”,如果后面还有进来秒杀的散户,直接无视。
现在,1亿并发的问题变成了100并发的问题——没人会问这个100人的秒杀功能怎么实现了吧?
用这个方案,用户点下秒杀按钮后,会感觉到1秒的延迟——可以接受;
用户在1秒后就会知道自己到底有没有秒杀成功——很好;
服务器端没有什么大数据计算,只需在内存中存下1亿个用户id即可。每个用户id算10字节,1亿个id只占用1G内存——很好;
数据库根本不存在1亿次操作,连100次都不一定有——很好;
1亿用户id集中到一台服务器抽签,每人抽中的概率完全均等,全过程可回溯。如果实际来的用户数量少于预期,比如只来了100万人、甚至100人,也不会出问题,最终总能产生一个幸运用户喜提商品——很好,比那些在前端写死秒杀成功率=1亿分之一的耍猴方案厚道多了。
这样做,不仅可以实现1亿并发的秒杀业务,而且只需1台普通办公电脑的性能。
我估计会有人说(果然有人说):1秒内1亿次网络请求,这得什么样的服务器架构能扛得住啊?1台普通电脑怎么可能?肯定得用上集群、分布式、CDN、……
是的——但问题在于,这些并不是秒杀特需的资源。就算不搞秒杀,一个1秒内能拥上来1亿用户的的电商网站,每天怎么着也得有个10~100亿人在上面转悠,分布式、CDN难道不是标配吗?
业务量这么大的公司,花点钱买内存条吧,每秒钟同时进行几百次秒杀毫无压力,没事就别折腾程序猿的脑细胞了。
最后以一个虽然是编的(没错,就是段子)、却广为流传的苏联笑话结尾:
美苏争霸时期,美国宇航员被一个问题深深困扰:圆珠笔在太空零重力环境下,写不出字。为了提高宇航员生活质量,彰显大国科技实力,NASA投入巨资、耗费10年研发太空版圆珠笔,最后仍以失败告终。
冷战结束后,美国人很好奇,苏联人是怎么解决这个问题的?
结果两边的宇航员一碰头,双方都惊呆了——
苏联人用的是铅笔。
下面统一回复评论区:
别瞎扯了好吗?铅笔那就是个段子而已。太空无重力环境下,不能有粉尘。
就是段子啊,文中已经说了“虽然是编的”啊……好吧,为了不被反复扣上误导读者的帽子,特此声明:各国宇航员实际用的不是铅笔,而是太空版圆珠笔。
如果那100个用户没有来秒杀,另外的那接近1亿的用户怎么秒杀都不成功,这猴耍的666
如果你觉得100人的最终付款比例连1/100都不到,那就放宽到取1千、1万、10万个用户id,直到你满意为止。实际上,电商行业早已有成熟的漏斗模型,100人的最终付款比例是一个明确的统计数字,不用瞎猜。
假如非要杠到底:1亿用户中也不一定有1个人最终付款呢?难道取1亿个用户id吗?
好吧,要真是这样,那反倒好办了——1亿人中压根没有一个人想付钱,买方、卖方互相耍猴,还要程序猿来凑什么热闹?前端做个假按钮,点后提示下次再来、领券、加购三连不就行了?
1台服务器扛不住1亿请求,服务器集群后,如果不借助redis,又怎么保证秒杀不超卖?业务服务器相互独立,内存数据不共享,A业务服务器如何在秒杀成功后及时通知B,C...服务器商品已卖出?很多简单的问题,分布式分布式部署后都不简单。
文中已经说了:“就算不搞秒杀,一个1秒内能拥上来1亿用户的的电商网站,每天怎么着也得有个10~100亿人在上面转悠,分布式、CDN难道不是标配吗?”
1台服务器确实扛不住每秒1亿的请求。但我们讨论高并发秒杀的前提是:这个网站已经有足够的能力来应付日常的高并发访问了,只是扛不住、也没必要耗费数百倍的资源来扛住秒杀带来的瞬间超高并发而已。一个1亿人秒杀的超大型电商网站,如果不搞秒杀,平时一般业务不需要集群?不需要杜绝超卖?不需要解决分布式数据同步问题?如果这些问题早已解决了,做秒杀的人何必把它们重新解决一遍?如果这些问题都没解决,正常访问都会卡死,还有心思玩什么秒杀?
本文核心思路是,在保证业务逻辑不变的前提下,把100台服务器都扛不住的问题简化为1台服务器都能轻松扛住的问题。处理秒杀的服务器(简称“秒杀机”)只有1台,它本身不存在“业务服务器相互独立、内存数据不共享”,“相互独立”的是处理网络请求的服务器,每台服务器独立取一部分用户id即可。
具体来说:假设1亿请求通过分布在全国各地的100台服务器(简称CDN,但不是真正的CDN,而是接在CDN后面的分布式业务服务器)来负载,每个CDN从100万请求中挑出1个用户id,汇总到秒杀机的id还是100个。1秒后,秒杀机把商品在本地内存中标记为“售罄”,所有CDN通过网络同步一下秒杀机内存中的状态“售罄”,最多只需要几百毫秒,100台CDN都知道商品卖完了。这样是不是解决了“A业务服务器如何在秒杀成功后及时通知B,C...服务器商品已卖出?”
有多少商品,就放多少请求入队列。一个商品你放100个请求进去干啥?要超卖吗?防止少卖是用延迟队列或定时任务,15分钟没付款时,取消并重新回库。
1个商品放100个、而不是1个请求进去,是因为那100人不一定都会付款。这100人进入结算页,谁第一个把钱付掉,货就归谁;谁动作慢了一步,提示“秒杀结束,付款失败”。这种机制下不会出现超卖,不会出现1人喜提商品而99人被迫退款,因为点下支付按钮的一瞬间先检查实时库存是否“售罄”,然后再决定是否发送支付接口。手速慢的99人连支付请求都没发出就被拦截掉了。
“防止少卖是用延迟队列或定时任务,15分钟没付款时,取消并重新回库”,这种方法适用于一般情况下的购物,不适合秒杀。
想一想,如果只放1个请求进去,一旦这位用户占着茅坑不拉X,在15分钟内,剩下的1亿-1人会看到什么?
A. 显示“秒杀已结束”?万一他最终没有付款,这1个商品岂不是卖不掉了?
B. 显示“茅坑正被人占用,如果他在15分钟内都没拉出X,系统将从剩余的1亿-1人中抽取一位幸运用户接着上”?你确定不会被围观的1亿-1个用户打死?
放100个请求进去付款,先付先得,不仅符合技术,而且符合人性。想想看,如果付款时系统友情提示一下“除你之外,还有99人正在付款,先付先得哦”,是不是剁起手来顿时就不纠结了?
点付款按钮后,再点取消怎么办?或者余额不足,或者刚好用户断网!整个付款过程是你无法控制的!建议你实战演练一下
好问题,值得细说一番。
你所说的“付款过程无法控制”的前提是使用第三方支付,比如普通商户接支付宝接口。一旦从电商平台跳转到支付宝的网站/APP,电商就无法干预了。如果用户A先进入结算页,然后在支付宝里纠结半天,结果后来者B果断把钱付了,等到A付款后就会造成超卖,电商明知没货了也无法实时中止支付宝内的交易。
但是,这里的预设前提可是1亿人同时秒杀的巨头电商啊,如此体量的平台一般会主推自有支付体系(余额/花呗/白条),再次也是自己能控制的合作渠道,所以能在扣款前检查库存并中止交易。他们绝不可能像普通商户一样去接自己无法控制的第三方支付,否则就等于把客户信息拱手相送——这就是为什么京东不让你用支付宝的原因。
如果非要用无法控制的第三方支付,那么在理论上,少卖、超卖两者必居其一,哪怕只有2个人抢1个商品也是如此:
如果在A拍下商品(暂未付款)后锁库存,令B无法购买,结果最后A没付款 => 少卖;
如果拍下后不锁库存,结果两人都付了款 => 超卖。
当然,在真实的商业中,少卖和超卖再正常不过,有的是办法用非技术手段应对。要知道,秒杀100个手机,并不是只卖掉99个就不行,也不是仓库里真就拿不出第101个。不过,从纯技术上讲,只要用了“无法控制”的第三方支付,少卖和超卖的可能性就无法消除了。
预设的场景确实没有太大挑战,一亿请求量100成功量基本没有业务价值,这不叫秒杀叫抽奖。正常场景是一亿请求量秒杀窗口内一百万成功或者一千万成功。100到100万的质变,还能简单粗暴的解决吗?
能。
来,1亿用户在1秒钟内秒杀1000万个商品,简单粗暴地解决给你看。
现在是1/10的中奖概率,1亿个用户id中取出1000万个(排队模式或抽签模式),或者100台处理流量的服务器每台从100万个用户id中抽出10万个汇总到秒杀机。这1000万个锦鲤用户允许进入结算页。因为商品库存也是1000万个,所以不可能超卖,也没必要在数据库里锁库存,让1000万人把钱付掉即可。结束。
啥?你说1000万用户不一定都付款?只有500万人付款怎么办?
很简单啊!既然生意这么好做,500万商品能在1秒内卖光,下次再搞个秒杀,再花个1秒钟把剩下的500万库存卖掉不就行了?
事实上,我很疑惑的是,“正常场景是一亿请求量秒杀窗口内一百万成功或者一千万成功”,是真的吗?京东天天有“限时秒杀”,其实只是限时降价促销而已;淘宝双十一流量确实恐怖,但那是集中在几天,不一定非要集结1亿人在1秒钟内干爆自己的服务器;小米引以为豪的饥饿营销,其辉煌战绩也就是100万人在1分钟内抢购10万个手机。1亿人1秒钟秒杀1000万商品,到底是什么样的“正常场景”?
从商业逻辑上讲,没有哪个老板希望秒杀的商品库存越多越好(打着“秒杀”幌子的降价促销不算),因为秒杀本质上是“赔本赚吆喝”。所以,要么1亿人秒杀100个手机,要么100万人秒杀10万个手机,但不会出现1亿人秒杀1000万个手机。如果今天1秒钟就把1000万手机以远低于市场价的价格“秒”掉了,把原本有限的市场需求一次性满足了,那接下来咱还干啥呢?
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:艾小仙
链接: 修正版 | 面对千万级、亿级流量怎么处理?
来源:微信公众号
把这个甩给他就完了。
让我们开始吧!
面对业务急剧增长你怎么处理?
业务量增长10倍、100倍怎么处理?
你们系统怎么支撑高并发的?
怎么设计一个高并发系统?
高并发系统都有什么特点?
... ...
诸如此类,问法很多,但是面试这种类型的问题,看着很难无处下手,但是我们可以有一个常规的思路去回答,就是围绕支撑高并发的业务场景怎么设计系统才合理?如果你能想到这一点,那接下来我们就可以围绕硬件和软件层面怎么支撑高并发这个话题去阐述了。本质上,这个问题就是综合考验你对各个细节是否知道怎么处理,是否有经验处理过而已。
面对超高的并发,首先硬件层面机器要能扛得住,其次架构设计做好微服务的拆分,代码层面各种缓存、削峰、解耦等等问题要处理好,数据库层面做好读写分离、分库分表,稳定性方面要保证有监控,熔断限流降级该有的必须要有,发生问题能及时发现处理。这样从整个系统设计方面就会有一个初步的概念。
在互联网早期的时候,单体架构就足以支撑起日常的业务需求,大家的所有业务服务都在一个项目里,部署在一台物理机器上。所有的业务包括你的交易系统、会员信息、库存、商品等等都夹杂在一起,当流量一旦起来之后,单体架构的问题就暴露出来了,机器挂了所有的业务全部无法使用了。
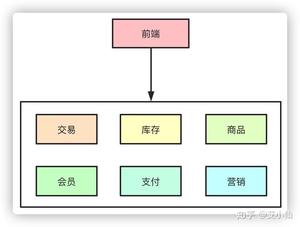
于是,集群架构的架构开始出现,单机无法抗住的压力,最简单的办法就是水平拓展横向扩容了,这样,通过负载均衡把压力流量分摊到不同的机器上,暂时是解决了单点导致服务不可用的问题。
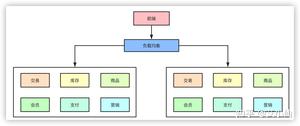
但是随着业务的发展,在一个项目里维护所有的业务场景使开发和代码维护变得越来越困难,一个简单的需求改动都需要发布整个服务,代码的合并冲突也会变得越来越频繁,同时线上故障出现的可能性越大。微服务的架构模式就诞生了。
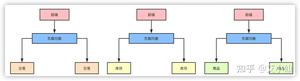
把每个独立的业务拆分开独立部署,开发和维护的成本降低,集群能承受的压力也提高了,再也不会出现一个小小的改动点需要牵一发而动全身了。
以上的点从高并发的角度而言,似乎都可以归类为通过服务拆分和集群物理机器的扩展提高了整体的系统抗压能力,那么,随之拆分而带来的问题也就是高并发系统需要解决的问题。
微服务化的拆分带来的好处和便利性是显而易见的,但是与此同时各个微服务之间的通信就需要考虑了。
对于SOA、微服务化的架构而言,就对部署、运维、服务治理、链路追踪等等有了更高的要求。
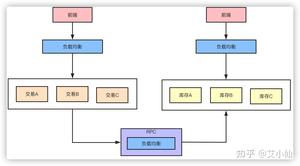
基于此,无论选用何种框架Spring Cloud、Spring Cloud Alibaba、Dubbo、Thrift、gRpc其实都一样。
于现在国内的技术栈选择来说,大厂基本都是自研,中小厂更多采用如Dubbo这类框架,现在来说,Spring Cloud Alibaba应该是未来一段时间的主流方向。
但是无论使用何种框架,一些基本原理都是应该了解的。此处以Dubbo举例。
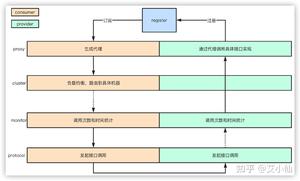
- 服务启动的时候,provider和consumer根据配置信息,连接到注册中心register,分别向注册中心注册和订阅服务
- register根据服务订阅关系,返回provider信息到consumer,同时consumer会把provider信息缓存到本地。如果信息有变更,consumer会收到来自register的推送
- consumer生成代理对象,同时根据负载均衡策略,选择一台provider,同时定时向monitor记录接口的调用次数和时间信息
- 拿到代理对象之后,consumer通过代理对象发起接口调用
- provider收到请求后对数据进行反序列化,然后通过代理调用具体的接口实现
- 加权随机:假设我们有一组服务器 servers = [A, B, C],他们对应的权重为 weights = [5, 3, 2],权重总和为10。现在把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上就可以了。
- 最小活跃数:每个服务提供者对应一个活跃数 active,初始情况下,所有服务提供者活跃数均为0。每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求。
- 一致性hash:通过hash算法,把provider的invoke和随机节点生成hash,并将这个 hash 投射到 [0, 2^32 - 1] 的圆环上,查询的时候根据key进行md5然后进行hash,得到第一个节点的值大于等于当前hash的invoker。
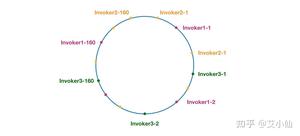
- 加权轮询:比如服务器 A、B、C 权重比为 5:2:1,那么在8次请求中,服务器 A 将收到其中的5次请求,服务器 B 会收到其中的2次请求,服务器 C 则收到其中的1次请求。
- Failover Cluster失败自动切换:dubbo的默认容错方案,当调用失败时自动切换到其他可用的节点,具体的重试次数和间隔时间可用通过引用服务的时候配置,默认重试次数为1也就是只调用一次。
- Failback Cluster快速失败:在调用失败,记录日志和调用信息,然后返回空结果给consumer,并且通过定时任务每隔5秒对失败的调用进行重试
- Failfast Cluster失败自动恢复:只会调用一次,失败后立刻抛出异常
- Failsafe Cluster失败安全:调用出现异常,记录日志不抛出,返回空结果
- Forking Cluster并行调用多个服务提供者:通过线程池创建多个线程,并发调用多个provider,结果保存到阻塞队列,只要有一个provider成功返回了结果,就会立刻返回结果
- Broadcast Cluster广播模式:逐个调用每个provider,如果其中一台报错,在循环调用结束后,抛出异常。
对于MQ的作用大家都应该很了解了,削峰填谷、解耦。依赖消息队列,同步转异步的方式,可以降低微服务之间的耦合。
对于一些不需要同步执行的接口,可以通过引入消息队列的方式异步执行以提高接口响应时间。在交易完成之后需要扣库存,然后可能需要给会员发放积分,本质上,发积分的动作应该属于履约服务,对实时性的要求也不高,我们只要保证最终一致性也就是能履约成功就行了。对于这种同类性质的请求就可以走MQ异步,也就提高了系统抗压能力了。
对于消息队列而言,怎么在使用的时候保证消息的可靠性、不丢失?
消息丢失可能发生在生产者发送消息、MQ本身丢失消息、消费者丢失消息3个方面。
生产者丢失
生产者丢失消息的可能点在于程序发送失败抛异常了没有重试处理,或者发送的过程成功但是过程中网络闪断MQ没收到,消息就丢失了。
由于同步发送的一般不会出现这样使用方式,所以我们就不考虑同步发送的问题,我们基于异步发送的场景来说。
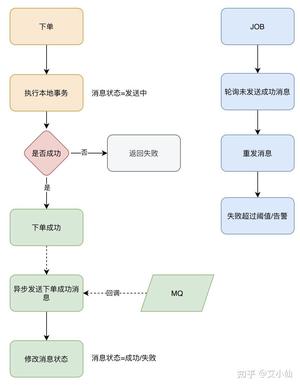
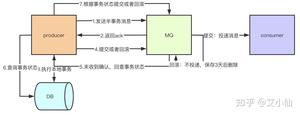
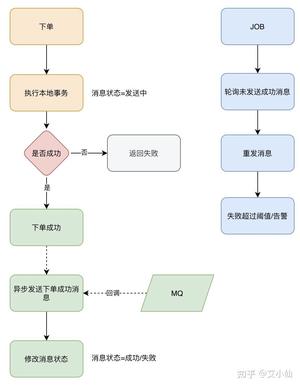
异步发送分为两个方式:异步有回调和异步无回调,无回调的方式,生产者发送完后不管结果可能就会造成消息丢失,而通过异步发送+回调通知+本地消息表的形式我们就可以做出一个解决方案。以下单的场景举例。
- 下单后先保存本地数据和MQ消息表,这时候消息的状态是发送中,如果本地事务失败,那么下单失败,事务回滚。
- 下单成功,直接返回客户端成功,异步发送MQ消息
- MQ回调通知消息发送结果,对应更新数据库MQ发送状态
- JOB轮询超过一定时间(时间根据业务配置)还未发送成功的消息去重试
- 在监控平台配置或者JOB程序处理超过一定次数一直发送不成功的消息,告警,人工介入。
一般而言,对于大部分场景来说异步回调的形式就可以了,只有那种需要完全保证不能丢失消息的场景我们做一套完整的解决方案。
MQ丢失
如果生产者保证消息发送到MQ,而MQ收到消息后还在内存中,这时候宕机了又没来得及同步给从节点,就有可能导致消息丢失。
比如RocketMQ:
RocketMQ分为同步刷盘和异步刷盘两种方式,默认的是异步刷盘,就有可能导致消息还未刷到硬盘上就丢失了,可以通过设置为同步刷盘的方式来保证消息可靠性,这样即使MQ挂了,恢复的时候也可以从磁盘中去恢复消息。
比如Kafka也可以通过配置做到:
acks=all 只有参与复制的所有节点全部收到消息,才返回生产者成功。这样的话除非所有的节点都挂了,消息才会丢失。 replication.factor=N,设置大于1的数,这会要求每个partion至少有2个副本 min.insync.replicas=N,设置大于1的数,这会要求leader至少感知到一个follower还保持着连接 retries=N,设置一个非常大的值,让生产者发送失败一直重试 虽然我们可以通过配置的方式来达到MQ本身高可用的目的,但是都对性能有损耗,怎样配置需要根据业务做出权衡。
消费者丢失
消费者丢失消息的场景:消费者刚收到消息,此时服务器宕机,MQ认为消费者已经消费,不会重复发送消息,消息丢失。
RocketMQ默认是需要消费者回复ack确认,而kafka需要手动开启配置关闭自动offset。
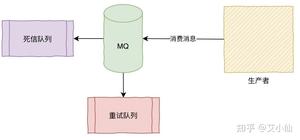
消费方不返回ack确认,重发的机制根据MQ类型的不同发送时间间隔、次数都不尽相同,如果重试超过次数之后会进入死信队列,需要手工来处理了。(Kafka没有这些)
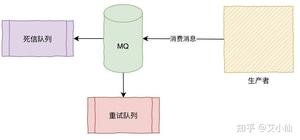
事务消息可以达到分布式事务的最终一致性,事务消息就是MQ提供的类似XA的分布式事务能力。
半事务消息就是MQ收到了生产者的消息,但是没有收到二次确认,不能投递的消息。
实现原理如下:
- 生产者先发送一条半事务消息到MQ
- MQ收到消息后返回ack确认
- 生产者开始执行本地事务
- 如果事务执行成功发送commit到MQ,失败发送rollback
- 如果MQ长时间未收到生产者的二次确认commit或者rollback,MQ对生产者发起消息回查
- 生产者查询事务执行最终状态
- 根据查询事务状态再次提交二次确认
最终,如果MQ收到二次确认commit,就可以把消息投递给消费者,反之如果是rollback,消息会保存下来并且在3天后被删除。
对于整个系统而言,最终所有的流量的查询和写入都落在数据库上,数据库是支撑系统高并发能力的核心。怎么降低数据库的压力,提升数据库的性能是支撑高并发的基石。主要的方式就是通过读写分离和分库分表来解决这个问题。
对于整个系统而言,流量应该是一个漏斗的形式。比如我们的日活用户DAU有20万,实际可能每天来到提单页的用户只有3万QPS,最终转化到下单支付成功的QPS只有1万。那么对于系统来说读是大于写的,这时候可以通过读写分离的方式来降低数据库的压力。
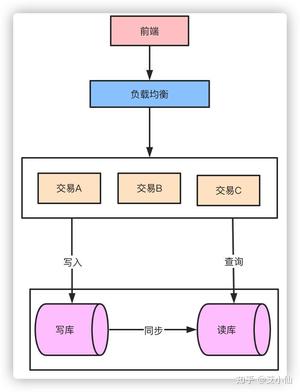
读写分离也就相当于数据库集群的方式降低了单节点的压力。而面对数据的急剧增长,原来的单库单表的存储方式已经无法支撑整个业务的发展,这时候就需要对数据库进行分库分表了。针对微服务而言垂直的分库本身已经是做过的,剩下大部分都是分表的方案了。
首先根据业务场景来决定使用什么字段作为分表字段(sharding_key),比如我们现在日订单1000万,我们大部分的场景来源于C端,我们可以用user_id作为sharding_key,数据查询支持到最近3个月的订单,超过3个月的做归档处理,那么3个月的数据量就是9亿,可以分1024张表,那么每张表的数据大概就在100万左右。
比如用户id为100,那我们都经过hash(100),然后对1024取模,就可以落到对应的表上了。
因为我们主键默认都是自增的,那么分表之后的主键在不同表就肯定会有冲突了。有几个办法考虑:
- 设定步长,比如1-1024张表我们分别设定1-1024的基础步长,这样主键落到不同的表就不会冲突了。
- 分布式ID,自己实现一套分布式ID生成算法或者使用开源的比如雪花算法这种
- 分表后不使用主键作为查询依据,而是每张表单独新增一个字段作为唯一主键使用,比如订单表订单号是唯一的,不管最终落在哪张表都基于订单号作为查询依据,更新也一样。
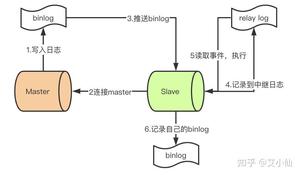
- master提交完事务后,写入binlog
- slave连接到master,获取binlog
- master创建dump线程,推送binglog到slave
- slave启动一个IO线程读取同步过来的master的binlog,记录到relay log中继日志中
- slave再开启一个sql线程读取relay log事件并在slave执行,完成同步
- slave记录自己的binglog
由于mysql默认的复制方式是异步的,主库把日志发送给从库后不关心从库是否已经处理,这样会产生一个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,日志就丢失了。由此产生两个概念。
全同步复制
主库写入binlog后强制同步日志到从库,所有的从库都执行完成后才返回给客户端,但是很显然这个方式的话性能会受到严重影响。
半同步复制
和全同步不同的是,半同步复制的逻辑是这样,从库写入日志成功后返回ACK确认给主库,主库收到至少一个从库的确认就认为写操作完成。
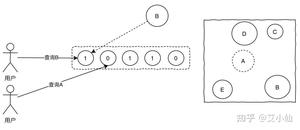
缓存作为高性能的代表,在某些特殊业务可能承担90%以上的热点流量。对于一些活动比如秒杀这种并发QPS可能几十万的场景,引入缓存事先预热可以大幅降低对数据库的压力,10万的QPS对于单机的数据库来说可能就挂了,但是对于如redis这样的缓存来说就完全不是问题。
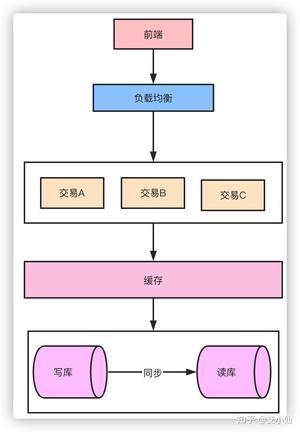
以秒杀系统举例,活动预热商品信息可以提前缓存提供查询服务,活动库存数据可以提前缓存,下单流程可以完全走缓存扣减,秒杀结束后再异步写入数据库,数据库承担的压力就小的太多了。当然,引入缓存之后就还要考虑缓存击穿、雪崩、热点一系列的问题了。
所谓热key问题就是,突然有几十万的请求去访问redis上的某个特定key,那么这样会造成流量过于集中,达到物理网卡上限,从而导致这台redis的服务器宕机引发雪崩。
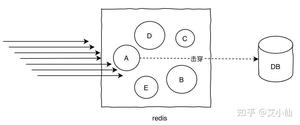
针对热key的解决方案:
- 提前把热key打散到不同的服务器,降低压力
- 加入二级缓存,提前加载热key数据到内存中,如果redis宕机,走内存查询
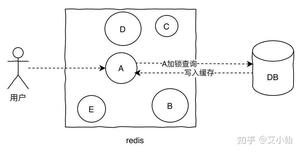
缓存击穿的概念就是单个key并发访问过高,过期时导致所有请求直接打到db上,这个和热key的问题比较类似,只是说的点在于过期导致请求全部打到DB上而已。
解决方案:
- 加锁更新,比如请求查询A,发现缓存中没有,对A这个key加锁,同时去数据库查询数据,写入缓存,再返回给用户,这样后面的请求就可以从缓存中拿到数据了。
- 将过期时间组合写在value中,通过异步的方式不断的刷新过期时间,防止此类现象。
缓存穿透是指查询不存在缓存中的数据,每次请求都会打到DB,就像缓存不存在一样。
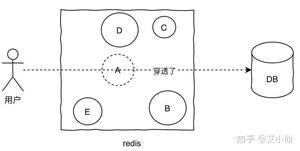
针对这个问题,加一层布隆过滤器。布隆过滤器的原理是在你存入数据的时候,会通过散列函数将它映射为一个位数组中的K个点,同时把他们置为1。
这样当用户再次来查询A,而A在布隆过滤器值为0,直接返回,就不会产生击穿请求打到DB了。
显然,使用布隆过滤器之后会有一个问题就是误判,因为它本身是一个数组,可能会有多个值落到同一个位置,那么理论上来说只要我们的数组长度够长,误判的概率就会越低,这种问题就根据实际情况来就好了。
当某一时刻发生大规模的缓存失效的情况,比如你的缓存服务宕机了,会有大量的请求进来直接打到DB上,这样可能导致整个系统的崩溃,称为雪崩。雪崩和击穿、热key的问题不太一样的是,他是指大规模的缓存都过期失效了。
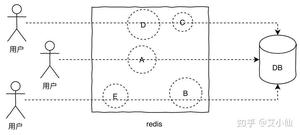
针对雪崩几个解决方案:
- 针对不同key设置不同的过期时间,避免同时过期
- 限流,如果redis宕机,可以限流,避免同时刻大量请求打崩DB
- 二级缓存,同热key的方案。
熔断
比如营销服务挂了或者接口大量超时的异常情况,不能影响下单的主链路,涉及到积分的扣减一些操作可以在事后做补救。
限流
对突发如大促秒杀类的高并发,如果一些接口不做限流处理,可能直接就把服务打挂了,针对每个接口的压测性能的评估做出合适的限流尤为重要。
降级
熔断之后实际上可以说就是降级的一种,以熔断的举例来说营销接口熔断之后降级方案就是短时间内不再调用营销的服务,等到营销恢复之后再调用。
预案
一般来说,就算是有统一配置中心,在业务的高峰期也是不允许做出任何的变更的,但是通过配置合理的预案可以在紧急的时候做一些修改。
核对
针对各种分布式系统产生的分布式事务一致性或者受到攻击导致的数据异常,非常需要核对平台来做最后的兜底的数据验证。比如下游支付系统和订单系统的金额做核对是否正确,如果收到中间人攻击落库的数据是否保证正确性。
其实可以看到,怎么设计高并发系统这个问题本身他是不难的,无非是基于你知道的知识点,从物理硬件层面到软件的架构、代码层面的优化,使用什么中间件来不断提高系统的抗压能力。但是这个问题本身会带来更多的问题,微服务本身的拆分带来了分布式事务的问题,http、RPC框架的使用带来了通信效率、路由、容错的问题,MQ的引入带来了消息丢失、积压、事务消息、顺序消息的问题,缓存的引入又会带来一致性、雪崩、击穿的问题,数据库的读写分离、分库分表又会带来主从同步延迟、分布式ID、事务一致性的问题,而为了解决这些问题我们又要不断的加入各种措施熔断、限流、降级、离线核对、预案处理等等来防止和追溯这些问题。
- END -
面试官:面对千万级、亿级流量怎么处理?
现实中,哪怕是大公司,高并发系统也是可遇不可求的。不过,高并发其实是可以通过压测来模拟的。
高并发的背后,核心是高可用和低延迟。所以我们其实是想有能力设计一个系统,在高并发访问的时候,系统依然可用,而且响应速度不会变慢。
(点击头像关注我们账号,别错过更多阿里工程师一线技术干货)
————————————————————————————————————————
想提升高并发系统的设计和开发能力,有2个方面:
一个是系统的学习相关理论;
一个是找一个目标系统,不断想办法去提升他的性能。
前者是后者的理论基础。
如果想从事一个高并发系统开发的岗位,要学习的相关技术其实是很多的,这些技术核心就是解决高并发情况下如何保持系统的高可用和低延迟。
以Java工程师为例,互联网程序员面试中经常会考察的内容包括:
(1) 架构设计:
高可用与稳定性、事务一致性、多副本一致性、CAP理论。
(2) 相关技术:
多线程(JUC/AQS/线程池)、RPC调用及框架(如Thrift)、NIO及NIO框架(如Netty)、高并发框架(如Disruptor) 、微服务框架(SpringBoot)、微服务治理(Spring Cloud)、数据库相关技术(如:索引优化、分库分表、读写分离)、分布式缓存(如redis)、消息中间件系统(如RabbitMQ)、容器技术(如docker)。
(3) 工具:
系统性能查看(top、uptime、vmstat、iostat)、压测工具(如ab、locust、Jmeter、go)、线程分析(如jps、jstack)等。
当然,一开始,我们不可能逐一把这些技能全部掌握,我们可以从一个实际项目入手,不断的把这些技术用上去,发现哪些知识不足,再去补充相关的知识。
“如何设计一个好的秒杀系统“,一定是互联网大厂面试中最常问的一个问题。所以从设计一个秒杀系统开始实践,是个不错的选择。
(1)瞬时并发量大
秒杀时会有大量用户在同一时间进行抢购,瞬时并发访问量突增 10 倍,甚至 100 倍以上都有。
(2)库存量少
一般秒杀活动商品量很少,这就导致了只有极少量用户能成功购买到。
(3)业务简单
流程比较简单,一般都是下订单、扣库存、支付订单。
(1)限流
由于活动库存量一般都是很少,对应的只有少部分用户才能秒杀成功。所以我们需要限制大部分用户流量,只准少量用户流量进入后端服务器。
(2)削峰
秒杀开始的那一瞬间,会有大量用户冲击进来,所以在开始时候会有一个瞬间流量峰值。如何把瞬间的流量峰值变得更平缓,是能否成功设计好秒杀系统的关键因素。实现流量削峰填谷,一般的采用缓存和 MQ 中间件来解决。
(3)异步
秒杀其实可以当做高并发系统来处理,在这个时候,可以考虑从业务上做兼容,将同步的业务,设计成异步处理的任务,提高网站的整体可用性。
(4)缓存
秒杀系统的瓶颈主要体现在下订单、扣减库存流程中。在这些流程中主要用到 OLTP 的数据库,类似 MySQL、Oracle。由于数据库底层采用 B+ 树的储存结构,对应我们随机写入与读取的效率,相对较低。如果我们把部分业务逻辑迁移到内存的缓存或者 Redis 中,会极大的提高并发效率。
从0到1搭建一个秒杀系统,也并不容易,涉及到很多前端、后端、中间件的技术。这个跟其实是所有公司的工作常态,大部分时间也是在搭架子,真正做技术优化的时间并不多,经常是在业务量突增或者大促活动来临时,集中搞一波性能优化。
所以,如果没有实际的高并发项目可做,自己弄个秒杀系统自娱自乐也是不错的。
搭建系统 -> 压测 -> 发现问题 -> 学习知识 -> 优化系统,通过这样的循环,相信你一定既能体验到学习的乐趣,同时实力也大幅提升。
(淘系技术部-产品技术-昭明)
————————————————————————————————————————
阿里巴巴集团淘系技术部官方账号。淘系技术部是阿里巴巴新零售技术的王牌军,支撑淘宝、天猫核心电商以及淘宝直播、闲鱼、躺平、阿里汽车、阿里房产等创新业务,服务9亿用户,赋能各行业1000万商家。我们打造了全球领先的线上新零售技术平台,并作为核心技术团队保障了11次双十一购物狂欢节的成功。详情可查看我们官网:阿里巴巴淘系技术部官方网站
点击下方主页关注我们,你将收获更多来自阿里一线工程师的技术实战技巧&成长经历心得。另,不定期更新最新岗位招聘信息和简历内推通道,欢迎各位以最短路径加入我们。
阿里巴巴淘系技术
我曾经从传统的非互联网公司成功跳槽到腾讯,我来给大伙儿分享一些经验。
首先为啥面试官喜欢问高并发、性能调优相关的问题,我想有两点原因:
第一,本身互联网区别于传统软件行业的特点之一就是海量请求。传统软件公司每秒用户几个、几十个的请求很常见,但是互联网公司哪怕一个二线的 App,后端接口请求一天几个亿也很正常。业务特点导致对候选人在海量请求相关的技术上考察的会比较多。
第二、高并发性能调优等方面的问题相当于高考试卷里的难题部分。CRUD 谁都会,xx 培训机构培训上三个月,出来都能写。但是对于高性能、高并发这没几把刷子真会玩不起来的。通过这个来区分候选人水平的高低(招人肯定选水平高的)。
海量请求处理的解决方案无非就是多多堆机器(架构方案),压榨每台单机(性能调优)两个角度。我又仔细看了一下题主的问题条件,题主的现实条件是没有高并发项目经验。在这个前提条件下,我想你此后应对这类的面试把精力都聚焦在性能调优上更具备可操作性。
因为架构角度对于题主来说,不太具备实践的条件。缺乏实践应用的话很难真正掌握。如果你为了学习而强行把互联网常用的架构套到现在手头的项目上,那更是一件极其可怕的事情,对你的老东家也非常之不负责任。
而性能角度来说,我觉得任何项目,即使不是高流量,你都可以在日常工作中找到性能优化的机会。
我在 2010 年在第一家公司工作的时候,所负责的是一个纯客户端项目,换到今天流量角度来看的话,流量就是零,几乎没有啥网络请求。我也同样找到了优化的机会,比如我对这个 Windows 程序的启动过程进行了加速,减少了 20% 的启动耗时。我就是凭借着这类调优在 2011 年顺利进入到了腾讯。只要你有过性能调优的经验,面试官就会认可你。
再回到题主的问题,题主的低流量,并不是没流量。比起我之前的客户端项目,可挖掘的性能调优的点会更多。比如:
- 1、你的某个实际的接口每秒能有多少次的返回?瓶颈在哪儿,有没有办法优化?
- 2、你的一个后端空接口 QPS 能有多少,为啥比 Redis/Nginx 低,可否改进?
- 3、你的 Mysql 中有没有慢查询,有的话耗时多少,可否深度优化一下?
- 4、你的项目中是否存在同步阻塞的网络 IO,如果存在能否优化掉?
- 5、你的业务对磁盘访问是否存在可优化的随机 IO ?
- 6、......
找到可能的性能调优的点以后,你可以进行测试、优化方案思考,改进测试,然后最终找到可行的的优化办法(注意这些往往不是你的 leader 交给你做的,而是你要自己去主动发现,这个很关键)。
在这过程中,对你的开发内功相关的能力要求非常高。啥是内功?就是当年曾经你学过的操作系统、网络、硬件等这些知识。任何服务都是跑在这些基础之上的,只有你对他们有深刻的理解,你才能够源源不断想到新的调优办法。
为了方便阐述,我将开发内功分几个角度咱们展开了来聊聊,如何锻炼性能调优能力。
--- 这里插入一套精心整理的电子书资料
飞哥经常会收到读者的私信,询问可否推荐一些书继续深入学习内功。所以我干脆就写了篇文章。把能搜集到的电子版也帮大家汇总了一下,取需!
答读者问,能否推荐几本有价值的参考书(含下载地址)
继续!!
流量响应和处理都是建立在网络之上的。你们如果能加深对网络实现的理解的话,对于你性能调优能力会有极大的帮助。我来举几个我曾经深入挖掘过的例子。
例如 Linux 网络包是怎么接收的,CPU 里的 si 消耗是啥含义,ksoftirqd 内核线程是如何工作的。我都深入挖掘了一遍,并画了流程图。
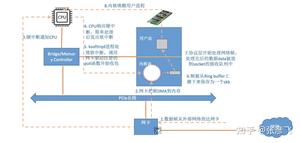
理解了网络包的接收过程,自然在接收这块遇到性能问题的时候,就知道该如何下手进行优化了。RingBuffer 是否应该加大,在什么情况下需要开启多队列网卡来优化网络性能。想看更细节的话,可以来看我的这两篇文章。
- 《图解Linux网络包接收过程》
- 《Linux网络包接收过程的监控与调优》
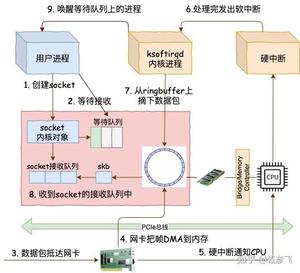
再比如还有人人都在说同步阻塞的性能差、说是多路复用如何如何的好,这到底为啥。后来经过深挖 Linux 内核源码后我发现问题的根本原因。
同步阻塞的网络 IO 模型里,一个进/线程只能处理一个连接请求。每创建一个进/线程都消耗非常大的资源不说,每次因为等待网络返回而被阻塞掉的时候,要花很多的 CPU(大约是 3 - 5微秒)的时间来处理上下文切换。如果请求频繁的话,CPU 就一直在干这种上下文切换的无用功(切换时间内其实没做任何用户相关的请求,都在忙于内耗),从而导致性能极其的低下。
到了多路复用,拿 epoll 来举例。一个进程可以同时监听和处理很多的用户请求,而且内部还使用了高效的红黑树和就绪队列的数据结构组合。当调用 epoll_wait 的时候,直接从就绪队列上获取就绪的请求开始处理。只要活儿足够的多,epoll_wait 根本都不会让进程阻塞。用户进程会一直干活,一直干活,直到 epoll_wait 里实在没活儿可干的时候才主动让出 CPU。这就是 epoll 高效的地方所在!
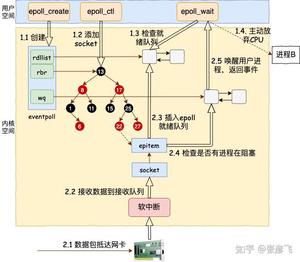
深刻理解了这些之后,可能都不需要你做过多的编码工作,只要去选择一个对网络 IO 模型封装的比较好的开发框架就能把手头项目的 QPS 提升好几倍。
例如 Golang 的 net 包,配合协程,直接把多路复用进行了彻底的封装。用很低的成本协程切换成本,封装出了易于使用的同步网络编程模型,但实际在进程角度来看都是非阻塞的。
再比如我们公司开源的 C++ Workflow, 也是彻底杜绝了低效的同步阻塞 IO。(Github地址在这里)
更多的网络相关的底层细节我就不展开说了,都写进我的电子书《理解了实现再谈网络性能》里了。
在我的这本电子书中,我深度分析了 Linux 是怎么接收一个网络包的,同步阻塞到底是咋回事,多路复用 epoll 内部又是通过什么方式来提升网络性能的。还有一台服务器究竟最大能支撑多少条 TCP 连接,每条连接需要消耗多大内存这种高并发相关问题的深度拆解。基于这些深度的分析,我给出了一系列的性能优化建议,全书有 200 多页,目录如下:
只要你能看一遍,在网络性能这块的理解和调优能力将能提升好几个 Level。感兴趣的同学点击下面这个链接就能领取。
飞哥的《理解了实现再谈网络性能》电子书发布啦!
我们再来讨论硬盘。写日志,读数据大部分时候都离不开硬盘。像 Mysql 设计的时候很多时候就是考虑磁盘性能怎么优化。即使大佬们做了许多工作,如果作为应用开发的同学不能够深入理解磁盘性能,那么优化起来还是乏力。
对此,我也做过一些性能对比测试工作。我曾经拿我手头一台带机械硬盘的服务器,使用 fio 工具对顺序 IO、随机 IO 在带宽、延迟、IOPS 三个指标进行对比。实验结果如下图:
顺序 IO:

随机 IO:

拿 512 字节的 IO size 来看,在顺序 IO 的时候,磁盘每秒能有 30000 多次的响应。而到了随机 IO 的情况下,每秒只有区区 200。
当你从数字上直观理解了机械硬盘在顺序 IO 和随机 IO 时延时的巨大差异之后,这也将有利于帮助你寻找手头项目里存在的随机 IO,找到后你想办法把它改成顺序 IO,调优一下。
如果实在是避免不了的随机 IO,那就去找找运维,看能不能换成固态硬盘。固态硬盘的随机 IO 性能要比 机械硬盘强很多。

详情参考这篇文章: 《搭载固态硬盘的服务器究竟比搭机械硬盘快多少?》
绝大部分人对内存的理解,就一个字,快!其实这个理解是非常之肤浅的。
内存很多时候快是因为 CPU 的 L1、L2、L3 对齐进行了有效的加速。当加速失效(你写出的程序没有很好的局部性),内存同样没那么快的。另外就是在内存上,也同样存在随机 IO 比顺序 IO 慢几倍的情况。这个很少有人了解。
我先是做了顺序 IO 的测试,定义一个数组,变化其大小从 2K 到 64M。当数组比较小的时候,L1 基本都能装下,再大一点访问时最多能穿透 L1 到 L2。当数组大到 64 M 的时候,尤其是步长大一点循环的时候,大概率缓存已经都不住请求,会穿透到内存。(测试方法来源于 csapp 中的存储器山相关部分,做了一些简单的改造)
当数据在 L1 中存在的时候,延迟只有 1 纳秒多一点,当穿透 L1 到 L2 之后,延迟明显上升,到最后,延迟上升了了 8 - 9 纳秒左右 。
稍后我又测试了不以顺序递增的方式进行访问,而是准备一个随机数组,彻底打乱,构造随机访问的情形,发现内存 IO 延迟下降到了38 纳秒。比顺序 IO 时多了三、四倍。
想了解详情的话参考我的这篇文章。
- 《实际测试内存在顺序IO和随机IO时的访问延时差异》
- 《内存随机也比顺序访问慢,带你深入理解内存IO过程》
如果内存你能理解到这个深度,回头看看你项目中是不是存在问题,能不能把访问都尽量构造好的局部性,让L1、L2、L3等组件多多工作,让内存多歇着。 或者内存非得工作的时候,你能不能让它尽量进行顺序 IO。
我曾经利用这一个深度的理解,把一个从 redis 获取一个大数据的耗时从 4ms 降低到了 1ms。深度理解了内存,在性能调优上也会有新思路产生。
好了,飞哥得准备新文章去了,今天就先聊到这里吧。以上的几个问题相当于给大家指一个性能调优的方向。不一定全,因为性能优化的方法太多太多了。但是无论是啥方法都离不开你对底层工作原理的深刻理解,我习惯把它称之为内功。
欢迎你来关注飞哥的公众号「开发内功修炼」
等你具备了深厚的内功能力,你根本不用担心不会性能调优。随便在手头的项目中挖一挖,都一大把值得优化的点。
当你用深厚的内功对手头的项目进行过多次的优化之后,当面试官再问你的高并发性能调优相关的问题的时候,你就有了充足的弹药来使用了。
收藏数咋是赞的三倍还多,觉得有用就留个赞吧,谢了!
说实话,大部分开发人员做的系统并发量都比较小,尤其是很多从0到1做起来的新项目。
那么,我们平常如何接触高并发技术呢?
其实最经典高并发项目是秒杀系统,大量的用户在极短的时间内购买少量的商品。比如:小米手机的秒杀功能,刚开始小米的网站经常挂,后面经过不断优化,不断迭代升级,变成了现在的样子。
针对高并发的业务场景,所需要的技术手段更多更复杂。
那么,高并发下如何设计秒杀系统?这是一个高频面试题。这个问题看似简单,但是里面的水很深,它考查的是高并发场景下,从前端到后端多方面的知识。
秒杀一般出现在商城的促销活动中,指定了一定数量(比如:10个)的商品(比如:手机),以极低的价格(比如:0.1元),让大量用户参与活动,但只有极少数用户能够购买成功。这类活动商家绝大部分是不赚钱的,说白了是找个噱头宣传自己。
虽说秒杀只是一个促销活动,但对技术要求不低。下面给大家总结一下设计秒杀系统需要注意的9个细节。
最近无意间获得一份BAT大厂大佬写的刷题笔记,一下子打通了我的任督二脉,越来越觉得算法没有想象中那么难了。
[BAT大佬写的刷题笔记,让我offer拿到手软](这位BAT大佬写的Leetcode刷题笔记,让我offer拿到手软)
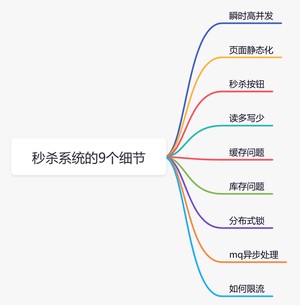
一般在秒杀时间点(比如:12点)前几分钟,用户并发量才真正突增,达到秒杀时间点时,并发量会达到顶峰。
但由于这类活动是大量用户抢少量商品的场景,必定会出现狼多肉少的情况,所以其实绝大部分用户秒杀会失败,只有极少部分用户能够成功。
正常情况下,大部分用户会收到商品已经抢完的提醒,收到该提醒后,他们大概率不会在那个活动页面停留了,如此一来,用户并发量又会急剧下降。所以这个峰值持续的时间其实是非常短的,这样就会出现瞬时高并发的情况,下面用一张图直观的感受一下流量的变化:
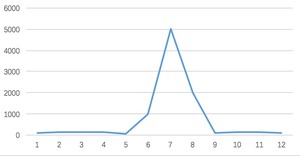
像这种瞬时高并发的场景,传统的系统很难应对,我们需要设计一套全新的系统。可以从以下几个方面入手:
- 页面静态化
- CDN加速
- 缓存
- mq异步处理
- 限流
- 分布式锁
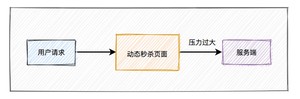
活动页面是用户流量的第一入口,所以是并发量最大的地方。
如果这些流量都能直接访问服务端,恐怕服务端会因为承受不住这么大的压力,而直接挂掉。
活动页面绝大多数内容是固定的,比如:商品名称、商品描述、图片等。为了减少不必要的服务端请求,通常情况下,会对活动页面做静态化处理。用户浏览商品等常规操作,并不会请求到服务端。只有到了秒杀时间点,并且用户主动点了秒杀按钮才允许访问服务端。
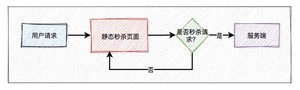
这样能过滤大部分无效请求。
但只做页面静态化还不够,因为用户分布在全国各地,有些人在北京,有些人在成都,有些人在深圳,地域相差很远,网速各不相同。
如何才能让用户最快访问到活动页面呢?
这就需要使用CDN,它的全称是Content Delivery Network,即内容分发网络。
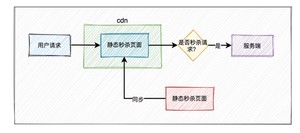
使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
大部分用户怕错过秒杀时间点,一般会提前进入活动页面。此时看到的秒杀按钮是置灰,不可点击的。只有到了秒杀时间点那一时刻,秒杀按钮才会自动点亮,变成可点击的。
但此时很多用户已经迫不及待了,通过不停刷新页面,争取在第一时间看到秒杀按钮的点亮。
从前面得知,该活动页面是静态的。那么我们在静态页面中如何控制秒杀按钮,只在秒杀时间点时才点亮呢?
没错,使用js文件控制。
为了性能考虑,一般会将css、js和图片等静态资源文件提前缓存到CDN上,让用户能够就近访问秒杀页面。
看到这里,有些聪明的小伙伴,可能会问:CDN上的js文件是如何更新的?
秒杀开始之前,js标志为false,还有另外一个随机参数。
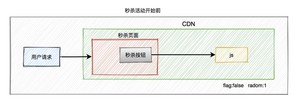
当秒杀开始的时候系统会生成一个新的js文件,此时标志为true,并且随机参数生成一个新值,然后同步给CDN。由于有了这个随机参数,CDN不会缓存数据,每次都能从CDN中获取最新的js代码。
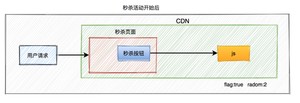
此外,前端还可以加一个定时器,控制比如:10秒之内,只允许发起一次请求。如果用户点击了一次秒杀按钮,则在10秒之内置灰,不允许再次点击,等到过了时间限制,又允许重新点击该按钮。
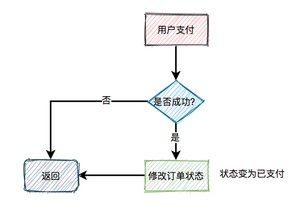
在秒杀的过程中,系统一般会先查一下库存是否足够,如果足够才允许下单,写数据库。如果不够,则直接返回该商品已经抢完。
由于大量用户抢少量商品,只有极少部分用户能够抢成功,所以绝大部分用户在秒杀时,库存其实是不足的,系统会直接返回该商品已经抢完。
这是非常典型的:读多写少 的场景。
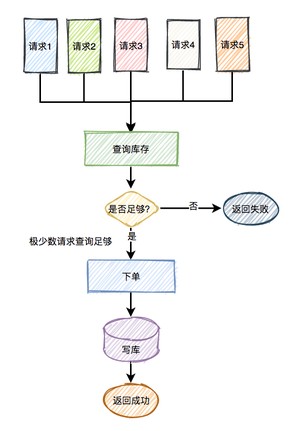
如果有数十万的请求过来,同时通过数据库查缓存是否足够,此时数据库可能会挂掉。因为数据库的连接资源非常有限,比如:mysql,无法同时支持这么多的连接。
而应该改用缓存,比如:redis。
即便用了redis,也需要部署多个节点。
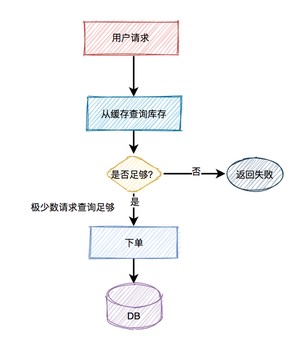
通常情况下,我们需要在redis中保存商品信息,里面包含:商品id、商品名称、规格属性、库存等信息,同时数据库中也要有相关信息,毕竟缓存并不完全可靠。
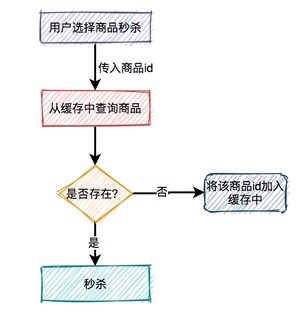
用户在点击秒杀按钮,请求秒杀接口的过程中,需要传入的商品id参数,然后服务端需要校验该商品是否合法。
大致流程如下图所示:
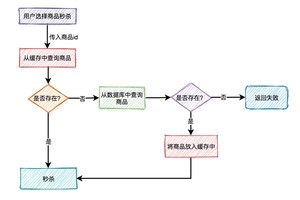
根据商品id,先从缓存中查询商品,如果商品存在,则参与秒杀。如果不存在,则需要从数据库中查询商品,如果存在,则将商品信息放入缓存,然后参与秒杀。如果商品不存在,则直接提示失败。
这个过程表面上看起来是OK的,但是如果深入分析一下会发现一些问题。
比如商品A第一次秒杀时,缓存中是没有数据的,但数据库中有。虽说上面有如果从数据库中查到数据,则放入缓存的逻辑。
然而,在高并发下,同一时刻会有大量的请求,都在秒杀同一件商品,这些请求同时去查缓存中没有数据,然后又同时访问数据库。结果悲剧了,数据库可能扛不住压力,直接挂掉。
如何解决这个问题呢?
这就需要加锁,最好使用分布式锁。
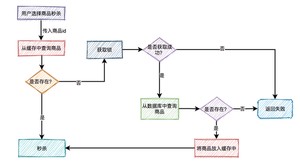
当然,针对这种情况,最好在项目启动之前,先把缓存进行预热。即事先把所有的商品,同步到缓存中,这样商品基本都能直接从缓存中获取到,就不会出现缓存击穿的问题了。
是不是上面加锁这一步可以不需要了?
表面上看起来,确实可以不需要。但如果缓存中设置的过期时间不对,缓存提前过期了,或者缓存被不小心删除了,如果不加速同样可能出现缓存击穿。
其实这里加锁,相当于买了一份保险。
如果有大量的请求传入的商品id,在缓存中和数据库中都不存在,这些请求不就每次都会穿透过缓存,而直接访问数据库了。
由于前面已经加了锁,所以即使这里的并发量很大,也不会导致数据库直接挂掉。
但很显然这些请求的处理性能并不好,有没有更好的解决方案?
这时可以想到布隆过滤器。
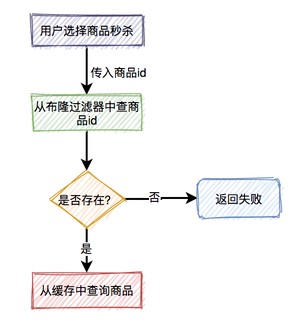
系统根据商品id,先从布隆过滤器中查询该id是否存在,如果存在则允许从缓存中查询数据,如果不存在,则直接返回失败。
虽说该方案可以解决缓存穿透问题,但是又会引出另外一个问题:布隆过滤器中的数据如何更缓存中的数据保持一致?
这就要求,如果缓存中数据有更新,则要及时同步到布隆过滤器中。如果数据同步失败了,还需要增加重试机制,而且跨数据源,能保证数据的实时一致性吗?
显然是不行的。
所以布隆过滤器绝大部分使用在缓存数据更新很少的场景中。
如果缓存数据更新非常频繁,又该如何处理呢?
这时,就需要把不存在的商品id也缓存起来。
下次,再有该商品id的请求过来,则也能从缓存中查到数据,只不过该数据比较特殊,表示商品不存在。需要特别注意的是,这种特殊缓存设置的超时时间应该尽量短一点。
对于库存问题看似简单,实则里面还是有些东西。
真正的秒杀商品的场景,不是说扣完库存,就完事了,如果用户在一段时间内,还没完成支付,扣减的库存是要加回去的。
所以,在这里引出了一个预扣库存的概念,预扣库存的主要流程如下:
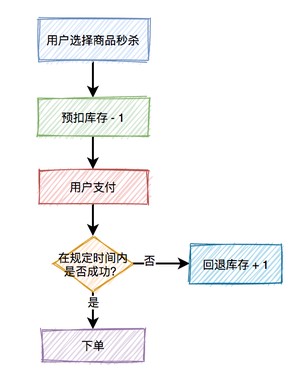
扣减库存中除了上面说到的预扣库存和回退库存之外,还需要特别注意的是库存不足和库存超卖问题。
使用数据库扣减库存,是最简单的实现方案了,假设扣减库存的sql如下:
update product set stock=stock-1 where id=123; 这种写法对于扣减库存是没有问题的,但如何控制库存不足的情况下,不让用户操作呢?
这就需要在update之前,先查一下库存是否足够了。
伪代码如下:
int stock = mapper.getStockById(123); if(stock > 0) { int count = mapper.updateStock(123); if(count > 0) { addOrder(123); } } 大家有没有发现这段代码的问题?
没错,查询操作和更新操作不是原子性的,会导致在并发的场景下,出现库存超卖的情况。
有人可能会说,这样好办,加把锁,不就搞定了,比如使用synchronized关键字。
确实,可以,但是性能不够好。
还有更优雅的处理方案,即基于数据库的乐观锁,这样会少一次数据库查询,而且能够天然的保证数据操作的原子性。
只需将上面的sql稍微调整一下:
update product set stock=stock-1 where id=product and stock > 0; 在sql最后加上:stock > 0,就能保证不会出现超卖的情况。
但需要频繁访问数据库,我们都知道数据库连接是非常昂贵的资源。在高并发的场景下,可能会造成系统雪崩。而且,容易出现多个请求,同时竞争行锁的情况,造成相互等待,从而出现死锁的问题。
redis的incr方法是原子性的,可以用该方法扣减库存。伪代码如下:
boolean exist = redisClient.query(productId,userId); if(exist) { return -1; } int stock = redisClient.queryStock(productId); if(stock <=0) { return 0; } redisClient.incrby(productId, -1); redisClient.add(productId,userId); return 1; 代码流程如下:
- 先判断该用户有没有秒杀过该商品,如果已经秒杀过,则直接返回-1。
- 查询库存,如果库存小于等于0,则直接返回0,表示库存不足。
- 如果库存充足,则扣减库存,然后将本次秒杀记录保存起来。然后返回1,表示成功。
估计很多小伙伴,一开始都会按这样的思路写代码。但如果仔细想想会发现,这段代码有问题。
有什么问题呢?
如果在高并发下,有多个请求同时查询库存,当时都大于0。由于查询库存和更新库存非原则操作,则会出现库存为负数的情况,即库存超卖。
当然有人可能会说,加个synchronized不就解决问题?
调整后代码如下:
boolean exist = redisClient.query(productId,userId); if(exist) { return -1; } synchronized(this) { int stock = redisClient.queryStock(productId); if(stock <=0) { return 0; } redisClient.incrby(productId, -1); redisClient.add(productId,userId); } return 1; 加synchronized确实能解决库存为负数问题,但是这样会导致接口性能急剧下降,每次查询都需要竞争同一把锁,显然不太合理。
为了解决上面的问题,代码优化如下:
boolean exist = redisClient.query(productId,userId); if(exist) { return -1; } if(redisClient.incrby(productId, -1)<0) { return 0; } redisClient.add(productId,userId); return 1; 该代码主要流程如下:
- 先判断该用户有没有秒杀过该商品,如果已经秒杀过,则直接返回-1。
- 扣减库存,判断返回值是否小于0,如果小于0,则直接返回0,表示库存不足。
- 如果扣减库存后,返回值大于或等于0,则将本次秒杀记录保存起来。然后返回1,表示成功。
该方案咋一看,好像没问题。
但如果在高并发场景中,有多个请求同时扣减库存,大多数请求的incrby操作之后,结果都会小于0。
虽说,库存出现负数,不会出现超卖的问题。但由于这里是预减库存,如果负数值负的太多的话,后面万一要回退库存时,就会导致库存不准。
那么,有没有更好的方案呢?
我们都知道lua脚本,是能够保证原子性的,它跟redis一起配合使用,能够完美解决上面的问题。
lua脚本有段非常经典的代码:
StringBuilder lua = new StringBuilder(); lua.append("if (redis.call('exists', KEYS[1]) == 1) then"); lua.append(" local stock = tonumber(redis.call('get', KEYS[1]));"); lua.append(" if (stock == -1) then"); lua.append(" return 1;"); lua.append(" end;"); lua.append(" if (stock > 0) then"); lua.append(" redis.call('incrby', KEYS[1], -1);"); lua.append(" return stock;"); lua.append(" end;"); lua.append(" return 0;"); lua.append("end;"); lua.append("return -1;"); 该代码的主要流程如下:
- 先判断商品id是否存在,如果不存在则直接返回。
- 获取该商品id的库存,判断库存如果是-1,则直接返回,表示不限制库存。
- 如果库存大于0,则扣减库存。
- 如果库存等于0,是直接返回,表示库存不足。
之前我提到过,在秒杀的时候,需要先从缓存中查商品是否存在,如果不存在,则会从数据库中查商品。如果数据库中,则将该商品放入缓存中,然后返回。如果数据库中没有,则直接返回失败。
大家试想一下,如果在高并发下,有大量的请求都去查一个缓存中不存在的商品,这些请求都会直接打到数据库。数据库由于承受不住压力,而直接挂掉。
那么如何解决这个问题呢?
这就需要用redis分布式锁了。
使用redis的分布式锁,首先想到的是setNx命令。
if (jedis.setnx(lockKey, val) == 1) { jedis.expire(lockKey, timeout); } 用该命令其实可以加锁,但和后面的设置超时时间是分开的,并非原子操作。
假如加锁成功了,但是设置超时时间失败了,该lockKey就变成永不失效的了。在高并发场景中,该问题会导致非常严重的后果。
那么,有没有保证原子性的加锁命令呢?
使用redis的set命令,它可以指定多个参数。
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime); if ("OK".equals(result)) { return true; } return false; 其中:
- lockKey:锁的标识
- requestId:请求id
- NX:只在键不存在时,才对键进行设置操作。
- PX:设置键的过期时间为 millisecond 毫秒。
- expireTime:过期时间
由于该命令只有一步,所以它是原子操作。
接下来,有些朋友可能会问:在加锁时,既然已经有了lockKey锁标识,为什么要需要记录requestId呢?
答:requestId是在释放锁的时候用的。
if (jedis.get(lockKey).equals(requestId)) { jedis.del(lockKey); return true; } return false; 在释放锁的时候,只能释放自己加的锁,不允许释放别人加的锁。
这里为什么要用requestId,用userId不行吗?
答:如果用userId的话,假设本次请求流程走完了,准备删除锁。此时,巧合锁到了过期时间失效了。而另外一个请求,巧合使用的相同userId加锁,会成功。而本次请求删除锁的时候,删除的其实是别人的锁了。
当然使用lua脚本也能避免该问题:
if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end 它能保证查询锁是否存在和删除锁是原子操作。
上面的加锁方法看起来好像没有问题,但如果你仔细想想,如果有1万的请求同时去竞争那把锁,可能只有一个请求是成功的,其余的9999个请求都会失败。
在秒杀场景下,会有什么问题?
答:每1万个请求,有1个成功。再1万个请求,有1个成功。如此下去,直到库存不足。这就变成均匀分布的秒杀了,跟我们想象中的不一样。
如何解决这个问题呢?
答:使用自旋锁。
try { Long start = System.currentTimeMillis(); while(true) { String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime); if ("OK".equals(result)) { return true; } long time = System.currentTimeMillis() - start; if (time>=timeout) { return false; } try { Thread.sleep(50); } catch (InterruptedException e) { e.printStackTrace(); } } } finally{ unlock(lockKey,requestId); } return false; 在规定的时间,比如500毫秒内,自旋不断尝试加锁,如果成功则直接返回。如果失败,则休眠50毫秒,再发起新一轮的尝试。如果到了超时时间,还未加锁成功,则直接返回失败。
除了上面的问题之外,使用redis分布式锁,还有锁竞争问题、续期问题、锁重入问题、多个redis实例加锁问题等。
这些问题使用redisson可以解决,由于篇幅的原因,在这里先保留一点悬念,有疑问的私聊给我。后面会出一个专题介绍分布式锁,敬请期待。
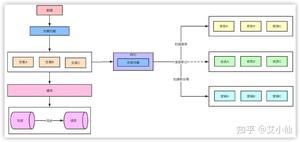
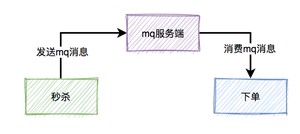
我们都知道在真实的秒杀场景中,有三个核心流程:

而这三个核心流程中,真正并发量大的是秒杀功能,下单和支付功能实际并发量很小。所以,我们在设计秒杀系统时,有必要把下单和支付功能从秒杀的主流程中拆分出来,特别是下单功能要做成mq异步处理的。而支付功能,比如支付宝支付,是业务场景本身保证的异步。
于是,秒杀后下单的流程变成如下:
如果使用mq,需要关注以下几个问题:
秒杀成功了,往mq发送下单消息的时候,有可能会失败。原因有很多,比如:网络问题、broker挂了、mq服务端磁盘问题等。这些情况,都可能会造成消息丢失。
那么,如何防止消息丢失呢?
答:加一张消息发送表。
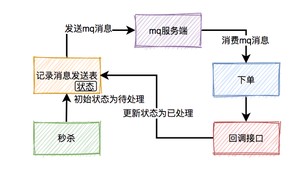
在生产者发送mq消息之前,先把该条消息写入消息发送表,初始状态是待处理,然后再发送mq消息。消费者消费消息时,处理完业务逻辑之后,再回调生产者的一个接口,修改消息状态为已处理。
如果生产者把消息写入消息发送表之后,再发送mq消息到mq服务端的过程中失败了,造成了消息丢失。
这时候,要如何处理呢?
答:使用job,增加重试机制。
最近无意间获得一份BAT大厂大佬写的刷题笔记,一下子打通了我的任督二脉,越来越觉得算法没有想象中那么难了。
[BAT大佬写的刷题笔记,让我offer拿到手软](这位BAT大佬写的Leetcode刷题笔记,让我offer拿到手软)
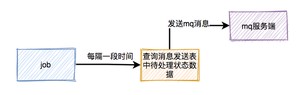
用job每隔一段时间去查询消息发送表中状态为待处理的数据,然后重新发送mq消息。
本来消费者消费消息时,在ack应答的时候,如果网络超时,本身就可能会消费重复的消息。但由于消息发送者增加了重试机制,会导致消费者重复消息的概率增大。
那么,如何解决重复消息问题呢?
答:加一张消息处理表。
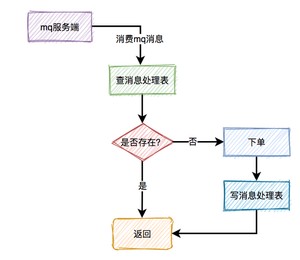
消费者读到消息之后,先判断一下消息处理表,是否存在该消息,如果存在,表示是重复消费,则直接返回。如果不存在,则进行下单操作,接着将该消息写入消息处理表中,再返回。
有个比较关键的点是:下单和写消息处理表,要放在同一个事务中,保证原子操作。
这套方案表面上看起来没有问题,但如果出现了消息消费失败的情况。比如:由于某些原因,消息消费者下单一直失败,一直不能回调状态变更接口,这样job会不停的重试发消息。最后,会产生大量的垃圾消息。
那么,如何解决这个问题呢?
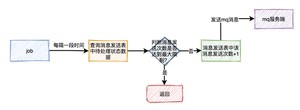
每次在job重试时,需要先判断一下消息发送表中该消息的发送次数是否达到最大限制,如果达到了,则直接返回。如果没有达到,则将次数加1,然后发送消息。
这样如果出现异常,只会产生少量的垃圾消息,不会影响到正常的业务。
通常情况下,如果用户秒杀成功了,下单之后,在15分钟之内还未完成支付的话,该订单会被自动取消,回退库存。
那么,在15分钟内未完成支付,订单被自动取消的功能,要如何实现呢?
我们首先想到的可能是job,因为它比较简单。
但job有个问题,需要每隔一段时间处理一次,实时性不太好。
还有更好的方案?
答:使用延迟队列。
我们都知道rocketmq,自带了延迟队列的功能。
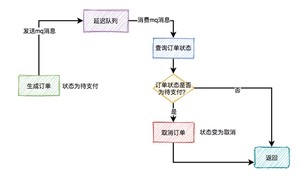
下单时消息生产者会先生成订单,此时状态为待支付,然后会向延迟队列中发一条消息。达到了延迟时间,消息消费者读取消息之后,会查询该订单的状态是否为待支付。如果是待支付状态,则会更新订单状态为取消状态。如果不是待支付状态,说明该订单已经支付过了,则直接返回。
还有个关键点,用户完成支付之后,会修改订单状态为已支付。
通过秒杀活动,如果我们运气爆棚,可能会用非常低的价格买到不错的商品(这种概率堪比买福利彩票中大奖)。
但有些高手,并不会像我们一样老老实实,通过秒杀页面点击秒杀按钮,抢购商品。他们可能在自己的服务器上,模拟正常用户登录系统,跳过秒杀页面,直接调用秒杀接口。
如果是我们手动操作,一般情况下,一秒钟只能点击一次秒杀按钮。
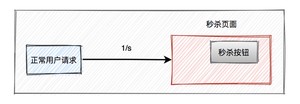
但是如果是服务器,一秒钟可以请求成上千接口。
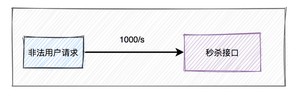
这种差距实在太明显了,如果不做任何限制,绝大部分商品可能是被机器抢到,而非正常的用户,有点不太公平。
所以,我们有必要识别这些非法请求,做一些限制。那么,我们该如何现在这些非法请求呢?
目前有两种常用的限流方式:
- 基于nginx限流
- 基于redis限流
为了防止某个用户,请求接口次数过于频繁,可以只针对该用户做限制。
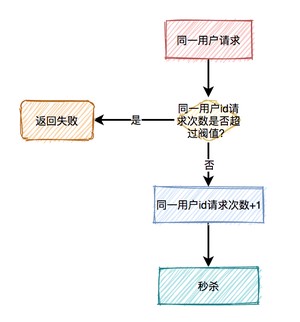
限制同一个用户id,比如每分钟只能请求5次接口。
有时候只对某个用户限流是不够的,有些高手可以模拟多个用户请求,这种nginx就没法识别了。
这时需要加同一ip限流功能。
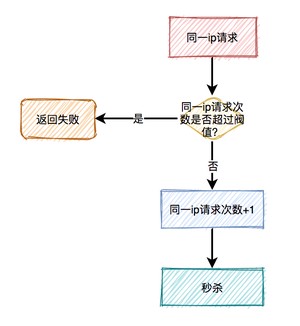
限制同一个ip,比如每分钟只能请求5次接口。
但这种限流方式可能会有误杀的情况,比如同一个公司或网吧的出口ip是相同的,如果里面有多个正常用户同时发起请求,有些用户可能会被限制住。
别以为限制了用户和ip就万事大吉,有些高手甚至可以使用代理,每次都请求都换一个ip。
这时可以限制请求的接口总次数。
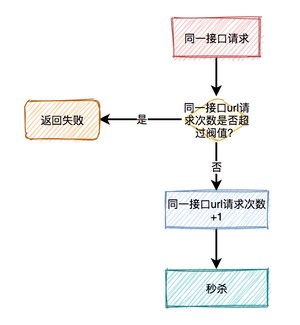
在高并发场景下,这种限制对于系统的稳定性是非常有必要的。但可能由于有些非法请求次数太多,达到了该接口的请求上限,而影响其他的正常用户访问该接口。看起来有点得不偿失。
相对于上面三种方式,加验证码的方式可能更精准一些,同样能限制用户的访问频次,但好处是不会存在误杀的情况。
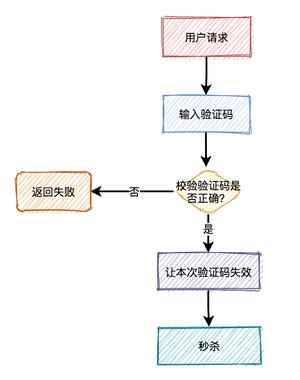
通常情况下,用户在请求之前,需要先输入验证码。用户发起请求之后,服务端会去校验该验证码是否正确。只有正确才允许进行下一步操作,否则直接返回,并且提示验证码错误。
此外,验证码一般是一次性的,同一个验证码只允许使用一次,不允许重复使用。
普通验证码,由于生成的数字或者图案比较简单,可能会被激活成功教程。优点是生成速度比较快,缺点是有安全隐患。
还有一个验证码叫做:移动滑块,它生成速度比较慢,但比较安全,是目前各大互联网公司的首选。
最近无意间获得一份BAT大厂大佬写的刷题笔记,一下子打通了我的任督二脉,越来越觉得算法没有想象中那么难了。
[BAT大佬写的刷题笔记,让我offer拿到手软](这位BAT大佬写的Leetcode刷题笔记,让我offer拿到手软)
上面说的加验证码虽然可以限制非法用户请求,但是有些影响用户体验。用户点击秒杀按钮前,还要先输入验证码,流程显得有点繁琐,秒杀功能的流程不是应该越简单越好吗?
其实,有时候达到某个目的,不一定非要通过技术手段,通过业务手段也一样。
12306刚开始的时候,全国人民都在同一时刻抢火车票,由于并发量太大,系统经常挂。后来,重构优化之后,将购买周期放长了,可以提前20天购买火车票,并且可以在9点、10、11点、12点等整点购买火车票。调整业务之后(当然技术也有很多调整),将之前集中的请求,分散开了,一下子降低了用户并发量。
回到这里,我们通过提高业务门槛,比如只有会员才能参与秒杀活动,普通注册用户没有权限。或者,只有等级到达3级以上的普通用户,才有资格参加该活动。
这样简单的提高一点门槛,即使是黄牛党也束手无策,他们总不可能为了参加一次秒杀活动,还另外花钱充值会员吧?
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。

链接:https://pan.baidu.com/s/1UECE5yuaoTTRpJfi5LU5TQ 密码:bhbe
不会有人刷到这里还想白嫖吧?点赞对我真的非常重要!在线求赞。加个关注我会非常感激! @苏三说技术
我司有个同事也是,天天把高并发大数据挂在嘴上。
代码写的稀烂,循环里打log,log还用中文。。。
在spring could gateway里用jdbc/redis template。
我leetcode ac了1500+,和我说刷题没用,得有高并发海量数据的项目经验,我tm不知道啊…?那也得公司有啊。
年薪还是我的3倍。。还真是让他踩到互联网红利了。
================================
没想到上班摸鱼随便吐槽两句还引起了argue…
1. 循环是在过滤数据,log的是过滤的参数/结果。请问直接在循环开始前和结束后log不就可以了吗,有必要log成千上万行写到磁盘吗。我不否认每行都log更利于追踪,但是私以为弊大于利。
2. log中文这个,没啥想说的,仁者见仁智者见智吧。
3. Gateway处理请求应该使用r2dbc和reactive redis template。闭着眼睛crud,却张口闭口高并发,我觉得挺可笑的。
4. 我只是随口吐槽两句,不想和各种再做争论,如果哪句话说错了,那是我菜。

在《系统性能优化三板斧之如何解决“读多”问题?》里我总结了读的问题,缓存就能解决90%以上的问题,可是对于程序员来讲,“写多”的场景才是硬核,才具有挑战性。
在阅读本篇前,我还曾写过一篇《数据库优化之路,别上来就问我分库分表》,里面有一句话我一直喜欢:能用简单的方式解决80%的问题,也比复杂的方案解决95%的方式优先;
今天呢,我想把大规模海量数据的“写”问题,抛砖引玉,试着去讲明白。

1.数据存储容量的问题。
既然动不动处理的就是T 或者更大的 PB 计的数据问题,而一般的服务器磁盘容量通常 1~2TB,那么如何存储这么大规模的数据呢?
2.数据读写速度的问题。
一般磁盘的连续读写速度为几十 MB,以这样的速度,几十 PB 的数据恐怕要读写到天荒地老。
3.数据可靠性的问题。
磁盘大约是计算机设备中最易损坏的硬件了,通常情况一块磁盘使用寿命大概是一年,如果磁盘损坏了,数据怎么办?
后来出现的所有存储技术,目标很明确,就是解决这三个问题。
一、单机-单磁盘
在很久很久以前,硬件成本很高,每台机器就一个磁盘,那当时是怎么进行优化的呢,很显然,那会数据的容量不是主要问题,反而是强大的CPU运转与磁盘数据读写速度是主要矛盾。
当然了,放到现在,这些技术我们一直还在使用,是什么?
其实磁盘顺序读写还是很快的,没有想象的那么慢,有多快?顺序写的性能堪比写内存,你说有多快。

性能测试的结果表明普通机械磁盘的顺序I/O性能指标是53.2M values/s,SSD的顺序I/O性能指标是42.2M values/s,而内存的随机I/O性能指标是36.7M values/s。
不过这个报告,网上有很多的版本,说数据不准确,不过我想说的意思,应该明白:顺序写真的很快。
现实中的数据写入往往不是那么如意,随机的场景更多,那么有没有什么方式可以将顺序读写这个优势利用起来呢?
当然有了,缓存/缓冲 + 异步化 就是一种很好的办法。
我们常用的mysql 数据库就是这样做的。
我们知道缓存能提高读的性能,数据库将很大一部分数据存放在内存中,当程序要修改数据库中数据,不是真正修改磁盘中数据,而是写把操作记录(注意是操作记录,不是要修改的数据)写到磁盘缓冲区,这个磁盘缓冲区就是物理内存的一部分,所以写性能,不是问题。
程序将数据写到缓冲区就够了,剩下的事交给操作系统,操作系统或者应用程序的一个线程会专门做这件事,将缓冲区的数据,顺序的写到磁盘上,数据库的高性能就是这么简单。
还有一个最牛逼的MQ中间件,kafka也是同样的道理,日志数据写到缓冲区,剩下的慢慢写磁盘。
当然了,这里面有个也算严重的问题。
牺牲掉了一些可靠性,毕竟物理内存断电易丢失的问题还是无法避免,所以,这些文件系统都提供了一个可选参数:写磁盘的频率。
简单理解是是一操作就写一次磁盘,还是批量几次操作再写,还是压根就不写。
可以根据不同的场景的可靠性要求去配置。

我们看单机-单磁盘下,三个问题中,只有读写性能这方面有提高,其他差强人意。
二、单机-多磁盘
上面提到,容量问题以及可靠性在单机-单磁盘时代没有改进,对付这两个,有什么方法?
想想一下,葫芦娃救爷爷还得六个一起上呢,何况笨重的磁盘,怎么招,也得组团吧。
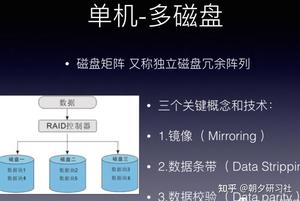
RAID ( Redundant Array of Independent Disks )即独立磁盘冗余阵列,通常简称为磁盘阵列。
简单地说, RAID 是由多个独立的高性能磁盘驱动器组成的磁盘子系统,从而提供比单个磁盘更高的存储性能和数据冗余的技术。
RAID(独立磁盘冗余阵列)技术是将多块普通磁盘组成一个阵列,共同对外提供服务。
主要是为了改善磁盘的存储容量、读写速度,增强磁盘的可用性和容错能力。
目前服务器级别的计算机都支持插入多块磁盘(8 块或者更多),通过使用 RAID 技术,实现数据在多块磁盘上的并发读写和数据备份。
RAID 中主要有三个关键概念和技术:镜像( Mirroring )、数据条带( Data Stripping )和数据校验( Data parity ) 。
镜像,将数据复制到多个磁盘,一方面可以提高可靠性,另一方面可并发从两个或多个副本读取数据来提高读性能。显而易见,镜像的写性能要稍低, 确保数据正确地写到多个磁盘需要更多的时间消耗。
数据条带,将数据分片保存在多个不同的磁盘,多个数据分片共同组成一个完整数据副本,这与镜像的多个副本是不同的,它通常用于性能考虑。数据条带具有更高的并发粒度,当访问数据时,可以同时对位于不同磁盘上数据进行读写操作, 从而获得非常可观的 I/O 性能提升 。
数据校验,利用冗余数据进行数据错误检测和修复,冗余数据通常采用海明码、异或操作等算法来计算获得。利用校验功能,可以很大程度上提高磁盘阵列的可靠性、鲁棒性和容错能力。不过,数据校验需要从多处读取数据并进行计算和对比,会影响系统性能。不同等级的 RAID 采用一个或多个以上的三种技术,来获得不同的数据可靠性、可用性和 I/O 性能。
我们先假设服务器有 N 块磁盘。
RAID 0。
数据在从内存缓冲区写入磁盘时,根据磁盘数量将数据分成 N 份,这些数据同时并发写入 N 块磁盘,使得数据整体写入速度是一块磁盘的 N 倍;读取的时候也一样,因此 RAID 0 具有极快的数据读写速度。但是 RAID 0 不做数据备份,N 块磁盘中只要有一块损坏,数据完整性就被破坏,其他磁盘的数据也都无法使用了。
结论:能一定范围内解决存储,读写性能问题,但是可用性不能保证。
RAID 1
数据在写入磁盘时,将一份数据同时写入两块磁盘,这样任何一块磁盘损坏都不会导致数据丢失,插入一块新磁盘就可以通过复制数据的方式自动修复,具有极高的可靠性。
结论:磁盘空间利用率不高,只能使用一半。
结合 RAID 0 和 RAID 1 两种方案构成了 RAID 10,它是将所有磁盘 N 平均分成两份,数据同时在两份磁盘写入,相当于 RAID 1;但是平分成两份,在每一份磁盘(也就是 N/2 块磁盘)里面,利用 RAID 0 技术并发读写,这样既提高可靠性又改善性能。不过 RAID 10 的磁盘利用率较低,有一半的磁盘用来写备份数据。
一般情况下,一台服务器上很少出现同时损坏两块磁盘的情况,在只损坏一块磁盘的情况下,如果能利用其他磁盘的数据恢复损坏磁盘的数据,这样在保证可靠性和性能的同时,磁盘利用率也得到大幅提升。
顺着这个思路,RAID 3 可以在数据写入磁盘的时候,将数据分成 N-1 份,并发写入 N-1 块磁盘,并在第 N 块磁盘记录校验数据,这样任何一块磁盘损坏,都可以利用其他 N-1 块磁盘的数据修复。
相比 RAID 3,RAID 5 是使用更多的方案。RAID 5 和 RAID 3 很相似,但是校验数据不是写入第 N 块磁盘,而是螺旋式地写入所有磁盘中。这样校验数据的修改也被平均到所有磁盘上,避免 RAID 3 频繁写坏一块磁盘的情况。
如果数据需要很高的可靠性,在出现同时损坏两块磁盘的情况下(或者运维管理水平比较落后,坏了一块磁盘但是迟迟没有更换,导致又坏了一块磁盘),仍然需要修复数据,这时候可以使用 RAID 6。
前面所述的各个 RAID 等级都只能保护因单个磁盘失效而造成的数据丢失。如果两个磁盘同时发生故障,数据将无法恢复。RAID6引入双重校验的概念,它可以保护阵列中同时出现两个磁盘失效时,阵列仍能够继续工作,不会发生数据丢失。RAID6 等级是在 RAID5 的基础上为了进一步增强数据保护而设计的一种 RAID 方式,它可以看作是一种扩展的 RAID5 等级。
总结一下单机-多磁盘的结果:

1.数据存储容量的问题。
2. 数据读写速度的问题。
RAID 根据可以使用的磁盘数量,将待写入的数据分成多片,并发同时向多块磁盘进行写入,显然写入的速度可以得到明显提高;同理,读取速度也可以得到明显提高。
3. 数据可靠性的问题。
使用 RAID 10、RAID 5 或者 RAID 6 方案的时候,由于数据有冗余存储,或者存储校验信息,所以当某块磁盘损坏的时候,可以通过其他磁盘上的数据和校验数据将丢失磁盘上的数据还原。
三、大数据分布式时代
RAID 可以看作是一种垂直伸缩,一台计算机集成更多的磁盘实现数据更大规模、更安全可靠的存储以及更快的访问速度。
不过,这只是刚起步而已。

如果说RAID是单机下磁盘的伸缩,分布式就是整机的伸缩。
拿主流的大数据技术说起,不管计算、调度框架怎么改进,底层的数据存储依然非HDFS莫属。
HDFS 技术通过添加更多的服务器实现数据更大、更快、更安全存储与访问。
RAID 技术只是在单台服务器的多块磁盘上组成阵列,大数据需要更大规模的存储空间和更快的访问速度。将 RAID 思想原理应用到分布式服务器集群上,就形成了 Hadoop 分布式文件系统 HDFS 的架构思想。
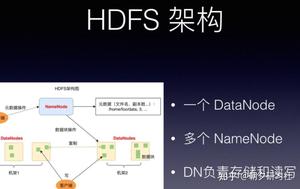
HDFS 的关键组件有两个,一个是 DataNode,一个是 NameNode。
DataNode 负责文件数据的存储和读写操作,HDFS 将文件数据分割成若干数据块(Block),每个 DataNode 存储一部分数据块,这样文件就分布存储在整个 HDFS 服务器集群中。
应用程序客户端(Client)可以并行对这些数据块进行访问,从而使得 HDFS 可以在服务器集群规模上实现数据并行访问,极大地提高了访问速度。
在实践中,HDFS 集群的 DataNode 服务器会有很多台,一般在几百台到几千台这样的规模,每台服务器配有数块磁盘,整个集群的存储容量大概在几 PB 到数百 PB。
那数据的可靠性又是怎么保证的呢?简单说明一下。
如果DataNode 监测到本机的某块磁盘损坏,就将该块磁盘上存储的所有 BlockID 报告给 NameNode,NameNode 检查这些数据块还在哪些 DataNode 上有备份,通知相应的 DataNode 服务器将对应的数据块复制到其他服务器上,以保证数据块的备份数满足要求。

其实不仅仅大数据系统中使用了上面的技术,其他的技术道理是一样的。
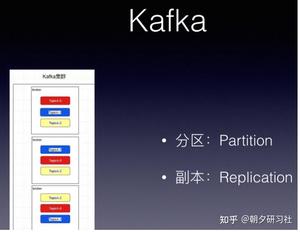
kafka有topic 还有一个概念叫Partition(分区),分区具体在服务器上面表现起初就是一个目录,一个主题下面有多个分区,这些分区会存储到不同的服务器上面,或者说,其实就是在不同的主机上建了不同的目录。
这些分区主要的信息就存在了.log文件里面。跟数据库里面的分区差不多,是为了提高性能。
kafka中的partition为了保证数据安全,所以每个partition可以设置多个副本。
而且其实每个副本都是有角色之分的,它们会选取一个副本作为leader,而其余的作为follower,我们的生产者在发送数据的时候,是直接发送到leader partition里面 ,然后follower partition会去leader那里自行同步数据,消费者消费数据的时候,也是从leader那去消费数据的 。
kafka为什么能处理上百万的数据?每一个Broker下其实也是利用磁盘的顺序写+异步+缓存等技术。
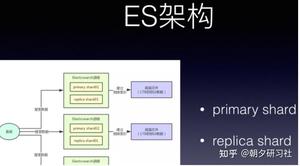
如同kafka 的 replica机制下,每个primary shard都有一个replica shard在别的机器上,任何一台机器宕机,都可以保证数据不会丢失,分布式搜索引擎继续可用。
Elasticsearch默认是支持每个index是5个primary shard,每个primary shard有1个replica shard作为副本.
管理好计算机资源主要包括两个方面,一个方面是把有限的资源使用得更有效率,另一个方面是能够使用好更多的资源。
整篇也是这个思想,压榨单机,将有限资源使用的更有效,同时利用分布式,使用更多的资源。
4月份的时候看到一道面试题,据说是腾讯校招面试官提的:在多线程和高并发环境下,如果有一个平均运行一百万次才出现一次的bug,你如何调试这个bug?知乎原贴地址如下:
腾讯实习生面试,这两道题目该怎么回答? - 编程
.
遗憾的是知乎很多答案在抨击这道题本身的正确性,虽然我不是这次的面试官,但我认为这是一道非常好的面试题。当然,只是道加分题,答不上,不扣分。答得不错,说明解决问题的思路和能力要超过应届生平均水平。
之所以写上面这段,是因为我觉得大部分后台服务端开发都有可能遇到这样的BUG,即使没有遇到,这样的题目也能够激发大家不断思考和总结。非常凑巧的是,我在4月份也遇到了一个类似的而且要更加严重的BUG,这是我自己挖的一个很深的坑,不填好,整个项目就无法上线。
现在已经过去了一个多月,趁着有时间,自己好好总结一下,希望里面提到的一些经验和工具能够带给大家一点帮助。
我们针对nginx事件框架和openssl协议栈进行了一些深度改造,以提升nginx的HTTPS完全握手计算性能。
由于原生nginx使用本地CPU做RSA计算,ECDHE_RSA算法的单核处理能力只有400 qps左右。前期测试时的并发性能很低,就算开了24核,性能也无法超过1万。
核心功能在去年底就完成了开发,线下测试也没有发现问题。经过优化后的性能提升几倍,为了测试最大性能,使用了很多客户端并发测试https性能。很快就遇到了一些问题:
- 第一个问题是nginx有极低概率(亿分之一)在不同地方 core dump。白天线下压力测试2W qps一般都要两三个小时才出一次core。每次晚上睡觉之前都会将最新的调试代码编译好并启动测试,到早上醒来第一眼就会去查看机器并祈祷不要出core,不幸的是,一般都会有几个到几十个core,并且会发现经常是在一个时间点集中core dump。线上灰度测试运行了6天,在第6天的早上才集中core dump了几十次。这样算来,这个core dump的概率至少是亿分之一了。 不过和面试题目中多线程不同的是,nginx采用的是多进程+全异步事件驱动的编程模式(目前也支持了多线程,但只是针对IO的优化,核心机制还是多进程加异步)。在webserver的实现背景下,多进程异步相比多线程的优点是性能高,没有太多线程间的切换,而且内存空间独立,省去线程间锁的竞争。当然也有缺点,就是异步模式编程非常复杂,将一些逻辑上连续的事件从空间和时间切割,不符合人的正常思考习惯,出了问题后比较难追查。另外异步事件对网络和操作系统的底层知识要求较高,稍不小心就容易挖坑。
- 第二个问题是高并发时nginx存在内存泄漏。在流量低的时候没有问题,加大测试流量就会出现内存泄漏。
- 第三个问题,因为我们对nginx和openssl的关键代码都做了一些改造,希望提升它的性能。那么如何找到性能热点和瓶颈并持续优化呢?
其中第一和第二个问题的背景都是,只有并发上万qps以上时才有可能出现,几百或者一两千QPS时,程序没有任何问题。
首先说一下core的解决思路,主要是如下几点:
- gdb及debug log定位,发现作用不大。
- 如何重现bug?
- 构造高并发压力测试系统。
- 构造稳定的异常请求。
因为有core dump ,所以这个问题初看很容易定位。gdb 找到core dump点,btrace就能知道基本的原因和上下文了。
core的直接原因非常简单和常见,全部都是NULL指针引用导致的。不过从函数上下文想不通为什么会出现NULL值,因为这些指针在原生nginx的事件和模块中都是这么使用的,不应该在这些地方变成NULL。由于暂时找不到根本原因,还是先解决CORE dump吧,修复办法也非常简单,直接判断指针是否NULL,如果是NULL就直接返回,不引用不就完事了,这个地方以后肯定不会出CORE了。
这样的防守式编程并不提倡,指针NULL引用如果不core dump,而是直接返回,那么这个错误很有可能会影响用户的访问,同时这样的BUG还不知道什么时候能暴露。所以CORE DUMP 在NULL处,其实是非常负责任和有效的做法。
在NULL处返回,确实避免了在这个地方的CORE,但是过几个小时又core 在了另外一个NULL指针引用上。于是我又继续加个判断并避免NULL指针的引用。悲剧的是,过了几个小时,又CORE在了其他地方,就这样过了几天,我一直在想为什么会出现一些指针为NULL的情况?为什么会CORE在不同地方?为什么我用浏览器和curl这样的命令工具访问却没有任何问题?
熟悉nginx代码的同学应该很清楚,nginx极少在函数入口及其他地方判断指针是否为NULL值。特别是一些关键数据结构,比如‘ngx_connection_t’及SSL_CTX等,在请求接收的时候就完成了初始化,所以不可能在后续正常处理过程中出现NULL的情况。
于是我更加迷惑,显然NULL值导致出CORE只是表象,真正的问题是,这些关键指针为什么会被赋值成NULL?
这个时候异步事件编程的缺点和复杂性就暴露了,好好的一个客户端的请求,从逻辑上应该是连续的,但是被读写及时间事件拆成了多个片断。虽然GDB能准确地记录core dump时的函数调用栈,但是却无法准确记录一条请求完整的事件处理栈。根本就不知道上次是哪个事件的哪些函数将这个指针赋值为NULL的,甚至都不知道这些数据结构上次被哪个事件使用了。
举个例子:客户端发送一个正常的get请求,由于网络或者客户端行为,需要发送两次才完成。服务端第一次read没有读取完全部数据,这次读事件中调用了 A,B函数,然后事件返回。第二次数据来临时,再次触发read事件,调用了A,C函数。并且core dump在了C函数中。这个时候,btrace的stack frame已经没有B函数调用的信息了。
所以通过GDB无法准确定位 core 的真正原因
log debug的新尝试
这时候强大的GDB已经派不上用场了。怎么办?打印nginx调试日志。
但是打印日志也很郁闷,只要将nginx的日志级别调整到DEBUG,CORE就无法重现。为什么?因为DEBUG的日志信息量非常大,频繁地写磁盘严重影响了NGINX的性能,打开DEBUG后性能由几十万直线下降到几百qps。
调整到其他级别比如 INFO,性能虽然好了,但是日志信息量太少,没有帮助。尽管如此,日志却是个很好的工具,于是又尝试过以下办法:
- 针对特定客户端IP开启debug日志,比如IP是10.1.1.1就打印DEBUG,其他IP就打印最高级别的日志,nginx本身就支持这样的配置。
- 关闭DEBUG日志,自己在一些关键路径添加高级别的调试日志,将调试信息通过EMERG级别打印出来。
- nginx只开启一个进程和少量的connection数。抽样打印连接编号(比如尾号是1)的调试日志。
总体思路依然是在不明显降低性能的前提下打印尽量详细的调试日志,遗憾的是,上述办法还是不能帮助问题定位,当然了,在不断的日志调试中,对代码和逻辑越来越熟悉。
这时候的调试效率已经很低了,几万QPS连续压力测试,几个小时才出一次CORE,然后修改代码,添加调试日志。几天过去了,毫无进展。所以必须要在线下构造出稳定的core dump环境,这样才能加快debug效率。
虽然还没有发现根本原因,但是发现了一个很可疑的地方:
出CORE比较集中,经常是在凌晨4,5点,早上7,8点的时候 dump几十个CORE。
联想到夜间有很多的网络硬件调整及故障,我猜测这些core dump可能跟网络质量相关。特别是网络瞬时不稳定,很容易触发BUG导致大量的CORE DUMP。
最开始我考虑过使用TC(traffic control)工具来构造弱网络环境,但是转念一想,弱网络环境导致的结果是什么?显然是网络请求的各种异常啊,所以还不如直接构造各种异常请求来复现问题。于是准备构造测试工具和环境,需要满足两个条件:
- 并发性能强,能够同时发送数万甚至数十万级以上qps。
- 请求需要一定概率的异常。特别是TCP握手及SSL握手阶段,需要异常中止。
traffic control是一个很好的构造弱网络环境的工具,我之前用过测试SPDY协议性能。能够控制网络速率、丢包率、延时等网络环境,作为iproute工具集中的一个工具,由linux系统自带。但比较麻烦的是TC的配置规则很复杂,facebook在tc的基础上封装成了一个开源工具apc,有兴趣的可以试试。
由于高并发流量时才可能出core,所以首先就需要找一个性能强大的压测工具。
WRK
是一款非常优秀的开源HTTP压力测试工具,采用多线程 + 异步事件驱动的框架,其中事件机制使用了redis的ae事件框架,协议解析使用了nginx的相关代码。
相比ab(apache bench)等传统压力测试工具的优点就是性能好,基本上单台机器发送几百万pqs,打满网卡都没有问题。
wrk的缺点就是只支持HTTP类协议,不支持其他协议类测试,比如protobuf,另外数据显示也不是很方便。
nginx的测试用法: wrk -t500 -c2000 -d30s https:// 127.0.0.1:8443/index.ht ml
由于是HTTPS请求,使用ECDHE_RSA密钥交换算法时,客户端的计算消耗也比较大,单机也就10000多qps。也就是说如果server的性能有3W qps,那么一台客户端是无法发送这么大的压力的,所以需要构建一个多机的分布式测试系统,即通过中控机同时控制多台测试机客户端启动和停止测试。
之前也提到了,调试效率太低,整个测试过程需要能够自动化运行,比如晚上睡觉前,可以控制多台机器在不同的协议,不同的端口,不同的cipher suite运行整个晚上。白天因为一直在盯着,运行几分钟就需要查看结果。
这个系统有如下功能:
1. 并发控制多台测试客户端的启停,最后汇总输出总的测试结果。
2. 支持https,http协议测试,支持webserver及revers proxy性能测试。
3. 支持配置不同的测试时间、端口、URL。
4. 根据端口选择不同的SSL协议版本,不同的cipher suite。
5. 根据URL选择webserver、revers proxy模式。
压力测试工具和系统都准备好了,还是不能准确复现core dump的环境。接下来还要完成异常请求的构造。构造哪些异常请求呢?
由于新增的功能代码主要是和SSL握手相关,这个过程是紧接着TCP握手发生的,所以异常也主要发生在这个阶段。于是我考虑构造了如下三种异常情形:
- 异常的tcp连接。即在客户端tcp connent系统调用时,10%概率直接close这个socket。
- 异常的ssl连接。考虑两种情况,full handshake第一阶段时,即发送 client hello时,客户端10%概率直接close连接。full handshake第二阶段时,即发送clientKeyExchange时,客户端10%概率直接直接关闭TCP连接。
- 异常的HTTPS请求,客户端10%的请求使用错误的公钥加密数据,这样nginx解密时肯定会失败。
构造好了上述高并发压力异常测试系统,果然,几秒钟之内必然出CORE。有了稳定的测试环境,那bug fix的效率自然就会快很多。
虽然此时通过gdb还是不方便定位根本原因,但是测试请求已经满足了触发CORE的条件,打开debug调试日志也能触发core dump。于是可以不断地修改代码,不断地GDB调试,不断地增加日志,一步步地追踪根源,一步步地接近真相。
最终通过不断地重复上述步骤找到了core dump的根本原因。其实在写总结文档的时候,core dump的根本原因是什么已经不太重要,最重要的还是解决问题的思路和过程,这才是值得分享和总结的。很多情况下,千辛万苦排查出来的,其实是一个非常明显甚至愚蠢的错误。
比如这次core dump的主要原因是:
由于没有正确地设置non-reusable,并发量太大时,用于异步代理计算的connection结构体被nginx回收并进行了初始化,从而导致不同的事件中出现NULL指针并出CORE。
虽然解决了core dump,但是另外一个问题又浮出了水面,就是高并发测试时,会出现内存泄漏,大概一个小时500M的样子。
出现内存泄漏或者内存问题,大家第一时间都会想到
valgrind
valgrind是一款非常优秀的软件,不需要重新编译程序就能够直接测试。功能也非常强大,能够检测常见的内存错误包括内存初始化、越界访问、内存溢出、free错误等都能够检测出来。推荐大家使用。
valgrind 运行的基本原理是:
待测程序运行在valgrind提供的模拟CPU上,valgrind会纪录内存访问及计算值,最后进行比较和错误输出
我通过valgrind测试nginx也发现了一些内存方面的错误,简单分享下valgrind测试nginx的经验:
- nginx通常都是使用master fork子进程的方式运行,使用–trace-children=yes来追踪子进程的信息
- 测试nginx + openssl时,在使用rand函数的地方会提示很多内存错误。比如Conditional jump or move depends on uninitialised value,Uninitialised value was created by a heap allocation等。这是由于rand数据需要一些熵,未初始化是正常的。如果需要去掉valgrind提示错误,编译时需要加一个选项:-DPURIFY
- 如果nginx进程较多,比如超过4个时,会导致valgrind的错误日志打印混乱,尽量减小nginx工作进程,保持为1个。因为一般的内存错误其实和进程数目都是没有关系的。
上面说了valgrind的功能和使用经验,但是valgrind也有一个非常大的缺点,就是它会显著降低程序的性能,官方文档说使用memcheck工具时,降低10-50倍
也就是说,如果nginx完全握手性能是20000 qps,那么使用valgrind测试,性能就只有400 qps左右。对于一般的内存问题,降低性能没啥影响,但是我这次的内存泄漏是在大压力测试时才可能遇到的,如果性能降低这么明显,内存泄漏的错误根本检测不出来。
只能再考虑其他办法了。
address sanitizer(简称asan)是一个用来检测c/c++程序的快速内存检测工具。相比valgrind的优点就是速度快,
官方文档
介绍对程序性能的降低只有2倍。
对Asan原理有兴趣的同学可以参考
asan的算法
这篇文章,它的实现原理就是在程序代码中插入一些自定义代码,如下:
编译前: *address = ...; // or: ... = *address; 编译后: if (IsPoisoned(address)) { ReportError(address, kAccessSize, kIsWrite); } *address = ...; // or: ... = *address;` 和valgrind明显不同的是,asan需要添加编译开关重新编译程序,好在不需要自己修改代码。而valgrind不需要编程程序就能直接运行。
address sanitizer集成在了clang编译器中,GCC 4.8版本以上才支持。我们线上程序默认都是使用gcc4.3编译,于是我测试时直接使用clang重新编译nginx:
--with-cc="clang" \ --with-cc-opt="-g -fPIC -fsanitize=address -fno-omit-frame-pointer" 其中with-cc是指定编译器,with-cc-opt指定编译选项, -fsanitize=address就是开启AddressSanitizer功能。 由于AddressSanitizer对nginx的影响较小,所以大压力测试时也能达到上万的并发,内存泄漏的问题很容易就定位了。
这里就不详细介绍内存泄漏的原因了,因为跟openssl的错误处理逻辑有关,是我自己实现的,没有普遍的参考意义。
最重要的是,知道valgrind和asan的使用场景和方法,遇到内存方面的问题能够快速修复。
到此,经过改造的nginx程序没有core dump和内存泄漏方面的风险了。但这显然不是我们最关心的结果(因为代码本该如此),我们最关心的问题是:
1. 代码优化前,程序的瓶颈在哪里?能够优化到什么程度?
2. 代码优化后,优化是否彻底?会出现哪些新的性能热点和瓶颈?
这个时候我们就需要一些工具来检测程序的性能热点。
linux世界有许多非常好用的性能分析工具,我挑选几款最常用的简单介绍下:
1. [perf](
Perf Wiki
)应该是最全面最方便的一个性能检测工具。由linux内核携带并且同步更新,基本能满足日常使用。推荐大家使用。
2.
oprofile
,我觉得是一个较过时的性能检测工具了,基本被perf取代,命令使用起来也不太方便。比如opcontrol --no-vmlinux , opcontrol --init等命令启动,然后是opcontrol --start, opcontrol --dump, opcontrol -h停止,opreport查看结果等,一大串命令和参数。有时候使用还容易忘记初始化,数据就是空的。
3.
gprof
主要是针对应用层程序的性能分析工具,缺点是需要重新编译程序,而且对程序性能有一些影响。不支持内核层面的一些统计,优点就是应用层的函数性能统计比较精细,接近我们对日常性能的理解,比如各个函数时间的运行时间,,函数的调用次数等,很人性易读。
4.
systemtap
其实是一个运行时程序或者系统信息采集框架,主要用于动态追踪,当然也能用做性能分析,功能最强大,同时使用也相对复杂。不是一个简单的工具,可以说是一门动态追踪语言。如果程序出现非常麻烦的性能问题时,推荐使用 systemtap。
这里再多介绍一下perf命令,tlinux系统上默认都有安装,比如通过perf top就能列举出当前系统或者进程的热点事件,函数的排序。
perf record能够纪录和保存系统或者进程的性能事件,用于后面的分析,比如接下去要介绍的火焰图。
perf有一个缺点就是不直观。
火焰图
就是为了解决这个问题。它能够以矢量图形化的方式显示事件热点及函数调用关系。
比如我通过如下几条命令就能绘制出原生nginx在ecdhe_rsa cipher suite下的性能热点:
- perf record -F 99 -p PID -g -- sleep 10
- perf script | https://www.zhihu.com/topic/stackcollapse-perf.pl > out.perf-folded
- https://www.zhihu.com/topic/flamegraph.pl out.perf-folded>ou.svg
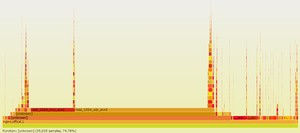
直接通过火焰图就能看到各个函数占用的百分比,比如上图就能清楚地知道rsaz_1024_mul_avx2和rsaz_1024_sqr_avx2函数占用了75%的采样比例。那我们要优化的对象也就非常清楚了,能不能避免这两个函数的计算?或者使用非本地CPU方案实现它们的计算?
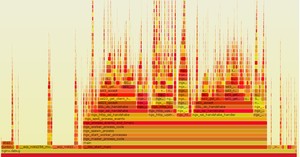
当然是可以的,我们的异步代理计算方案正是为了解决这个问题,
为了解决上面提到的core dump和内存泄漏问题,花了大概三周左右时间。压力很大,精神高度紧张, 说实话有些狼狈,看似几个很简单的问题,搞了这么长时间。心里当然不是很爽,会有些着急,特别是项目的关键上线期。但即使这样,整个过程我还是非常自信并且斗志昂扬。我一直在告诉自己:
- 调试BUG是一次非常难得的学习机会,不要把它看成是负担。不管是线上还是线下,能够主动地,高效地追查BUG特别是有难度的BUG,对自己来说一次非常宝贵的学习机会。面对这么好的学习机会,自然要充满热情,要如饥似渴,回首一看,如果不是因为这个BUG,我也不会对一些工具有更深入地了解和使用,也就不会有这篇文档的产生。
- 不管什么样的BUG,随着时间的推移,肯定是能够解决的。这样想想,其实会轻松很多,特别是接手新项目,改造复杂工程时,由于对代码,对业务一开始并不是很熟悉,需要一个过渡期。但关键是,你要把这些问题放在心上。白天上班有很多事情干扰,上下班路上,晚上睡觉前,大脑反而会更加清醒,思路也会更加清晰。特别是白天上班时容易思维定势,陷入一个长时间的误区,在那里调试了半天,结果大脑一片混沌。睡觉前或者上下班路上一个人时,反而能想出一些新的思路和办法。
- 开放地讨论。遇到问题不要不好意思,不管多简单,多低级,只要这个问题不是你google一下就能得到的结论,大胆地,认真地和组内同事讨论。这次BUG调试,有几次关键的讨论给了我很大的启发,特别是最后reusable的问题,也是组内同事的讨论才激发了我的灵感。谢谢大家的帮助。
之前收到公司一个大牛的PPT草稿,里边详细分析了一个典型的代码段在短短2~3秒钟时间内的内存访问特征。内容翔实紧凑,说的有理有据。技术类PPT的惯例,文中有几页折线图表达了整个过程中每一细微时间粒度上的内存带宽变化,扫了一眼细细密密的横坐标,一方面感慨大牛的数据之精确,另一方面忽然有了放challenge的冲动。
立即回邮件,请教如此细粒度的时间切片数据是如何抓取的。答,自己修改了PCM的源码,调小了采样间隔到50us(微秒)。再回邮件要求上代码,大牛附上了源码。我一下子推翻了整个PPT。
PCM是一个CPU/硬件级别事件监控软件。它通过硬件上集成的event counter(事件计数器)的读数变化统计需要关注的事件发生次数。过程有点像抄水表:本月用水量=这月抄表数-上月抄表数。对于PCM的实现,这个过程就变成了:读数1->sleep->读数2->计算两次读数的差->输出。
原本这两次读数之间的sleep都是秒级别,非常精准。可为什么到了50us级别这个过程就会出现问题呢?这就要从当下的非实时操作系统实现来说。
如果你有过编程基础,你可能会觉得解决这个问题的方法只要增加一个时间校准, 减少写屏、落盘就好了,然而问题又来了。
时间校准上如果采用大多数的实现,都是简单的调用glibc中 clock_gettime 。这条指令可以通过系统调用直接读取硬件时钟的数据,纳秒级别的精度按理说已经是足够高了。不过里边还有一个坑。
虚拟文件:/sys/devices/system/clocksource/clocksource0/current_clocksource 是当前的系统默认时钟源的设定,往往都会有几种可用的时钟可选。比如我这台主机可以使用 TSC(Time Stamp Counter),HPET(High Precision Event Timer),ACPI PM Timer(ACPI Power Management Timer) 3个时钟源,默认使用的是TSC。要知道3种硬件时钟的调用方式是不同的,调用时延也是几何倍数的。其中TSC代价较低,简单的指令返回,100 cycle左右,大约60ns可以完成调用;而hpet则是通过内存映射方式的调用,至少2倍内存延时,超过500ns;啥,ACPI?好吧,作为PCH的组件,ACPI需要通过PCIe bus完成内存地址映射,这个过程相当于读取网卡、SSD,微秒级别的操作了!
坑的是在不同的主机版本、内核设置上,硬件时钟源的设定是不同的。一般Kernel会优先使用TSC,一旦kernel“觉得tsc有问题”,比如从刚从休眠唤醒或者调整频率之后,就会切换到HPET时钟。
最后,你要是接触过event count特别是uncore部分的event counter编程,你就会知道真正的问题在其实在这里:计算内存带宽如果用到了UNC_M_CAS_COUNT.RD之类的内存读写操作计数器。那又会一头撞死在PCIe bus这个“低速通道”上——这些计数器的访问事实上不是CPU核心上的计数器(即无法通过一条CPU指令简单的读取数据),它是通过一个虚拟的PCIe设备进行内存地址映射之后再访问的!之前已经提到了,这是一个需要用us级别访问的通道……
话说到这里,你也许会问我的最终实现方法,肯定不是通过uncore了。这里不做阐述,欢迎私聊!
其实挺想吐槽的,一个常年研究硬件架构的大牛尚且在关键的数据采集上犯了这么大的错误。这些年,所谓高性能高并发、微秒级响应、C25K甚至C100K 困境为啥在某些人嘴里仿佛就成了hello word级别难度?(new update:一起为“基本的科学(Base Science,简称BS)训练”的定义点赞!如果从BS的角度来看,我这样说这里这么说真的是欠妥甚至都读出了针对性,我光看常识是不对的,特地修改为严谨的说法:“觉得20行代码就能实现TCPserver,那就现在的C100K就真的是helloworld,没毛病!——该双击666了吧?”)传统上对于一个最小调度时间片是3ms的话意味着单核心只能响应300连接每秒,就算对于100个CPU core的主机来说,光是建立连接这30K的TCP链接就是系统的极限了,更别谈什么数据读写处理。
从CPU的眼光讲讲时间的概念,给大家一个各种时延的参照:
- 对于2.0GHz的CPU来说,一个cycle大约是0.5ns。从L1/L2/L3读数据分别需要3/15/45个cycle。
- 访问内存 >150ns,这是300个cycle。
- SSD或者网卡的读取 >150us, 这是 个cycle。
- 一次内网微服务请求 5ms,这是个cycle。
- 一次网页响应 1.5s 这是个cycle
- ……
- 光速在一个cycle之内只能传输15厘米。(30万公里/秒=30 000 000 000 厘米/秒 = 30厘米/纳秒)
--原文于2019/06/04发布于
高性能编程的困境 - 开源小站
--Update 2019/6/29 (阅读难度201)
传统上对于一个最小调度时间片是3ms的话意味着单核心只能响应300连接每秒,就算对于100个CPU core的主机来说,光是建立连接这30K的TCP链接就是系统的极限了,更别谈什么数据读写处理。
写这句话的时候,想着找个101级别的例子描述高性能系统的难度。并没有意识到这句话会偏离全文主题而且成了质疑的焦点,但既然有质疑,说明各位已经读懂了我的主题,非常感谢各位——包括友好的和不友好的。
感谢评论中@enpeng xu 提到的IO polling和中断两部分内核态部分的内容,我非常认同!我在最开始的时候确实没有考虑设备轮询以及中断的对这个例子影响,或者说我在考虑这个例子的时候根本没考虑到内核态。另外,在异步非阻塞、边缘触发模型甚至轻量化线程已经是主流实现方法的今天,提传统实现确实会有歧义。比如,尽管现在说起一个thread/process维护一个connection的操作是很荒唐,但Blocking IO/non-blocking IO却是TCPserver很长一段时间的传统,且即使在当下,在整个调用栈的实现上,线程级以上的事务隔离也不是能够被完全避免——认为这是我在狡辩没关系,如果大家感兴趣可以考虑下这两种模型的理论性能,以及中断会对这些模型产生什么样的影响。
---
update 19/07/07,关于最终实现(阅读难度301+),捎带回评论:
- 时间计算的主要问题是系统调用返回的时间来源不可知,既然TSC是开销最小的,那就直接写指定CPU core的rdtsc指令就好,当然测试的时候频率/cstat必须要锁死,这是BIOS里的开关就能做到的。
- 内存的访问是固定在逻辑内存地址到物理内存地址(phycial memory address),CHA(cache and home agent and cbox),iMC (intergrated memory controller)的一系列映射关系上,也就是说x86不具备为某个特定地址指定内存控制器的能力(我个人更相信任何一个具备物理内存地址映射的平台都不得不照限制此实现,不多解释),对应可以参考我之前的专栏文章。但大多数应用包含测试样本中所有内存访问的前提是L3-cache-miss,而这个数值是一个可以通过rdpmc指令获取的 Core hardware event,预期返回时间在50ns以下。了解CPU cache line工作原理的同学应该明白CPU对内存的访问是cache line 64byte对齐的。虽然rdpmc只能工作在ring0,但有几个walk around可以让rdpmc在user space(ring3)下工作,在Intel SDM上可以查阅到方法[1]。
简单讲,要完成上下文切换粒度以下的应用特征抓取就不能太期待系统调用给到靠谱的数据,rdtsc/rdpmc都是需要通过汇编绕过OS实现的。同时要严格控制测试核心的上下文切换和中断处理。较真起来,上下文切换操作本身就是一个不可预知的操作。
• In general, the indirect cost of context switch ranges from several microseconds to more than one thousand microseconds for our workload. [2]
点赞再看,养成习惯,微信搜索【 敖丙】第一时间阅读。
本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试完整考点、资料以及我的系列文章。
多线程的东西很多,也很有意思,所以我最近的重心可能都是多线程的方向去靠了,不知道大家喜欢否?
阅读本文之前阅读以下两篇文章会帮助你更好的理解:
Volatile
乐观锁&悲观锁
我们正常去使用Synchronized一般都是用在下面这几种场景:
- 修饰实例方法,对当前实例对象this加锁
public class Synchronized {
public synchronized void husband(){
}
}
- 修饰静态方法,对当前类的Class对象加锁
public class Synchronized {
public void husband(){
synchronized(Synchronized.class){
}
}
}
- 修饰代码块,指定一个加锁的对象,给对象加锁
public class Synchronized {
public void husband(){
synchronized(new test()){
}
}
}
其实就是锁方法、锁代码块和锁对象,那他们是怎么实现加锁的呢?
在这之前,我就先跟大家聊一下我们Java对象的构成
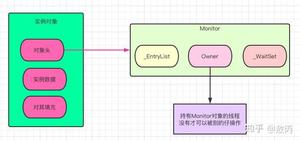
在 JVM 中,对象在内存中分为三块区域:
- 对象头
- Mark Word(标记字段):默认存储对象的HashCode,分代年龄和锁标志位信息。它会根据对象的状态复用自己的存储空间,也就是说在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。
- Klass Point(类型指针):对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
- 实例数据
- 这部分主要是存放类的数据信息,父类的信息。
- 对其填充
- 由于虚拟机要求对象起始地址必须是8字节的整数倍,填充数据不是必须存在的,仅仅是为了字节对齐。
Tip:不知道大家有没有被问过一个空对象占多少个字节?就是8个字节,是因为对齐填充的关系哈,不到8个字节对其填充会帮我们自动补齐。
我们经常说到的,有序性、可见性、原子性,synchronized又是怎么做到的呢?
我在Volatile章节已经说过了CPU会为了优化我们的代码,会对我们程序进行重排序。
不管编译器和CPU如何重排序,必须保证在单线程情况下程序的结果是正确的,还有就是有数据依赖的也是不能重排序的。
就比如:
int a = 1; int b = a; 这两段是怎么都不能重排序的,b的值依赖a的值,a如果不先赋值,那就为空了。
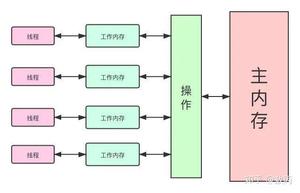
同样在Volatile章节我介绍到了现代计算机的内存结构,以及JMM(Java内存模型),这里我需要说明一下就是JMM并不是实际存在的,而是一套规范,这个规范描述了很多java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取变量这样的底层细节,Java内存模型是对共享数据的可见性、有序性、和原子性的规则和保障。
大家感兴趣,也记得去了解计算机的组成部分,cpu、内存、多级缓存等,会帮助更好的理解java这么做的原因。
其实他保证原子性很简单,确保同一时间只有一个线程能拿到锁,能够进入代码块这就够了。
这几个是我们使用锁经常用到的特性,那synchronized他自己本身又具有哪些特性呢?
synchronized锁对象的时候有个计数器,他会记录下线程获取锁的次数,在执行完对应的代码块之后,计数器就会-1,直到计数器清零,就释放锁了。
那可重入有什么好处呢?
可以避免一些死锁的情况,也可以让我们更好封装我们的代码。
不可中断就是指,一个线程获取锁之后,另外一个线程处于阻塞或者等待状态,前一个不释放,后一个也一直会阻塞或者等待,不可以被中断。
值得一提的是,Lock的tryLock方法是可以被中断的。
这里看实现很简单,我写了一个简单的类,分别有锁方法和锁代码块,我们反编译一下字节码文件,就可以了。
先看看我写的测试类:
/ *@Description: Synchronize *@Author: 敖丙 *@date: 2020-05-17 / public class Synchronized { public synchronized void husband(){ synchronized(new Volatile()){ } } } 编译完成,我们去对应目录执行 javap -c xxx.class 命令查看反编译的文件:
MacBook-Pro-3:juc aobing$ javap -p -v -c Synchronized.class Classfile /Users/aobing/IdeaProjects/Thanos/laogong/target/classes/juc/Synchronized.class Last modified 2020-5-17; size 375 bytes MD5 checksum 4f5451a229e80c0a6045bd1a Compiled from "Synchronized.java" public class juc.Synchronized minor version: 0 major version: 49 flags: ACC_PUBLIC, ACC_SUPER Constant pool: #1 = Methodref #3.#14 // java/lang/Object."<init>":()V #2 = Class #15 // juc/Synchronized #3 = Class #16 // java/lang/Object #4 = Utf8 <init> #5 = Utf8 ()V #6 = Utf8 Code #7 = Utf8 LineNumberTable #8 = Utf8 LocalVariableTable #9 = Utf8 this #10 = Utf8 Ljuc/Synchronized; #11 = Utf8 husband #12 = Utf8 SourceFile #13 = Utf8 Synchronized.java #14 = NameAndType #4:#5 // "<init>":()V #15 = Utf8 juc/Synchronized #16 = Utf8 java/lang/Object { public juc.Synchronized(); descriptor: ()V flags: ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return LineNumberTable: line 8: 0 LocalVariableTable: Start Length Slot Name Signature 0 5 0 this Ljuc/Synchronized; public synchronized void husband(); descriptor: ()V flags: ACC_PUBLIC, ACC_SYNCHRONIZED // 这里 Code: stack=2, locals=3, args_size=1 0: ldc #2 // class juc/Synchronized 2: dup 3: astore_1 4: monitorenter // 这里 5: aload_1 6: monitorexit // 这里 7: goto 15 10: astore_2 11: aload_1 12: monitorexit // 这里 13: aload_2 14: athrow 15: return Exception table: from to target type 5 7 10 any 10 13 10 any LineNumberTable: line 10: 0 line 12: 5 line 13: 15 LocalVariableTable: Start Length Slot Name Signature 0 16 0 this Ljuc/Synchronized; } SourceFile: "Synchronized.java" 大家可以看到几处我标记的,我在最开始提到过对象头,他会关联到一个monitor对象。
- 当我们进入一个人方法的时候,执行monitorenter,就会获取当前对象的一个所有权,这个时候monitor进入数为1,当前的这个线程就是这个monitor的owner。
- 如果你已经是这个monitor的owner了,你再次进入,就会把进入数+1.
- 同理,当他执行完monitorexit,对应的进入数就-1,直到为0,才可以被其他线程持有。
所有的互斥,其实在这里,就是看你能否获得monitor的所有权,一旦你成为owner就是获得者。
不知道大家注意到方法那的一个特殊标志位没,ACC_SYNCHRONIZED。
同步方法的时候,一旦执行到这个方法,就会先判断是否有标志位,然后,ACC_SYNCHRONIZED会去隐式调用刚才的两个指令:monitorenter和monitorexit。
所以归根究底,还是monitor对象的争夺。
我说了这么多次这个对象,大家是不是以为就是个虚无的东西,其实不是,monitor监视器源码是C++写的,在虚拟机的ObjectMonitor.hpp文件中。
我看了下源码,他的数据结构长这样:
ObjectMonitor() { _header = NULL; _count = 0; _waiters = 0, _recursions = 0; // 线程重入次数 _object = NULL; // 存储Monitor对象 _owner = NULL; // 持有当前线程的owner _WaitSet = NULL; // wait状态的线程列表 _WaitSetLock = 0 ; _Responsible = NULL ; _succ = NULL ; _cxq = NULL ; // 单向列表 FreeNext = NULL ; _EntryList = NULL ; // 处于等待锁状态block状态的线程列表 _SpinFreq = 0 ; _SpinClock = 0 ; OwnerIsThread = 0 ; _previous_owner_tid = 0; } 这块c++代码,我也放到了我的开源项目了,大家自行查看。
synchronized底层的源码就是引入了ObjectMonitor,这一块大家有兴趣可以看看,反正我上面说的,还有大家经常听到的概念,在这里都能找到源码。

大家说熟悉的锁升级过程,其实就是在源码里面,调用了不同的实现去获取获取锁,失败就调用更高级的实现,最后升级完成。
大家在看ObjectMonitor源码的时候,会发现Atomic::cmpxchg_ptr,Atomic::inc_ptr等内核函数,对应的线程就是park()和upark()。
这个操作涉及用户态和内核态的转换了,这种切换是很耗资源的,所以知道为啥有自旋锁这样的操作了吧,按道理类似死循环的操作更费资源才是对吧?其实不是,大家了解一下就知道了。
Linux系统的体系结构大家大学应该都接触过了,分为用户空间(应用程序的活动空间)和内核。
我们所有的程序都在用户空间运行,进入用户运行状态也就是(用户态),但是很多操作可能涉及内核运行,比我I/O,我们就会进入内核运行状态(内核态)。
这个过程是很复杂的,也涉及很多值的传递,我简单概括下流程:
- 用户态把一些数据放到寄存器,或者创建对应的堆栈,表明需要操作系统提供的服务。
- 用户态执行系统调用(系统调用是操作系统的最小功能单位)。
- CPU切换到内核态,跳到对应的内存指定的位置执行指令。
- 系统调用处理器去读取我们先前放到内存的数据参数,执行程序的请求。
- 调用完成,操作系统重置CPU为用户态返回结果,并执行下个指令。
所以大家一直说,1.6之前是重量级锁,没错,但是他重量的本质,是ObjectMonitor调用的过程,以及Linux内核的复杂运行机制决定的,大量的系统资源消耗,所以效率才低。
还有两种情况也会发生内核态和用户态的切换:异常事件和外围设备的中断 大家也可以了解下。
那都说过了效率低,官方也是知道的,所以他们做了升级,大家如果看了我刚才提到的那些源码,就知道他们的升级其实也做得很简单,只是多了几个函数调用,不过不得不设计还是很巧妙的。
我们就来看一下升级后的锁升级过程:
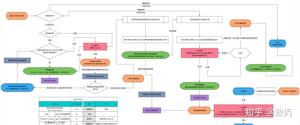
简单版本:
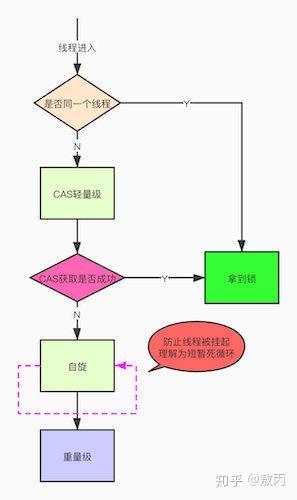
升级方向:

Tip:切记这个升级过程是不可逆的,最后我会说明他的影响,涉及使用场景。
看完他的升级,我们就来好好聊聊每一步怎么做的吧。
之前我提到过了,对象头是由Mark Word和Klass pointer 组成,锁争夺也就是对象头指向的Monitor对象的争夺,一旦有线程持有了这个对象,标志位修改为1,就进入偏向模式,同时会把这个线程的ID记录在对象的Mark Word中。
这个过程是采用了CAS乐观锁操作的,每次同一线程进入,虚拟机就不进行任何同步的操作了,对标志位+1就好了,不同线程过来,CAS会失败,也就意味着获取锁失败。
偏向锁在1.6之后是默认开启的,1.5中是关闭的,需要手动开启参数是xx:-UseBiasedLocking=false。
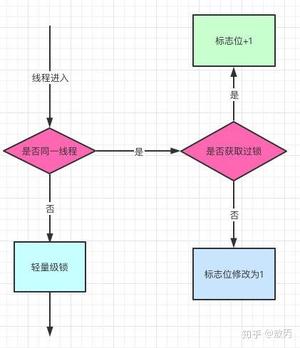
偏向锁关闭,或者多个线程竞争偏向锁怎么办呢?
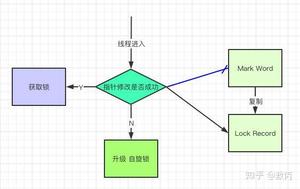
还是跟Mark Work 相关,如果这个对象是无锁的,jvm就会在当前线程的栈帧中建立一个叫锁记录(Lock Record)的空间,用来存储锁对象的Mark Word 拷贝,然后把Lock Record中的owner指向当前对象。
JVM接下来会利用CAS尝试把对象原本的Mark Word 更新会Lock Record的指针,成功就说明加锁成功,改变锁标志位,执行相关同步操作。
如果失败了,就会判断当前对象的Mark Word是否指向了当前线程的栈帧,是则表示当前的线程已经持有了这个对象的锁,否则说明被其他线程持有了,继续锁升级,修改锁的状态,之后等待的线程也阻塞。
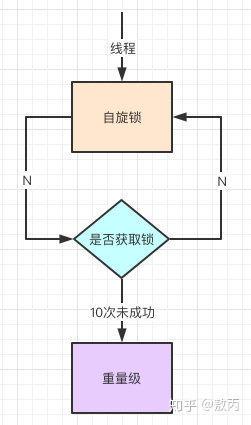
我不是在上面提到了Linux系统的用户态和内核态的切换很耗资源,其实就是线程的等待唤起过程,那怎么才能减少这种消耗呢?
自旋,过来的现在就不断自旋,防止线程被挂起,一旦可以获取资源,就直接尝试成功,直到超出阈值,自旋锁的默认大小是10次,-XX:PreBlockSpin可以修改。
自旋都失败了,那就升级为重量级的锁,像1.5的一样,等待唤起咯。
至此我基本上吧synchronized的前后概念都讲到了,大家好好消化。
资料参考:《高并发编程》《黑马程序员讲义》《深入理解JVM虚拟机》
我们先看看他们的区别:
- synchronized是关键字,是JVM层面的底层啥都帮我们做了,而Lock是一个接口,是JDK层面的有丰富的API。
- synchronized会自动释放锁,而Lock必须手动释放锁。
- synchronized是不可中断的,Lock可以中断也可以不中断。
- 通过Lock可以知道线程有没有拿到锁,而synchronized不能。
- synchronized能锁住方法和代码块,而Lock只能锁住代码块。
- Lock可以使用读锁提高多线程读效率。
- synchronized是非公平锁,ReentrantLock可以控制是否是公平锁。
两者一个是JDK层面的一个是JVM层面的,我觉得最大的区别其实在,我们是否需要丰富的api,还有一个我们的场景。
比如我现在是滴滴,我早上有打车高峰,我代码使用了大量的synchronized,有什么问题?锁升级过程是不可逆的,过了高峰我们还是重量级的锁,那效率是不是大打折扣了?这个时候你用Lock是不是很好?
场景是一定要考虑的,我现在告诉你哪个好都是扯淡,因为脱离了业务,一切技术讨论都没有了价值。
我是敖丙,一个在互联网苟且偷生的工具人。
你知道的越多,你不知道的越多,人才们的 【三连】 就是丙丙创作的最大动力,我们下期见!
注:如果本篇博客有任何错误和建议,欢迎人才们留言!
文章持续更新,可以微信搜索「 敖丙 」第一时间阅读,有我准备的一线大厂面试资料和简历模板,本文 GitHub https://github.com/JavaFamily 已经收录,有大厂面试完整考点,欢迎Star。
作为程序员,想必你多多少少听过协程这个词,这项技术近年来越来越多的出现在程序员的视野当中,尤其高性能高并发领域。当你的同学、同事提到协程时如果你的大脑一片空白,对其毫无概念。。。

那么这篇文章正是为你量身打造的。
话不多说,今天的主题就是作为程序员,你应该如何彻底理解协程。
我们先来看一个普通的函数,这个函数非常简单:
def func(): print("a") print("b") print("c")这是一个简单的普通函数,当我们调用这个函数时会发生什么?
- 调用func
- func开始执行,直到return
- func执行完成,返回函数A
是不是很简单,函数func执行直到返回,并打印出:
a b cSo easy,有没有,有没有!

很好!
注意这段代码是用python写的,但本篇关于协程的讨论适用于任何一门语言,我们只不过恰好使用了python来用作示例,因为其足够简单。
那么协程是什么呢?
接下来,我们就要从普通函数过渡到协程了。
和普通函数只有一个返回点不同,协程可以有多个返回点。
这是什么意思呢?
void func() { print("a") 暂停并返回 print("b") 暂停并返回 print("c") }普通函数下,只有当执行完print("c")这句话后函数才会返回,但是在协程下当执行完print("a")后func就会因“暂停并返回”这段代码返回到调用函数。
有的同学可能会一脸懵逼,这有什么神奇的吗?我写一个return也能返回,就像这样:
void func() { print("a") return print("b") 暂停并返回 print("c") }直接写一个return语句确实也能返回,但这样写的话return后面的代码都不会被执行到了。
协程之所以神奇就神奇在当我们从协程返回后还能继续调用该协程,并且是从该协程的上一个返回点后继续执行。
这足够神奇吧,就好比孙悟空说一声“定”,函数就被暂停了:
void func() { print("a") 定 print("b") 定 print("c") }这时我们就可以返回到调用函数,当调用函数什么时候想起该协程后可以再次调用该协程,该协程会从上一个返回点继续执行。
Amazing,有没有,集中注意力,千万不要翻车

只不过孙大圣使用的口诀“定”字,在编程语言中一般叫做yield(其它语言中可能会有不同的实现,但本质都是一样的)。
需要注意的是,当普通函数返回后,进程的地址空间中不会再保存该函数运行时的任何信息,而协程返回后,函数的运行时信息是需要保存下来的,那么函数的运行时状态到底在内存中是什么样子呢,关于这个问题你可以参考这里。
接下来,我们就用实际的代码看一看协程。
下面我们使用一个真实的例子来讲解,语言采用python,不熟悉的同学不用担心,这里不会有理解上的门槛。
在python语言中,这个“定”字同样使用关键词yield,这样我们的func函数就变成了:
void func() { print("a") yield print("b") yield print("c") }注意,这时我们的func就不再是简简单单的函数了,而是升级成为了协程,那么我们该怎么使用呢,很简单:
1 def A(): 2 co = func() # 得到该协程 3 next(co) # 调用协程 4 print("in function A") # do something 5 next(co) # 再次调用该协程我们看到虽然func函数没有return语句,也就是说虽然没有返回任何值,但是我们依然可以写co = func()这样的代码,意思是说co就是我们拿到的协程了。
接下来我们调用该协程,使用next(co),运行函数A看看执行到第3行的结果是什么:
a显然,和我们的预期一样,协程func在print("a")后因执行yield而暂停并返回函数A。
接下来是第4行,这个毫无疑问,A函数在做一些自己的事情,因此会打印:
a in functino A接下来是重点的一行,当执行第5行再次调用协程时该打印什么呢?
如果func是普通函数,那么会执行func的第一行代码,也就是打印a。
但func不是普通函数,而是协程,我们之前说过,协程会在上一个返回点继续运行,因此这里应该执行的是func函数第一个yield之后的代码,也就是print("b")。
a in functino A b看到了吧,协程是一个很神奇的函数,它会自己记住之前的执行状态,当再次调用时会从上一次的返回点继续执行。
为了让你更加彻底的理解协程,我们使用图形化的方式再看一遍,首先是普通的函数调用:
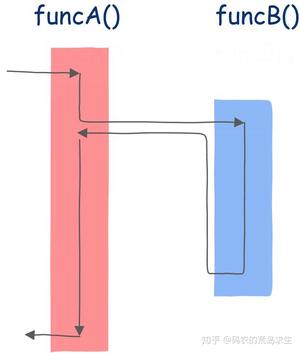
在该图中,方框内表示该函数的指令序列,如果该函数不调用任何其它函数,那么应该从上到下依次执行,但函数中可以调用其它函数,因此其执行并不是简单的从上到下,箭头线表示执行流的方向。
从图中我们可以看到,我们首先来到funcA函数,执行一段时间后发现调用了另一个函数funcB,这时控制转移到该函数,执行完成后回到main函数的调用点继续执行。
这是普通的函数调用。
接下来是协程。
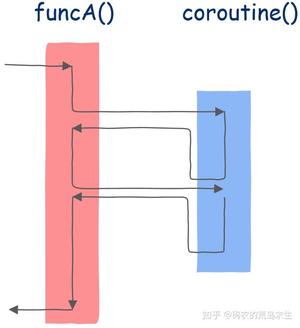
在这里,我们依然首先在funcA函数中执行,运行一段时间后调用协程,协程开始执行,直到第一个挂起点,此后就像普通函数一样返回funcA函数,funcA函数执行一些代码后再次调用该协程,注意,协程这时就和普通函数不一样了,协程并不是从第一条指令开始执行而是从上一次的挂起点开始执行,执行一段时间后遇到第二个挂起点,这时协程再次像普通函数一样返回funcA函数,funcA函数执行一段时间后整个程序结束。
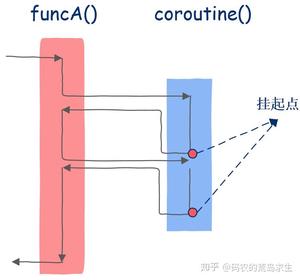
怎么样,神奇不神奇,和普通函数不同的是,协程能知道自己上一次执行到了哪里。
现在你应该明白了吧,协程会在函数被暂停运行时保存函数的运行状态,并可以从保存的状态中恢复并继续运行。
很熟悉的味道有没有,这不就是操作系统对线程的调度嘛,线程也可以被暂停,操作系统保存线程运行状态然后去调度其它线程,此后该线程再次被分配CPU时还可以继续运行,就像没有被暂停过一样。
只不过线程的调度是操作系统实现的,这些对程序员都不可见,而协程是在用户态实现的,对程序员可见。
这就是为什么有的人说可以把协程理解为用户态线程的原因。
此处应该有掌声。

也就是说现在程序员可以扮演操作系统的角色了,你可以自己控制协程在什么时候运行,什么时候暂停,也就是说协程的调度权在你自己手上。
在协程这件事儿上,调度你说了算。
当你在协程中写下yield的时候就是想要暂停改协程,当使用next()时就是要再次运行该协程。
现在你应该理解为什么说函数只是协程的一种特例了吧,函数其实只是没有挂起点的协程而已。
有的同学可能认为协程是一种比较新的技术,然而其实协程这种概念早在1958就已经提出来了,要知道这时线程的概念都还没有提出来。
到了1972年,终于有编程语言实现了这个概念,这两门编程语言就是Simula 67 以及Scheme。

但协程这个概念始终没有流行起来,甚至在1993年还有人考古一样专门写论文挖出协程这种古老的技术。
因为这一时期还没有线程,如果你想在操作系统写出并发程序那么你将不得不使用类似协程这样的技术,后来线程开始出现,操作系统终于开始原生支持程序的并发执行,就这样,协程逐渐淡出了程序员的视线。
直到近些年,随着互联网的发展,尤其是移动互联网时代的到来,服务端对高并发的要求越来越高,协程再一次重回技术主流,各大编程语言都已经支持或计划开始支持协程。
那么协程到底是如何实现的呢?
让我们从问题的本质出发来思考这个问题。
协程的本质是什么呢?
其实就是可以被暂停以及可以被恢复运行的函数。
那么可以被暂停以及可以被恢复意味着什么呢?
看过篮球比赛的同学相比都知道,篮球比赛也是可以被随时暂停的,暂停时大家需要记住球在哪一方,各自的站位是什么,等到比赛继续的时候大家回到各自的位置,裁判哨子一响比赛继续,就像比赛没有被暂停过一样。

看到问题的关键了吗,比赛之所以可以被暂停也可以继续是因为比赛状态被记录下来了(站位、球在哪一方),这里的状态就是计算机科学中常说的上下文,context。
回到协程。
协程之所以可以被暂停也可以继续,那么一定要记录下被暂停时的状态,也就是上下文,当继续运行的时候要恢复其上下文(状态),那么接下来很自然的一个问题就是,函数运行时的状态是什么?
这个关键的问题的答案就在
码农的荒岛求生:函数运行时在内存中是什么样子?
这篇文章中,函数运行时所有的状态信息都位于函数运行时栈中。
函数运行时栈就是我们需要保存的状态,也就是所谓的上下文,如图所示:
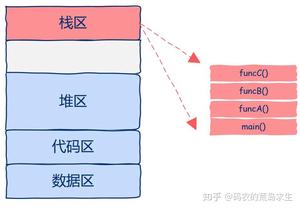
从图中我们可以看出,该进程中只有一个线程,栈区中有四个栈帧,main函数调用A函数,A函数调用B函数,B函数调用C函数,当C函数在运行时整个进程的状态就如图所示。
现在我们已经知道了函数的运行时状态就保存在栈区的栈帧中,接下来重点来了哦。
既然函数的运行时状态保存在栈区的栈帧中,那么如果我们想暂停协程的运行就必须保存整个栈帧的数据,那么我们该将整个栈帧中的数据保存在哪里呢?
想一想这个问题,整个进程的内存区中哪一块是专门用来长时间(进程生命周期)存储数据的?是不是大脑又一片空白了?

先别空白!
很显然,这就是堆区啊,heap,我们可以将栈帧保存在堆区中,那么我们该怎么在堆区中保存数据呢?希望你还没有晕,在堆区中开辟空间就是我们常用的C语言中的malloc或者C++中的new。
我们需要做的就是在堆区中申请一段空间,让后把协程的整个栈区保存下,当需要恢复协程的运行时再从堆区中copy出来恢复函数运行时状态。
再仔细想一想,为什么我们要这么麻烦的来回copy数据呢?
实际上,我们需要做的是直接把协程的运行需要的栈帧空间直接开辟在堆区中,这样都不用来回copy数据了,如图所示。
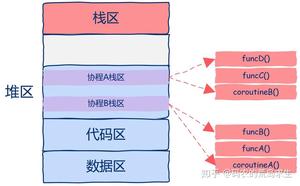
从图中我们可以看到,该程序中开启了两个协程,这两个协程的栈区都是在堆上分配的,这样我们就可以随时中断或者恢复协程的执行了。
有的同学可能会问,那么进程地址空间最上层的栈区现在的作用是什么呢?
这一区域依然是用来保存函数栈帧的,只不过这些函数并不是运行在协程而是普通线程中的。
现在你应该看到了吧,在上图中实际上有3个执行流:
- 一个普通线程
- 两个协程
虽然有3个执行流但我们创建了几个线程呢?
一个线程。
现在你应该明白为什么要使用协程了吧,使用协程理论上我们可以开启无数并发执行流,只要堆区空间足够,同时还没有创建线程的开销,所有协程的调度、切换都发生在用户态,这就是为什么协程也被称作用户态线程的原因所在。
掌声在哪里?

因此即使你创建了N多协程,但在操作系统看来依然只有一个线程,也就是说协程对操作系统来说是不可见的。
这也许是为什么协程这个概念比线程提出的要早的原因,可能是写普通应用的程序员比写操作系统的程序员最先遇到需要多个并行流的需求,那时可能都还没有操作系统的概念,或者操作系统没有并行这种需求,所以非操作系统程序员只能自己动手实现执行流,也就是协程。
现在你应该对协程有一个清晰的认知了吧。

到这里你应该已经理解协程到底是怎么一回事,但是,依然有一个问题没有解决,为什么协程这种技术又一次重回视线,协程适用于什么场景下呢?该怎么使用呢?
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:艾小仙
链接: 《我想进大厂》之MQ夺命连环11问
来源:微信公众号
mq的作用很简单,削峰填谷。以电商交易下单的场景来说,正向交易的过程可能涉及到创建订单、扣减库存、扣减活动预算、扣减积分等等。每个接口的耗时如果是100ms,那么理论上整个下单的链路就需要耗费400ms,这个时间显然是太长了。

如果这些操作全部同步处理的话,首先调用链路太长影响接口性能,其次分布式事务的问题很难处理,这时候像扣减预算和积分这种对实时一致性要求没有那么高的请求,完全就可以通过mq异步的方式去处理了。同时,考虑到异步带来的不一致的问题,我们可以通过job去重试保证接口调用成功,而且一般公司都会有核对的平台,比如下单成功但是未扣减积分的这种问题可以通过核对作为兜底的处理方案。
使用mq之后我们的链路变简单了,同时异步发送消息我们的整个系统的抗压能力也上升了。
我们主要调研了几个主流的mq,kafka、rabbitmq、rocketmq、activemq,选型我们主要基于以下几个点去考虑:
- 由于我们系统的qps压力比较大,所以性能是首要考虑的要素。
- 开发语言,由于我们的开发语言是java,主要是为了方便二次开发。
- 对于高并发的业务场景是必须的,所以需要支持分布式架构的设计。
- 功能全面,由于不同的业务场景,可能会用到顺序消息、事务消息等。
基于以上几个考虑,我们最终选择了RocketMQ。

消息丢失可能发生在生产者发送消息、MQ本身丢失消息、消费者丢失消息3个方面。
生产者丢失消息的可能点在于程序发送失败抛异常了没有重试处理,或者发送的过程成功但是过程中网络闪断MQ没收到,消息就丢失了。
由于同步发送的一般不会出现这样使用方式,所以我们就不考虑同步发送的问题,我们基于异步发送的场景来说。
异步发送分为两个方式:异步有回调和异步无回调,无回调的方式,生产者发送完后不管结果可能就会造成消息丢失,而通过异步发送+回调通知+本地消息表的形式我们就可以做出一个解决方案。以下单的场景举例。
- 下单后先保存本地数据和MQ消息表,这时候消息的状态是发送中,如果本地事务失败,那么下单失败,事务回滚。
- 下单成功,直接返回客户端成功,异步发送MQ消息
- MQ回调通知消息发送结果,对应更新数据库MQ发送状态
- JOB轮询超过一定时间(时间根据业务配置)还未发送成功的消息去重试
- 在监控平台配置或者JOB程序处理超过一定次数一直发送不成功的消息,告警,人工介入。
一般而言,对于大部分场景来说异步回调的形式就可以了,只有那种需要完全保证不能丢失消息的场景我们做一套完整的解决方案。
如果生产者保证消息发送到MQ,而MQ收到消息后还在内存中,这时候宕机了又没来得及同步给从节点,就有可能导致消息丢失。
比如RocketMQ:
RocketMQ分为同步刷盘和异步刷盘两种方式,默认的是异步刷盘,就有可能导致消息还未刷到硬盘上就丢失了,可以通过设置为同步刷盘的方式来保证消息可靠性,这样即使MQ挂了,恢复的时候也可以从磁盘中去恢复消息。
比如Kafka也可以通过配置做到:
acks=all 只有参与复制的所有节点全部收到消息,才返回生产者成功。这样的话除非所有的节点都挂了,消息才会丢失。 replication.factor=N,设置大于1的数,这会要求每个partion至少有2个副本 min.insync.replicas=N,设置大于1的数,这会要求leader至少感知到一个follower还保持着连接 retries=N,设置一个非常大的值,让生产者发送失败一直重试 虽然我们可以通过配置的方式来达到MQ本身高可用的目的,但是都对性能有损耗,怎样配置需要根据业务做出权衡。
消费者丢失消息的场景:消费者刚收到消息,此时服务器宕机,MQ认为消费者已经消费,不会重复发送消息,消息丢失。
RocketMQ默认是需要消费者回复ack确认,而kafka需要手动开启配置关闭自动offset。
消费方不返回ack确认,重发的机制根据MQ类型的不同发送时间间隔、次数都不尽相同,如果重试超过次数之后会进入死信队列,需要手工来处理了。(Kafka没有这些)
因为考虑到时消费者消费一直出错的问题,那么我们可以从以下几个角度来考虑:
- 消费者出错,肯定是程序或者其他问题导致的,如果容易修复,先把问题修复,让consumer恢复正常消费
- 如果时间来不及处理很麻烦,做转发处理,写一个临时的consumer消费方案,先把消息消费,然后再转发到一个新的topic和MQ资源,这个新的topic的机器资源单独申请,要能承载住当前积压的消息
- 处理完积压数据后,修复consumer,去消费新的MQ和现有的MQ数据,新MQ消费完成后恢复原状
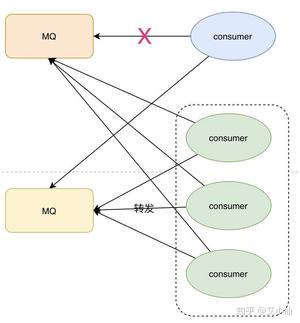
这。。。他妈都删除了我有啥办法啊。。。冷静,再想想。。有了。
最初,我们发送的消息记录是落库保存了的,而转发发送的数据也保存了,那么我们就可以通过这部分数据来找到丢失的那部分数据,再单独跑个脚本重发就可以了。如果转发的程序没有落库,那就和消费方的记录去做对比,只是过程会更艰难一点。
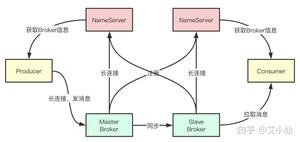
RocketMQ由NameServer注册中心集群、Producer生产者集群、Consumer消费者集群和若干Broker(RocketMQ进程)组成,它的架构原理是这样的:
- Broker在启动的时候去向所有的NameServer注册,并保持长连接,每30s发送一次心跳
- Producer在发送消息的时候从NameServer获取Broker服务器地址,根据负载均衡算法选择一台服务器来发送消息
- Conusmer消费消息的时候同样从NameServer获取Broker地址,然后主动拉取消息来消费
我认为有以下几个点是不使用zookeeper的原因:
- 根据CAP理论,同时最多只能满足两个点,而zookeeper满足的是CP,也就是说zookeeper并不能保证服务的可用性,zookeeper在进行选举的时候,整个选举的时间太长,期间整个集群都处于不可用的状态,而这对于一个注册中心来说肯定是不能接受的,作为服务发现来说就应该是为可用性而设计。
- 基于性能的考虑,NameServer本身的实现非常轻量,而且可以通过增加机器的方式水平扩展,增加集群的抗压能力,而zookeeper的写是不可扩展的,而zookeeper要解决这个问题只能通过划分领域,划分多个zookeeper集群来解决,首先操作起来太复杂,其次这样还是又违反了CAP中的A的设计,导致服务之间是不连通的。
- 持久化的机制来带的问题,ZooKeeper 的 ZAB 协议对每一个写请求,会在每个 ZooKeeper 节点上保持写一个事务日志,同时再加上定期的将内存数据镜像(Snapshot)到磁盘来保证数据的一致性和持久性,而对于一个简单的服务发现的场景来说,这其实没有太大的必要,这个实现方案太重了。而且本身存储的数据应该是高度定制化的。
- 消息发送应该弱依赖注册中心,而RocketMQ的设计理念也正是基于此,生产者在第一次发送消息的时候从NameServer获取到Broker地址后缓存到本地,如果NameServer整个集群不可用,短时间内对于生产者和消费者并不会产生太大影响。
RocketMQ主要的存储文件包括commitlog文件、consumequeue文件、indexfile文件。
Broker在收到消息之后,会把消息保存到commitlog的文件当中,而同时在分布式的存储当中,每个broker都会保存一部分topic的数据,同时,每个topic对应的messagequeue下都会生成consumequeue文件用于保存commitlog的物理位置偏移量offset,indexfile中会保存key和offset的对应关系。
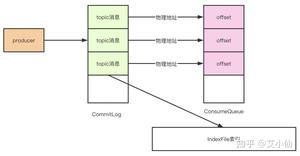
CommitLog文件保存于${Rocket_Home}/store/commitlog目录中,从图中我们可以明显看出来文件名的偏移量,每个文件默认1G,写满后自动生成一个新的文件。

由于同一个topic的消息并不是连续的存储在commitlog中,消费者如果直接从commitlog获取消息效率非常低,所以通过consumequeue保存commitlog中消息的偏移量的物理地址,这样消费者在消费的时候先从consumequeue中根据偏移量定位到具体的commitlog物理文件,然后根据一定的规则(offset和文件大小取模)在commitlog中快速定位。

而消息在master和slave之间的同步是根据raft协议来进行的:
- 在broker收到消息后,会被标记为uncommitted状态
- 然后会把消息发送给所有的slave
- slave在收到消息之后返回ack响应给master
- master在收到超过半数的ack之后,把消息标记为committed
- 发送committed消息给所有slave,slave也修改状态为committed
是因为使用了顺序存储、Page Cache和异步刷盘。
- 我们在写入commitlog的时候是顺序写入的,这样比随机写入的性能就会提高很多
- 写入commitlog的时候并不是直接写入磁盘,而是先写入操作系统的PageCache
- 最后由操作系统异步将缓存中的数据刷到磁盘
事务消息就是MQ提供的类似XA的分布式事务能力,通过事务消息可以达到分布式事务的最终一致性。
半事务消息就是MQ收到了生产者的消息,但是没有收到二次确认,不能投递的消息。
实现原理如下:
- 生产者先发送一条半事务消息到MQ
- MQ收到消息后返回ack确认
- 生产者开始执行本地事务
- 如果事务执行成功发送commit到MQ,失败发送rollback
- 如果MQ长时间未收到生产者的二次确认commit或者rollback,MQ对生产者发起消息回查
- 生产者查询事务执行最终状态
- 根据查询事务状态再次提交二次确认
最终,如果MQ收到二次确认commit,就可以把消息投递给消费者,反之如果是rollback,消息会保存下来并且在3天后被删除。
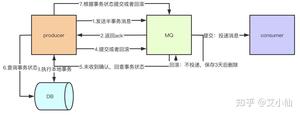
- END -
很多读者在看完百万 TCP 连接的系列文章之后,反馈问我有没有测试源码。也想亲自动手做出来体验体验。这里为大家的实践精神点赞。
测试百万连接我用到的方案有两种,今天用一篇文章都给大家分享出来。
- 第一种是服务器端只开启一个进程,然后使用很多个客户端 ip 来连接
- 第二种是服务器开启多个进程,这样客户端就可以只使用一个 ip 即可
为了能让大部分同学都能用最低的时间成本达成百万连接结果,飞哥写了 c、java、php 三种版本的源码。两个方案对应的代码地址如下:
方案一: https://github.com/yanfeizhang/coder-kung-fu/tree/main/tests/network/test02
方案二: https://github.com/yanfeizhang/coder-kung-fu/tree/main/tests/network/test03
鉴于整个实验做起来还是有点小复杂,本文会配合从头到尾讲述每一个试验步骤,让大家动手起来更轻松。本文描述的步骤适用于任意一种语言。建议大家有空都动手耍耍。
为什么非得要进行实验呢,因为我觉得只有动手实践过,很多东西才能真正掌握。这里引用下埃德加 · 戴尔提出的学习金字塔理论图。根据他的研究结果可以看出,实践要比单纯的阅读效率要高好几倍。
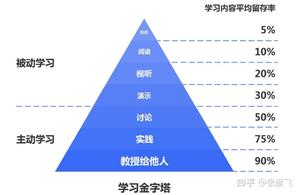
所以我的文章中很多都是在介绍理论的同时夹杂着实际动手的实验结果,这种方式写文章投入的时间成本要高很多。但是,我觉得值!
在做这个实验之前,需要你具备一些理论基础。这些在之前的文章都单独详细讲过,这里我把它们都简单再概括一下。
1.1 服务器理论最大并发数
TCP连接四元组是由源IP地址、源端口、目的IP地址和目的端口构成。
当四元组中任意一个元素发生了改变,那么就代表的是一条完全不同的新连接。
我们算下服务器上理论上能达成的最高并发数量。拿我们常用的 Nginx 举例,假设它的 IP 是 A,端口80。这样就只剩下源IP地址、源端口是可变的。
IP 地址是一个 32 位的整数,所以源 IP 最大有 2 的 32 次方这么多个。 端口是一个 16 位的整数,所以端口的数量就是 2 的 16 次方。
2 的 32 次方(ip数)× 2的 16 次方(port数)大约等于两百多万亿。
所以理论上,我们每个 server 可以接收的连接上限就是两百多万亿。(不过每条 TCP 连接都会消耗服务器内存,实践中绝不可能达到这个理论数字,稍后我们就能看到。)
参考文章:漫画 | 一台Linux服务器最多能支撑多少个TCP连接
1.2 客户端理论最大并发数
注意:这里的客户端是一个角色,并不具体指的是哪台机器。当你的 java/c/go 程序响应用户请求的时候,它是服务端。当它访问 redis/mysql 的时候,你这台机器就变成客户端角色了。这里假设我们一台机器只用来当客户端角色。
我们再算一下客户端的最大并发数的上限。
很多同学认为一台 Linux 客户端最多只能发起 64 k 条 TCP 连接。因为TCP 协议规定的端口数量有 65535 个,但是一般的系统里 1024 以下的端口都是保留的,所以没法用。可用的大约就是 64 k 个。
但实际上客户端可以发出的连接远远不止这个数。咱们看看以下两种情况
情况1: 这个 64 k 的端口号实际上说的是一个 ip 下的可用端口号数量。而一台 Linux 机器上是可以配置多个 IP 的。假如配置了 20 个 IP,那这样一台客户端机就可以发起 120 万多个 TCP 连接了。
情况2: 再退一步讲,假定一台 Linux 上确实只有一个 IP,那它就只能发起 64 k 条连接了吗? 其实也不是的。
根据四元组的理论,只要服务器的 IP 或者端口不一样,即使客户端的 IP 和端口是一样的。这个四元组也是属于一条完全不同的新连接。
比如下面的两条连接里,虽然客户端的 IP 和端口完全一样,但由于服务器侧的端口不同,所以仍然是两条不同的连接。
- 连接1:客户端IP 10000 服务器IP 10000
- 连接2:客户端IP 10000 服务器IP 20000
所以一台客户端机器理论并发最大数是一个比服务器的两百万亿更大的一个天文数字(因为四元组里每一个元素都能变)。这里就不展开计算了,因为已经没有意义了。
参考文章:理解了TCP连接的实现以后,客户端的并发也爆发了!
1.3 Linux 最大文件描述符限制
linux 下一切皆文件,包括 socket。所以每当进程打开一个 socket 时候,内核实际上都会创建包括 file 在内的几个内核对象。该进程如果打开了两个 socket,那么它的内核对象结构如下图。
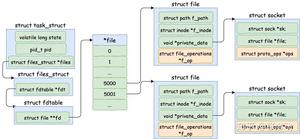
进程打开文件时消耗内核对象,换一句直白的话就是打开文件对象吃内存。所以linux系统出于安全角度的考虑,在多个位置都限制了可打开的文件描述符的数量,包括系统级、进程级、用户进程级。
- fs.file-max: 当前系统可打开的最大数量
- fs.nr_open: 当前系统单个进程可打开的最大数量
- nofile: 每个用户的进程可打开的最大数量
本文的实验要涉及对以上参数的修改。
参考文章:刨根问底儿,看我如何处理 Too many open files 错误!
1.4 TCP 连接的内存开销
介绍内存开销之前,需要先理解内核的内存使用方式。只有理解了这个,才能深刻理解 TCP 连接的内存开销。
Linux 内核和应用程序使用的是完全不同的两套机制。 Linux 给它的内核对象分配使用 SLAB 的方式。
一个 slab 一般由一个或者多个 Page 组成(每个 Page 一般为 4 KB)。在一个 slab 内只分配特定大小、甚至是特定的对象。这样当一个对象释放内存后,另一个同类对象可以直接使用这块内存。通过这种办法极大地降低了碎片发生的几率。
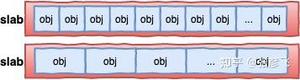
Linux 提供了 slabtop 命令来按照占用内存从大往小进行排列,这对我们查看内核对象的内存开销非常方便。
在 Linux 3.10.0 版本中,创建一个socket 需要消耗 densty、flip、sock_inode_cache、TCP 四个内核对象。这些对象加起来总共需要消耗大约 3 KB 多一点的内存。
如果连接上有数据收发的话,还需要消耗发送、接收缓存区。这两个缓存区占用内存影响因素比较多,既受收发数据的大小,也受 tcp_rmem、tcp_wmem 等内核参数,还取决于服务器进程能否及时接收(及时接收的话缓存区就能回收)。总之影响因素比较多,不同业务之间实际情况差别太大,比较复杂。所以不在本文讨论范围之内。
参考文章1:说出来你可能不信,内核这家伙在内存的使用上给自己开了个小灶!
参考文章2:漫画 | 花了七天时间测试,我彻底搞明白了 TCP 的这些内存开销!
了解了理论基础后,可以开始准备实验了。
本文实验需要准备两台机器。一台作为客户端,另一台作为服务器。如果你选用的是 c 或者 php 源码,这两台机器内存只要大于 4GB 就可以。 如果使用的是 Java 源码,内存要大于 6 GB。对 cpu 配置无要求,哪怕只有 1 个核都够用。
本方案中采用的方法是在一台客户端机器上配置多个 ip 的方式来发起所有的 tcp 连接请求。所以需要为你的客户端准备 20 个 IP,而且要确保这些 IP 在内网环境中没有被其它机器使用。如果实在选不出这些 IP,那么可以直接跳到方案 2。
除了用 20 个 IP 以外,也可以使用 20 台客户端。每个客户端发起 5 万个连接同时来连接这一个server。但是这个方法实际操作起来太困难了。
客户端机和服务器分别下载源码:
https://github.com/yanfeizhang/coder-kung-fu/tree/main/tests/network/test02
下面我们来详细看每一个实验步骤。
2.1 调整客户端可用端口范围
默认情况下,Linux 只开启了 3 万多个可用端口。但我们今天的实验里,客户端一个进程要达到 5 万的并发。所以,端口范围的内核参数需要修改。
#vi /etc/sysctl.conf net.ipv4.ip_local_port_range = 5000 65000执行 sysctl -p 使之生效。
2.2 调整客户端最大可打开文件数
我们要测试百万并发,所以客户端的系统级参数 fs.file-max 需要加大到 100 万。另外 Linux 上还会存在一些其它的进程要使用文件,所以我们需要多打一些余量出来,直接设置到 110 万。
对于进程级参数 fs.nr_open 来说,因为我们开启 20 个进程来测,所以它设置到 60000 就够了。这些都在 /etc/sysctl.conf 中修改。
#vi /etc/sysctl.conf fs.file-max= fs.nr_open=60000 sysctl -p 使得设置生效。并使用 sysctl -a 查看是否真正 work。
#sysctl -p #sysctl -a fs.file-max = fs.nr_open = 60000接着再加大用户进程的最大可打开文件数量限制(nofile)。这两个是用户进程级的,可以按不同的用户来区分配置。 这里为了简单,就直接配置成所有用户 * 了。每个进程最大开到 5 万个文件数就够了。同样预留一点余地,所以设置成 55000。 这些是在 /etc/security/limits.conf 文件中修改。
注意 hard nofile 一定要比 fs.nr_open 要小,否则可能导致用户无法登陆。
# vi /etc/security/limits.conf * soft nofile 55000 * hard nofile 55000配置完后,开个新控制台即可生效。 使用 ulimit 命令校验是否生效成功。
#ulimit -n 550002.3 服务器最大可打开文件句柄调整
服务器系统级参数 fs.file-max 也直接设置成 110 万。 另外由于这个方案中服务器是用单进程来接收客户端所有的连接的,所以进程级参数 fs.nr_open, 也一起改成 110 万。
#vi /etc/sysctl.conf fs.file-max= fs.nr_open= sysctl -p 使得设置生效。并使用 sysctl -a 验证是否真正生效。
接着再加大用户进程的最大可打开文件数量限制(nofile),也需要设置到 100 万以上。
# vi /etc/security/limits.conf * soft nofile * hard nofile 配置完后,开个新控制台即可生效。 使用 ulimit 命令校验是否成功生效。
2.4 为客户端配置额外 20 个 IP
假设可用的 ip 分别是 CIP1,CIP2,......,CIP20,你也知道你的子网掩码。
注意:这 20 个 ip 必须不能和局域网的其它机器冲突,否则会影响这些机器的正常网络包的收发。
在客户端机器上下载的源码目录 test02 中,找到你喜欢用的语言,进入到目录中找到 tool.sh。修改该 shell 文件,把 IPS 和 NETMASK 都改成你真正要用的。
为了确保局域网内没有这些 ip,最好先执行代码中提供的一个小工具来验证一下
make ping当所有的 ip 的 ping 结果均为 false 时,进行下一步真正配置 ip 并启动网卡。
make ifup使用 ifconfig 命令查看 ip 是否配置成功。
#ifconfig eth0 eth0:0 eth0:1 ... eth:192.5 开始实验
ip 配置完成后,可以开始实验了。
在服务端中的 tool.sh 中可以设置服务器监听的端口,默认是 8090。启动 server
make run-srv使用 netstat 命令确保 server 监听成功。
netstat -nlt | grep 8090 tcp 0 0.0.0.0:8090 0.0.0.0:* LISTEN在客户端的 tool.sh 中设置好服务器的 ip 和端口。然后开始连接
make run-cli同时,另启一个控制台。使用 watch 命令来实时观测 ESTABLISH 状态连接的数量。
实验过程中不会一帆风顺,可能会有各种意外情况发生。 这个实验我前前后后至少花了有一周时间,所以你也不要第一次不成功就气馁。 遇到问题根据错误提示看下是哪里不对。然后调整一下,重新做就是了。 重做的时候需要重启客户端和服务器。
对于客户端,杀掉所有的客户端进程的方式是
make stop-cli对于服务器来说由于是单进程的,所以直接 ctrl + c 就可以终止服务器进程了。 如果重启发现端口被占用,那是因为操作系统还没有回收,等一会儿再启动 server 就行。
当你发现连接数量超过 100 万的时候,你的实验就成功了。
watch "ss -ant | grep ESTABLISH" 这个时候别忘了查看一下你的服务端、客户端的内存开销。
先用 cat proc/meminfo 查看,重点看 slab 内存开销。
$ cat /proc/meminfo MemTotal: kB MemFree: 96652 kB MemAvailable: 6448 kB Buffers: 44396 kB ...... Slab: KB kB再用 slabtop 查看一下内核都是分配了哪些内核对象,它们每个的大小各自是多少。
如果发现你的内核对象和上图不同,也不用惊慌。因为不同版本的 Linux 内核使用的内核对象名称和数量可能会有些许差异。
2.6 结束实验
实验结束的时候,服务器进程直接 ctrl + c 取消运行就可以。客户端由于是多进程的,可能需要手工关闭一下。
make stop-cli最后记得取消为实验临时配置的新 ip
make ifdown如果不纠结于非得让一个 Server 进程达成百万连接,只要是 Linux 服务器上总共能达到就行,那么就还有另外一个方法。
那就是在服务器端的 Linux 上开启多个 server,每个 server 都监听不同的端口。然后在客户端也启动多个进程来连接。每一个客户端进程都连接不同的 server 端口。客户端上发起连接时只要不调用 bind,那么一个特定的端口是可以在不同的 server 之间复用的。
同样,实验源码也有 c、java、php 三个语言的版本。 准备好两台机器。一台作为客户端,另一台作为服务器。分别下载如下源码:
https://github.com/yanfeizhang/coder-kung-fu/tree/main/tests/network/test03
3.1 调整可用端口范围
同方案一,客户端机端口范围的内核参数也是需要修改的。
#vi /etc/sysctl.conf net.ipv4.ip_local_port_range = 5000 65000执行 sysctl -p 使之生效。
3.2 客户端加大最大可打开文件数
同方案一,客户端的 fs.file-max 也需要加大到 110 万。进程级的参数 fs.nr_open 设置到 60000。
#vi /etc/sysctl.conf fs.file-max= fs.nr_open=60000 sysctl -p 使得设置生效。并使用 sysctl -a 查看是否真正生效
客户端的 nofile 设置成 55000
# vi /etc/security/limits.conf * soft nofile 55000 * hard nofile 55000配置完后,开个新控制台即可生效。
3.3 服务器最大可打开文件句柄调整
同方案一,调整服务器最大可打开文件数。不过方案二服务端是分了 20 个进程,所以 fs.nr_open 改成 60000 就足够了。
#vi /etc/sysctl.conf fs.file-max= fs.nr_open=60000 sysctl -p 使得设置生效。并使用 sysctl -a 验证。
接着再加大用户进程的最大可打开文件数量限制(nofile),这个也是 55000。
# vi /etc/security/limits.conf * soft nofile 55000 * hard nofile 55000再次提醒: hard nofile 一定要比 fs.nr_open 要小,否则可能导致用户无法登陆。
配置完后,开个新控制台即可生效。
3.4 开始实验
启动 server
make run-srv 使用 netstat 命令确保 server 监听成功。
netstat -nlt | grep 8090 tcp 0 0 0.0.0.0:8100 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:8101 0.0.0.0:* LISTEN ...... tcp 0 0 0.0.0.0:8119 0.0.0.0:* LISTEN 回到客户端机器,修改 tool.sh 中的服务器 ip。端口会自动从 tool.sh 中加载。然后开始连接
make run-cli同时,另启一个控制台。使用 watch 命令来实时观测 ESTABLISH 状态连接的数量。
期间如果做失败了,需要重新开始的话,那需要先杀掉所有的进程。在客户端执行 make stop-cli,在服务器端是执行 make stop-srv。重新执行上述步骤。
当你发现连接数量超过 100 万的时候,你的实验就成功了。
watch "ss -ant | grep ESTABLISH" 记得查看同样一下你的服务端、客户端的内存开销。
# cat /etc/redhat-release Red Hat Enterprise Linux Server release 6.2 (Santiago) # ss -ant | grep ESTAB |wc -l # cat /proc/meminfo MemTotal: kB MemFree: 97748 kB Buffers: 35412 kB Cached: kB ...... Slab: kB再用 slabtop 查看一下 top 内核对象。
实验结束的时候,记得make stop-cli结束所有客户端进程,make stop-srv结束所有服务器进程。
经过网络篇这几篇文章的学习,相信大家已经不会再觉得百万并发有多么的高深了。并发只是描述服务器端程序的指标之一,并不是全部
一条不活跃的 TCP 连接开销仅仅只是 3 KB 多点的内存而已。现代的一台服务器都上百 GB 的内存,如果只是说并发,单机千万(C10000K)都可以。
在互联网服务器端应用场景里,除了一些基于长连接的 push 场景以外。其它的大部分业务里讨论并发都要和业务结合起来。抛开业务逻辑单纯地说并发多高其实并没有太大的意义。 因为在这些场景中,服务器开销大头往往都不是连接本身,而是在每条连接上的大量数据收发、以及请求业务逻辑处理。
这就好比你作为一个开发同学,在公司内建立了和十个产品经理的业务联系。这并不代表你的并发能力真的能达到十,很有可能是一位产品的需求就能把你的时间打满。
另外就是不同的业务之间,单纯比较并发也不一定有意义。
假设同样的服务器配置,A 业务的单机能支撑 1 万并发,B 业务只能撑 1 千。这也并不一定就说明 A 业务的性能比 B 业务好。因为 B 业务的请求处理逻辑可能是相当的复杂,比如要进行复杂的压缩、加解密。而 A 业务的处理很简单内存读取个变量就返回了。
扩展说一下,本文配套代码中仅仅只是作为测试使用,所以写的比较简单。是直接阻塞式地 accept,将接收过来的新连接也雪藏了起来,并没有读写发生。
如果在你的项目实践中真的确实需要百万条 TCP 连接,那么一般来说还需要高效的 IO 事件管理。在 c 语言中,就是直接用 epoll 系列的函数来管理。对于 Java 语言来说,就是 NIO。(Golang 中不用操心,net 包中把 IO 事件管理都已经封装好了)
收集了一些修炼内功时参考到的电子书,想要的同学在下面的网盘地址下载,提取码是 4uqa
电子书: https://pan.baidu.com/s/1yzSbhD96wdfYW6ncA9cN7A
另外飞哥建立了一个技术群,已经300人了。欢迎大家到群里来进一步交流。先加vx:zhangyanfei, 我来拉大家。
最后欢迎关注知乎专栏同名公众号:开发内功修炼
点赞再看,养成习惯,微信搜索【 敖丙】关注这个好像有点东西的傻瓜
本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试完整考点、资料、简历模板,以及我的程序人生。
在代码中生成随机数,是一个非常常用的功能,并且JDK已经提供了一个现成的Random类来实现它,并且Random类是线程安全的。
下面是Random.next()生成一个随机整数的实现:
protected int next(int bits) { long oldseed, nextseed; AtomicLong seed = this.seed; do { oldseed = seed.get(); nextseed = (oldseed * multiplier + addend) & mask; //CAS 有竞争是效率低下 } while (!seed.compareAndSet(oldseed, nextseed)); return (int)(nextseed >>> (48 - bits)); } 不难看到,上面的方法中使用CAS操作更新seed,在大量线程竞争的场景下,这个CAS操作很可能失败,失败了就会重试,而这个重试又会消耗CPU运算,从而使得性能大大下降了。
因此,虽然Random是线程安全的,但是并不是“高并发”的。
为了改进这个问题,增强随机数生成器在高并发环境中的性能,于是乎,就有了ThreadLocalRandom——一个性能强悍的高并发随机数生成器。
ThreadLocalRandom继承自Random,根据里氏代换原则,这说明ThreadLocalRandom提供了和Random相同的随机数生成功能,只是实现算法略有不同。
为了应对线程竞争,Java中有一个ThreadLocal类,为每一个线程分配了一个独立的,互不相干的存储空间。
ThreadLocal的实现依赖于Thread对象中的ThreadLocal.ThreadLocalMap threadLocals成员字段。
与之类似,为了让随机数生成器只访问本地线程数据,从而避免竞争,在Thread中,又增加了3个成员:
/ The current seed for a ThreadLocalRandom */ @sun.misc.Contended("tlr") long threadLocalRandomSeed; / Probe hash value; nonzero if threadLocalRandomSeed initialized */ @sun.misc.Contended("tlr") int threadLocalRandomProbe; / Secondary seed isolated from public ThreadLocalRandom sequence */ @sun.misc.Contended("tlr") int threadLocalRandomSecondarySeed; 这3个字段作为Thread类的成员,便自然和每一个Thread对象牢牢得捆绑在一起,因此成为了名副其实的ThreadLocal变量,而依赖这几个变量实现的随机数生成器,也就成为了ThreadLocalRandom。
不知道大家有没有注意到, 在这些变量上面,都带有一个注解@sun.misc.Contended,这个注解是干什么用的呢?要了解这个,大家得先知道一下并发编程中的一个重要问题——伪共享:
我们知道,CPU是不直接访问内存的,数据都是从高速缓存中加载到寄存器的,高速缓存又有L1,L2,L3等层级。在这里,我们先简化这些负责的层级关系,假设只有一级缓存和一个主内存。
CPU读取和更新缓存的时候,是以行为单位进行的,也叫一个cache line,一行一般64字节,也就是8个long的长度。
因此,问题就来了,一个缓存行可以放多个变量,如果多个线程同时访问的不同的变量,而这些不同的变量又恰好位于同一个缓存行,那会发生什么呢?
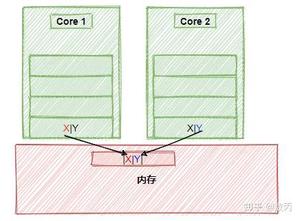
如上图所示,X,Y为相邻2个变量,位于同一个缓存行,两个CPU core1 core2都加载了他们,core1更新X,同时,core2更新Y,由于数据的读取和更新是以缓存行为单位的,这就意味着当这2件事同时发生时,就产生了竞争,导致core1和core2有可能需要重新刷新自己的数据(缓存行被对方更新了),这就导致系统的性能大大折扣,这就是伪共享问题。
那怎么改进呢?如下图:
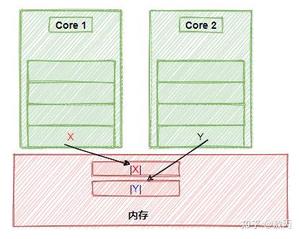
上图中,我们把X单独占用一个缓存行,Y单独占用一个缓存行,这样各自更新和读取,都不会有任何影响了。
而上述代码中的@sun.misc.Contended("tlr")就会在虚拟机层面,帮助我们在变量的前后生成一些padding,使得被标注的变量位于同一个缓存行,不与其它变量冲突。
在Thread对象中,成员变量threadLocalRandomSeed,threadLocalRandomProbe,threadLocalRandomSecondarySeed被标记为同一个组tlr,使得这3个变量放置于一个单独的缓存行,而不与其它变量发生冲突,从而提高在并发环境中的访问速度。
随机数的产生需要访问Thread的threadLocalRandomSeed等成员,但是考虑到类的封装性,这些成员却是包内可见的。
很不幸,ThreadLocalRandom位于java.util.concurrent包,而Thread则位于java.lang包,因此,ThreadLocalRandom并没有办法访问Thread的threadLocalRandomSeed等变量。
这时,Java老鸟们可能就会跳出来说:这算什么,看我的反射大法,不管啥都能抠出来访问一下。
说的不错,反射是一种可以绕过封装,直接访问对象内部数据的方法,但是,反射的性能不太好,并不适合作为一个高性能的解决方案。
有没有什么办法可以让ThreadLocalRandom访问Thread的内部成员,同时又具有远超于反射的,且无限接近于直接变量访问的方法呢?答案是肯定的,这就是使用Unsafe类。
这里,就简单介绍一下用的两个Unsafe的方法:
public native long getLong(Object o, long offset); public native void putLong(Object o, long offset, long x); 其中getLong()方法,会读取对象o的第offset字节偏移量的一个long型数据;putLong()则会将x写入对象o的第offset个字节的偏移量中。
这类类似C的操作方法,带来了极大的性能提升,更重要的是,由于它避开了字段名,直接使用偏移量,就可以轻松绕过成员的可见性限制了。
性能问题解决了,那下一个问题是,我怎么知道threadLocalRandomSeed成员在Thread中的偏移位置呢,这就需要用unsafe的objectFieldOffset()方法了,请看下面的代码:
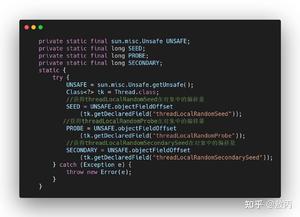
上述这段static代码,在ThreadLocalRandom类初始化的时候,就取得了Thread成员变量threadLocalRandomSeed,threadLocalRandomProbe,threadLocalRandomSecondarySeed在对象偏移中的位置。
因此,只要ThreadLocalRandom需要使用这些变量,都可以通过unsafe的getLong()和putLong()来进行访问(也可能是getInt()和putInt())。
比如在生成一个随机数的时候:
protected int next(int bits) { return (int)(mix64(nextSeed()) >>> (64 - bits)); } final long nextSeed() { Thread t; long r; // read and update per-thread seed //在ThreadLocalRandom中,访问了Thread的threadLocalRandomSeed变量 UNSAFE.putLong(t = Thread.currentThread(), SEED, r = UNSAFE.getLong(t, SEED) + GAMMA); return r; } 这种Unsafe的方法掉地能有多快呢,让我们一起看做个试验看看:
这里,我们自己写一个ThreadTest类,使用反射和unsafe两种方法,来不停读写threadLocalRandomSeed成员变量,比较它们的性能差异,代码如下:
上述代码中,分别使用反射方式byReflection() 和Unsafe的方式byUnsafe()来读写threadLocalRandomSeed变量1亿次,得到的测试结果如下:
byUnsafe spend :171ms byReflection spend :645ms 不难看到,使用Unsafe的方法远远优于反射的方法,这也是JDK内部,大量使用Unsafe来替代反射的原因之一。
我们知道,伪随机数生成都需要一个种子,threadLocalRandomSeed和threadLocalRandomSecondarySeed就是这里的种子。其中threadLocalRandomSeed是long型的,threadLocalRandomSecondarySeed是int。
threadLocalRandomSeed是使用最广泛的大量的随机数其实都是基于threadLocalRandomSeed的。而threadLocalRandomSecondarySeed只是某些特定的JDK内部实现中有使用,使用并不广泛。
初始种子默认使用的是系统时间:
上述代码中完成了种子的初始化,并将初始化的种子通过UNSAFE存在SEED的位置(即threadLocalRandomSeed)。
接着就可以使用nextInt()方法获得随机整数了:
public int nextInt() { return mix32(nextSeed()); } final long nextSeed() { Thread t; long r; // read and update per-thread seed UNSAFE.putLong(t = Thread.currentThread(), SEED, r = UNSAFE.getLong(t, SEED) + GAMMA); return r; } 每一次调用nextInt()都会使用nextSeed()更新threadLocalRandomSeed。由于这是一个线程独有的变量,因此完全不会有竞争,也不会有CAS的重试,性能也就大大提高了。
除了种子外,还有一个threadLocalRandomProbe探针变量,这个变量是用来做什么的呢?
我们可以把threadLocalRandomProbe 理解为一个针对每个Thread的Hash值(不为0),它可以用来作为一个线程的特征值,基于这个值可以为线程在数组中找到一个特定的位置。
static final int getProbe() { return UNSAFE.getInt(Thread.currentThread(), PROBE); } 来看一个代码片段:
CounterCell[] as; long b, s; if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { CounterCell a; long v; int m; boolean uncontended = true; if (as == null || (m = as.length - 1) < 0 || // 使用probe,为每个线程找到一个在数组as中的位置 // 由于每个线程的probe值不一样,因此大概率 每个线程对应的数组中的元素也是不一样的 // 每个线程对应了不同的元素,就可以没有冲突的进行完全的并发操作 // 因此探针probe在这里 就起到了防止冲突的作用 (a = as[ThreadLocalRandom.getProbe() & m]) == null || !(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) { 在具体的实现中,如果上述代码发生了冲突,那么,还可以使用ThreadLocalRandom.advanceProbe()方法来修改一个线程的探针值,这样可以进一步避免未来可能得冲突,从而减少竞争,提高并发性能。
static final int advanceProbe(int probe) { //根据当前探针值,计算一个更新的探针值 probe ^= probe << 13; // xorshift probe ^= probe >>> 17; probe ^= probe << 5; //更新探针值到线程对象中 即修改了threadLocalRandomProbe变量 UNSAFE.putInt(Thread.currentThread(), PROBE, probe); return probe; } 今天,我们介绍了ThreadLocalRandom对象,这是一个高并发环境中的,高性能的随机数生成器。
我们不但介绍了ThreadLocalRandom的功能和内部实现原理,还介绍介绍了ThreadLocalRandom对象是如何达到高性能的(比如通过伪共享,Unsafe等手段),希望大家可以将这些技术灵活运用到自己的工程中。
小傻瓜们对这个冷门类是否有深一步的理解了?理解了可以在评论区来一波:变得更强
我是敖丙,你知道的越多,不知道的越多,我们下期见。
敖丙把自己的面试文章整理成了一本电子书,共 1630页!
干货满满,字字精髓。目录如下,有我复习时总结的面试题以及简历模板,现在免费送给大家。
链接:https://pan.baidu.com/s/1ZQEKJBgtYle3v-1LimcSwg 密码:wjk6
今天我们聊一下高并发下的网络 IO 模型
高并发即我们所说的 C10K(一个 server 服务 1w 个 client),C10M,写出高并发的程序相信是每个后端程序员的追求,高并发架构其实有一些很通用的架构设计,如无锁化,缓存等,今天我们主要研究下高并发下的网络 IO 模型设计,我们知道不管是 Nginx,还是 Redis,Kafka,RocketMQ 等中间件,都能轻松支持非常高的 QPS,其实它们背后的网络 IO 模型设计理念都是一致的,所以了解这一块对我们了解设计出高并发的网络 IO 框架具体重要意义,本文将会从以下几个方面来循序渐近地向大家介绍如何设计出一个高并发的网络 IO 框架
- 传统网络 IO 模型的缺陷
- 针对传统网络 IO 模型缺陷的改进
- 多线程/多进程
- 阻塞改为非阻塞
- IO 多路复用
- Reactor 的几种模型介绍
我们首先来看下传统网络 IO 模型有哪些缺陷,主要看它们的阻塞点有哪些。我们用一张图来看下客户端和服务端的基于 TCP 的通信流程
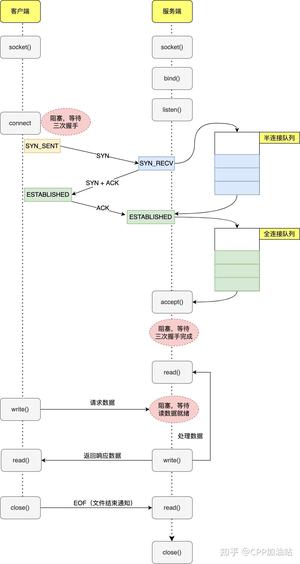
服务端的伪代码如下
listenSocket = socket(); //调用socket系统调用创建一个主动套接字 bind(listenSocket); //绑定地址和端口 listen(listenSocket); //将默认的主动套接字转换为服务器使用的被动套接字,也就是监听套接字 while (1) { //循环监听是否有客户端连接请求到来 connSocket = accept(listenSocket); //接受客户端连接 recv(connsocket); //从客户端读取数据,只能同时处理一个客户端 send(connsocket); //给客户端返回数据,只能同时处理一个客户端 }可以看到,主要的通信流程如下
- server 创建监听 socket 后,执行 bind() 绑定 IP 和端口,然后调用 listen() 监听,代表 server 已经准备好接收请求了,listen 的主要作用其实是初始化半连接和全连接队列大小
- server 准备好后,client 也创建 socket ,然后执行 connect 向 server 发起连接请求,这一步会被阻塞,需要等待三次握手完成,第一次握手完成,服务端会创建 socket(这个 socket 是连接 socket,注意不要和第一步的监听 socket 搞混了),将其放入半连接队列中,第三次握手完成,系统会把 socket 从半连接队列摘下放入全连接队列中,然后 accept 会将其从全连接队列中摘下,之后此 socket 就可以与客户端 socket 正常通信了,默认情况下如果全连接队列里没有 socket,则 accept 会阻塞等待三次握手完成
经过三次握手后 client 和 server 就可以基于 socket 进行正常的进程通信了(即调用 write 发送写请求,调用 read 执行读请求),但需要注意的是 read,write 也很可能会被阻塞,需要满足一定的条件读写才会成功返回,在 LInux 中一切皆文件,socket 也不例外,每个打开的文件都有读写缓冲区,如下图所示
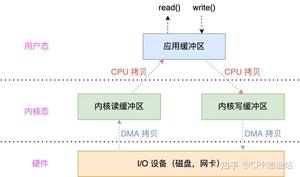
对文件执行 read(),write() 的具体流程如下
- 当执行 read() 时,会从内核读缓冲区中读取数据,如果缓冲区中没有数据,则会阻塞等待,等数据到达后,会通过 DMA 拷贝将数据拷贝到内核读缓冲区中,然后会唤醒用户线程将数据从内核读缓冲区拷贝到应用缓冲区中
- 当执行 write() 时,会将数据从应用缓冲区拷贝到内核写缓冲区,然后再通过 DMA 拷贝将数据从写缓冲区发送到设备上传输出去,如果写缓冲区满,则 write 会阻塞等待写缓冲区可写
经过以上分析,我们可以看到传统的 socket 通信会阻塞在 connect,accept,read/write 这几个操作上,这样的话如果 server 是单进程/线程的话,只要 server 阻塞,就不能再接收其他 client 的处理了,由此可知传统的 socket 无法支持 C10K
接下来我们来看看针对传统 IO 模型缺陷的改进,主要有两种
- 多进程/线程模型
- IO 多路程复用
如果 server 是单进程,阻塞显然会导致 server 无法再处理其他 client 请求了,那我们试试把 server 改成多进程的?只要父进程 accept 了 socket ,就 fork 一个子进程,把这个 socket 交给子进程处理,这样就算子进程阻塞了,也不影响父进程继续监听和其他子进程处理连接
程序伪代码如下
while(1) { connfd = accept(listenfd); // 阻塞建立连接 // fork 创建一个新进程 if (fork() == 0) { // accept 后子进程开始工作 doWork(connfd); } } void doWork(connfd) { int n = read(connfd, buf); // 阻塞读数据 doSomeThing(buf); // 利用读到的数据做些什么 close(connfd); // 关闭连接,循环等待下一个连接 }通过这种方式确实解决了单进程 server 阻塞无法处理其他 client 请求的问题,但众所周知 fork 创建子进程是非常耗时的,包括页表的复制,进程切换时页表的切换等都非常耗时,每来一个请求就创建一个进程显然是无法接受的
为了节省进程创建的开销,于是有人提出把多进程改成多线程,创建线程(使用 pthread_create)的开销确实小了很多,但同样的,线程与进程一样,都需要占用堆栈等资源,而且碰到阻塞,唤醒等都涉及到用户态,内核态的切换,这些都极大地消耗了性能
由此可知采用多进程/线程的方式并不可取
画外音: 在 Linux 下进程和线程都是用统一的 task_struct 表示,区别不大,所以下文描述不管是进程还是线程区别都不大
【高性能网络设计】还在用epoll么,了解io_uring以后 才知道比epoll强多少/io_uring如何应用_哔哩哔哩_bilibili
6种epoll的设计,让你吊打面试官,而且他不能还嘴
epoll原理剖析以及三握四挥的处理
LinuxC++后台服务器开发架构师免费学习地址
LinuxC++后台开发学习路线: Linux C/C++后端服务器架构开发 成长体系
【文章福利】:小编整理了一些个人觉得比较好的学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!~点击加入(需要自取)
既然多进程/多线程的方式并不可取,那能否将进程的阻塞操作(connect,accept,read/write)改为非阻塞呢,这样只要调用这些操作,如果相应的事件未准备好,就立马返回 EWOULDBLOCK 或 EAGAIN 错误,此时进程就不会被阻塞了,使用 fcntl 可以可以将 socket 设置为非阻塞,以 read 为例伪代码如下
connfd = accept(listenfd); fcntl(connfd, F_SETFL, O_NONBLOCK); // 此时 connfd 变为非阻塞,如果数据未就绪,read 会立即返回 int n = read(connfd, buffer) != SUCCESS; read 的非阻塞操作流程图如下
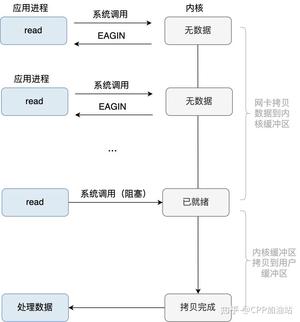
这样的话调用 read 就不会阻塞等待而会马上返回了,也就实现了非阻塞的效果,不过需要注意的,我们这里说的非阻塞并非严格意义上的非阻塞,这里的非阻塞只是针对网卡数据拷贝到内核缓冲区这一段,如果数据就绪后,再执行 read 此时依然是阻塞的,此时用户进程会占用 CPU 去把数据从内核缓冲区拷贝到用户缓冲区中,可以看到这种模式是同步非阻塞的,这里我们简单解释下阻塞/非阻塞,同步/非同步的概念
- 阻塞/非阻塞指的是在数据从网卡拷贝到内核缓冲区期间,进程能不能动,如果能动,就是非阻塞的,不能动就是阻塞的
- 同步/非同步指的是数据就绪后是否需要用户进程亲自调用 read 来搬运数据(将数据从内核空间拷贝到用户空间),如果需要,则是同步,如果不需要则是非同步(即异步),异步 I/O 示意图如下:
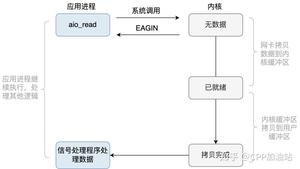
异步 IO 执行流程如下:进程发起 I/O 请求后,让内核在整个操作处理完后再通知进程,这整个操作包括网卡拷贝数据到内核缓冲区,将数据从内核缓冲区拷贝到用户缓冲区这两个阶段,内核在处理数据期间(从无数据到拷贝完成),应用进程是可以继续执行其他逻辑的,异步编程需要操作系统支持,目前只有 windows 完美支持,Linux 暂不支持。可以看出异步 I/O 才是真正意义上的非阻塞操作,因为数据从内核缓冲区拷贝到用户缓冲区这一步不需要用户进程来操作,而是由内核代劳了
我们以一个案例来总结下阻塞/非阻塞,同步/异步:当你去餐馆点餐时,如果在厨师做菜期间,你啥也不能干,那就是阻塞,如果在此期间你可以玩手机,喝喝茶,能动,那就是非阻塞,如果厨师做好了菜,你需要亲自去拿,那就是同步,如果厨师做好了,菜由服务员直接送到你的餐桌,那就是非同步(异步)
现在回过头来看将阻塞转成非阻塞是否满足了我们的需求呢?看起来进程确实可以动了,但进程需要不断地以轮询数据的形式调用 accept,read/write 这此操作来询问内核数据是否就绪了,这些都是系统调用,对性能的消耗很大,而且会持续占用 CPU,导致 CPU 负载很高,远不如等数据就绪好了再通知进程去取更高效。这就好比,厨师做菜期间,你不断地去问菜做好了没有,显然没有意义,更高效的方式无疑是等厨师菜做好了主动通知你去取
经过前面的分析我们可以得出两个结论
- 使用多进程/多线程 IO 模型是不可行的,这一步可以优化为单线程
- 应该等数据就绪好了之后再通知用户进程去读取数据,而不是做毫无意义的轮询,注意这里的数据就绪不光是指前文所述的 read 的数据已就绪,而是泛指 accept,read/write 这三个事件的数据都已就绪
于是 IO 多路复用模型诞生了,它是指用一个进程来监听 listen socket(监听 socket) 的连接建立事件,connect socket(已连接 socket) 的读写事件(读写),一旦数据就绪,内核就会唤醒用户进程去处理这些 socket 的相应的事件
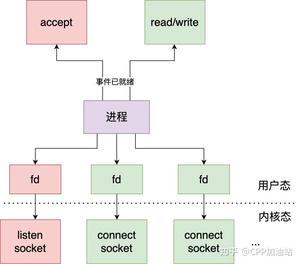
这里简单介绍一下 fd(文件描述符),以便大家更好地了解之后 IO 多路复用中出现的 fd 集合等概念
我们知道在 Linux 中无论是文件,socket,还是管道,设备等,一切皆文件,Linux 抽象出了一个 VFS(virtual file system) 层,屏蔽了所有的具体的文件,VFS 提供了统一的接口给上层调用,这样应用层只与 VFS 打交道,极大地方便了用户的开发,仔细对比你会发现,这和 Java 中的面向接口编程很类似
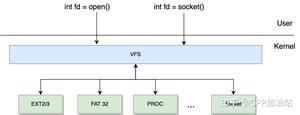
通过 open(),socket() 创建文件后,都有一个 fd(文件描述符) 与之对应,对于每一个进程,都有有一个文件描述符列表(File Discriptor Table) 来记录其打开的文件,这个列表的每一项都指向其背后的具体文件,而每一项对应的数组下标就是 fd,对于用户而言,可以认为 fd 代表其背后指向的文件
fd 的值从 0 开始,其中 0,1,2 是固定的,分别指向标准输入(指向键盘),标准输出/标准错误(指向显示器),之后每打开一个文件,fd 都会从 3 开始递增,但需要注意的是 fd 并不一定都是递增的,如果关闭了文件,之前的 fd 是可以被回收利用的
IO 多路复用其实也就是用一个进程来监听多个 fd 的数据事件,用户可以把自己感兴趣的 fd 及对应感兴趣的事件(accept,read/write)传给内核,然后内核就会检测 fd ,一旦某个 socket 有事件了,内核可以唤醒用户进程来处理
那么怎样才能知道某个 fd 是否有事件呢,一种很容易想到的做法是搞个轮询,每次调用一下 read(fd),让内核告知是否数据已就绪,但是这样的话如果有 n 个感兴趣的 fd 就会有 n 次 read 系统调用,开销很大,显然不可接受
所以使用 IO 多路复用监听 fd 的事件可行,但必须解决以下三个涉及到性能瓶颈的点
- 如何高效将用户感兴趣的 fd 和事件传给内核
- 某个 socket 数据就绪后,内核如何高效通知用户进程进行处理
- 用户进程如何高效处理事件
前面两步的处理目前有 select,poll,epoll 三种 IO 多路事件模型,我们一起来看看,看完你就会知道为啥 epoll 的性能是如此高效了
我们先来看下 select 函数的定义
返回:若有就绪描述符则为其数目,若超时则为 0,若出错则为-1 int select(int maxfd, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout);maxfd 是待测试的描述符基数,为待测试的最大描述符加 1,readset,writeset,exceptset 分别为读描述符集合,写描述符集合,异常描述符集合,这三个分别通知内核,在哪些描述描述符上检测数据可以读,可写,有异常事件发生,timeout 可以设置阻塞时间,如果为 null 代表一直阻塞
这里需要说明一下,为啥 maxfd 为待测试的描述符加 1 呢,主要是因为数组的下标是从 0 开始的,假设进程新建了一个 listenfd,它的 fd 为 3,那么代表它有 4 个 感兴趣的 fd(每个进程有固定的 fd = 0,1,2 这三个描述符),由此可知 maxfd = 3 + 1 = 4

接下来我们来看看读,写,异常集合是怎么回事,如何设置针对 fd 的感兴趣事件呢,其实事件集合是采用了一种位结构(bitset)的方式,比如现在假设我们对标准输入(fd = 0),listenfd(fd = 3)的读事件感兴趣,那么就可以在 readset 对应的位上置 1
画外音: 使用 FD_SET 可将相应位置置1,如 FD_SET(listenfd, &readset)
如下

即 readset 为 {1, 0,0, 1},在调用 select 后会将 readset 传给内核,如果内核发现 listenfd 有连接已就绪的事件,则内核也会在将相应位置置 1(其他无就绪事件的 fd 对应的位置为 0)然后会回传给用户线程,此时的 readset 如下,即 {1,0,0,0}

于是进程就可以根据 readset 相应位置是否是 1(用 FD_ISSET(i, &read_set) 来判断)来判断读事件是否就绪了
需要注意的是由于 accept 的 socket 会越来越多,maxfd 和事件 set 都需要及时调整(比如新 accept 一个已连接的 socket,maxfd 可能会变,另外也需要将其加入到读写描述符集合中以让内核监听其读写事件)
可以看到 select 将感兴趣的事件集合存在一个数组里,然后一次性将数组拷贝给了内核,这样 n 次系统调用就转化为了一次,然后用户进程会阻塞在 select 系统调用上,由内核不断循环遍历,如果遍历后发现某些 socket 有事件(accept 或 read/write 准备好了),就会唤醒进程,并且会把数据已就绪的 socket 数量传给用户进程,动图如下
select 的伪代码如下
int listen_fd,conn_fd; //监听套接字和已连接套接字的变量 listen_fd = socket() //创建套接字 bind(listen_fd) //绑定套接字 listen(listen_fd) //在套接字上进行监听,将套接字转为监听套接字 fd_set master_rset; //被监听的描述符集合,关注描述符上的读事件 int max_fd = listen_fd //初始化 master_rset 数组,使用 FD_ZERO 宏设置每个元素为 0 FD_ZERO(&master_rset); //使用 FD_SET 宏设置 master_rset 数组中位置为 listen_fd 的文件描述符为 1,表示需要监听该文件描述符 FD_SET(listen_fd,&master_rset); fd_set working_set; while(1) { // 每次都要将 master_set copy 给 working_set,因为 select 返回后 working_set 会被内核修改 working_set = master_set / * 调用 select 函数,检测 master_rset 数组保存的文件描述符是否已有读事件就绪, * 返回就绪的文件描述符个数,我们只关心读事件,所以其它参数都设置为 null 了 */ nready = select(max_fd+1, &working_set, NULL, NULL, NULL); // 依次检查已连接套接字的文件描述符 for (i = 0; i < max_fd && nready > 0; i++) { // 说明 fd = i 的事件已就绪 if (FD_ISSET(i, &working_set)) { nready -= 1; //调用 FD_ISSET 宏,在 working_set 数组中检测 listen_fd 对应的文件描述符是否就绪 if (FD_ISSET(listen_fd, &working_set)) { //如果 listen_fd 已经就绪,表明已有客户端连接;调用 accept 函数建立连接 conn_fd = accept(); //设置 master_rset 数组中 conn_fd 对应位置的文件描述符为 1,表示需要监听该文件描述符 FD_SET(conn_fd, &master_rset); if (conn_fd > max_fd) { max_fd = conn_fd; } } else { //有数据可读,进行读数据处理 read(i, xxx) } } } }看起来 select 很好,但在生产上用处依然不多,主要是因为 select 有以下劣势:
- 每次调用 select,都需要把 fdset 从用户态拷贝到内核态,在高并发下是个巨大的性能开销(可优化为不拷贝)
- 调用 select 阻塞后,用户进程虽然没有轮询,但在内核还是通过遍历的方式来检查 fd 的就绪状态(可通过异步 IO 唤醒的方式)
- select 只返回已就绪 fd 的数量,用户线程还得再遍历所有的 fd 查看哪些 fd 已准备好了事件(可优化为直接返回给用户进程数据已就绪的 fd 列表)
正在由于 1,2 两个缺点,所以 select 限制了 maxfd 的大小为 1024,表示只能监听 1024 个 fd 的事件,这离 C10k 显然还是有距离的
poll 的机制其实和 select 一样,唯一比较大的区别其实是把 1024 这个限制给放开了,虽然通过放开限制可以使内核监听上万 socket,但由于以上说的两点劣势,它的性能依然不高,所以生产上也不怎么使用
接下来我们再来介绍下生产上用得最多的 epoll,epoll 其实和 select,poll 这两个系统调用不一样,它本来其实是个内核的数据结构,这个数据结构允许进程监听多个 socket 的 事件,一般我们通过 epoll_create 来创建这个实例
然后我们再调用 epoll_ctl 把 感兴趣的 fd 加入到 epoll 实例中的 interest_list,然后再调用 epoll_wait 即可将控制权交给内核,这样内核就会检测此 interest_list,如果发现 socket 已就绪就会把已就绪的 fd 加入到一个 ready_list(简称 rdlist) 中,然后再唤醒用户进程,之后用户进程只要遍历此 rdlist 即可
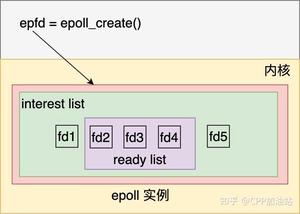
为了方便快速对 fd 进行增删改查,必须设计好 interest list 的数据结构,经综合考虑,内核使用了红黑树,而 rdlist 则采用了链表的形式,这样一旦在红黑树上发现了就绪的 socket ,就会把它放到 rdlist 中
epoll 的伪代码如下
int sock_fd,conn_fd; //监听套接字和已连接套接字的变量 sock_fd = socket() //创建套接字 bind(sock_fd) //绑定套接字 listen(sock_fd) //在套接字上进行监听,将套接字转为监听套接字 epfd = epoll_create(); //创建epoll实例, //创建epoll_event结构体数组,保存套接字对应文件描述符和监听事件类型 ep_events = (epoll_event*)malloc(sizeof(epoll_event) * EPOLL_SIZE); //创建epoll_event变量 struct epoll_event ee //监听读事件 ee.events = EPOLLIN; //监听的文件描述符是刚创建的监听套接字 ee.data.fd = sock_fd; //将监听套接字加入到监听列表中 epoll_ctl(epfd, EPOLL_CTL_ADD, sock_fd, &ee); while (1) { //等待返回已经就绪的描述符 n = epoll_wait(epfd, ep_events, EPOLL_SIZE, -1); //遍历所有就绪的描述符 for (int i = 0; i < n; i++) { //如果是监听套接字描述符就绪,表明有一个新客户端连接到来 if (ep_events[i].data.fd == sock_fd) { conn_fd = accept(sock_fd); //调用accept()建立连接 ee.events = EPOLLIN; ee.data.fd = conn_fd; //添加对新创建的已连接套接字描述符的监听,监听后续在已连接套接字上的读事件 epoll_ctl(epfd, EPOLL_CTL_ADD, conn_fd, &ee); } else { //如果是已连接套接字描述符就绪,则可以读数据 .https://www.zhihu.com//读取数据并处理 read(ep_events[i].data.fd, ..) } } }epoll 的动图如下
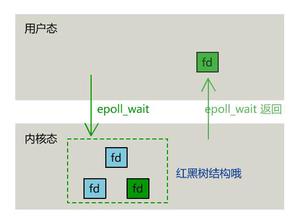
可以看到 epoll 很好地解决了 select 的痛点
- 「每次调用 select 都把 fd 集合拷贝给内核」优化为「只有第一次调用 epoll_ctl 添加感兴趣的 fd 到内核的 epoll 实例中,之后只要调用 epoll_wait 即可,数据集合不再需要拷贝」
- 「用户进程调用 select 阻塞后,内核会通过遍历的方式来同步检查 fd 的就绪状态」优化为「内核使用异步事件通知」
- 「select 仅返回已就绪 fd 的数量,用户线程还得再遍历一下所有的 fd 来挨个检查哪个 fd 的事件已就绪了」优化为「内核直接返回已就绪的 fd 集合」
除了以上针对 select 痛点进行的改进之外,epoll 还引入了一种边缘触发(edge trigger,ET)的模式,这种模式也会让 epoll 在高并发下的表现更加优秀,而 select/poll 则只有水平触发模式(level trigger,LT),首先我们来了解一下什么是水平触发和边缘触发
- 水平触发:只要读缓冲区可读(或可写缓冲区可写),就会一直触发可读(或可写)信号

- 边缘触发:当套接字的缓冲状态发生变化时才会触发读写信号。 对于读缓冲,有新到达的数据被添加到读缓冲时才触发

对于水平触发而言,只要缓冲区里还有数据,内核就会不停地触发读事件,也就意味着如果收到了大量的数据而应用程序每次只会读取一小部分数据时就会不停地从内核态切换到用户态,浪费大量的内核资源,而对于边缘触发而言,只有在套接字的缓冲状态发生变化(即新收到数据或刚好发出数据)时才会触发读写信号,也就意味着内核只通知唤醒用户进程一次,这在高并发下无疑是更佳选择,当然了也正是由于边缘触发模式下内核只会触发一次的原因,read 要尽可能地将数据全部读走(一般是在一个循环里不断地 read ,直到没有数据),否则一旦没有新的数据进来,缓冲区中剩余的数据就无法读取了
既然 epoll 这么好,那么它的性能到底比 select,poll 强多少呢,关于这一点,我们最好做对其进行做下压测,我们来看下 libevent 框架对 select,poll,Epoll,Kqueue(可以认为是 mac 下的 epoll)的压测数据
可以看到,在 100 活跃连接(所谓活跃连接就是读写比较频繁),每个连接发生 1000 次读写操作的情况下,随着句柄数量的增加,epoll 和 Kqueue 的响应时间几乎不变,而 select 和 poll 的响应时间则是急遽增加,所以 epoll 非常适合应对大量网络连接,少量活跃连接的情况
不过需要注意一下这里的限制条件:epoll 在应对大量网络连接时,只有在活跃连接数较少的情况下性能才表现优异,如果图中 15000 的网络连接都是活跃连接,那么 epoll 和 select 的表现是差不多的,甚至有可能 epoll 还不如 select,为什么会这样呢?
- select/poll 的开销主要是因为无论就绪的 fd 有多少,都要遍历一遍全部的 fd 来找到就绪的 fd 再处理,如果活跃连接数很少,那么很多时间都浪费在遍历上了,但如有很多活跃连接,那遍历的开销就可忽略不计
- 为什么活跃连接多,epoll 表现反而不佳呢,其实主要是因为在唤醒过程中 epoll 实现较为复杂,比如为了保证就绪队列的写入安全,使用了自旋锁,如下
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key) { int pwake = 0; unsigned long flags; struct epitem *epi = ep_item_from_wait(wait); struct eventpoll *ep = epi->ep; int ewake = 0; /* 获得自旋锁 ep->lock来保护就绪队列 * 自旋锁ep->lock在 epoll_wait() 调用的 ep_poll() 里被释放 * / spin_lock_irqsave(&ep->lock, flags); /* If this file is already in the ready list we exit soon */ /* 在这里将就绪事件添加到 rdllist */ if (!ep_is_linked(&epi->rdllink)) { list_add_tail(&epi->rdllink, &ep->rdllist); ep_pm_stay_awake_rcu(epi); } ... }
这样的话如果活跃连接多的话,锁的开销就比较大了
那么当 IO 多路程复用检查到数据就绪后(select(),poll(),epoll_wait() 返回后),该怎么处理呢,有人说直接 accept,read/write 不就完了,话是没错,但之前我们也说了,这些操作其实默认是阻塞的,我们需要将其改成非阻塞,为什么呢,数据不是已经就绪了吗,说明 accept,read/write 这些操作可以正常获取数据啊?
其实数据就绪只是说在调用 select(),poll(),epoll_wait() 返回时的数据是就绪的,但当你再去调用 accept,read/write 时可能就会变成未就绪了,举个例子:当某个 socket 接收缓冲区有新数据分节到达,然后 select 报告这个 socket 描述符可读,但随后,协议栈检查到这个新分节有错误,然后丢弃这个分节,这时候调用 read 则无数据可读,这样的话就会产生一个严重的后果:由于线程阻塞在了 read 上,便再也不能调用 select 来监听 socket 事件了,所以 IO 多路程复用一定要和非阻塞配合使用,也就是说要把 listenfd 和 connectfd 设置为非阻塞才行
经过以上介绍相信大家对 IO 多路复用的原理有了比较深刻的理解,我们知道 IO 多路程复用是用一个进程来管理多个 socket 的, 那么是否还有优化的空间呢,我们以 select 为例来拆解一下 IO 多路复用的流程
主要流程如下:调用 select 来监听连接,读写事件,收到事件后判断是否是监听 socket 上的事件,是的话调用 accept(),否则判断是否是已连接 socket 上的读写事件,是的话调用 read(),write()
目前这样的写法没有问题,不过所有的逻辑都藕合在一起,可扩展性不是很好,我们可以将相近的功能划分到同一个模块(以类的形式)中如下
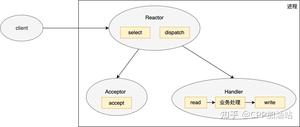
我们将其分成三个模块,Reactor, Acceptor,Handler,主要工作流程如下
- Reactor 对象首先调用 select 来监听 socket 事件,收到事件后会通过 dispatch 分发
- 如果是连接建立事件,则由 Acceptor 处理,Acceptor 通过调用 accept 接收连接,并且会创建一个 Handler 来处理后续的读写等事件
- 如果不是连接建立事件,则 Reactor 会调用连接对应的 Handler 进行响应,handler 会完成 read,业务处理,write 的完整业务流程
以上这些操作其实和之前的 IO 多路复用一样,所有的的都是由一个进程进行操作的,这里多了一个新名词 Reactor,它指的是对事件的响应,如果来了一个事件就把相应的事件 dispatch 给对应的 acceptor 或 handler 对象来处理,由于整个操作都在一个进程里处理,我们把这种模式称为单 Reactor 模型,单 Reactor 要求对事件的响应要快,比如对数据业务的处理要快,像 Redis 就很适合,因为它的数据都是基于内存操作的(当然像 bigKey 这种异常场景除外)
如果在单进程 Reactor 模型中,业务处理耗时较长,那么线程就会被阻塞,就无法再处理其它事件了,可能会造成严重的性能问题,而且单进程 Reactor 还有一个劣势,那就是无法充分复用多核的优势,于是人们又提出了 单 Reactor 多线程模型,即把业务处理这一块放到一个线程池中处理
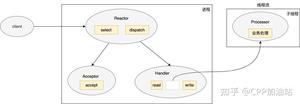
通过这种方式主进程的压力得到了释放,也充分复用了多核优势来提升并发度
但依然有如下两个瓶颈点
- 子线程处理好数据后需要将其传给 handler 进行发送处理,这涉及到共享数据的互斥和保护机制
- 主进程承担的所有事件的监听和响应,瞬时的高并发可能成为性能瓶颈
为以解决单 Reactor 多线程模型存在的两个问题,人们又提出了多 Reactor 多进程/线程模型模块,示意图如下
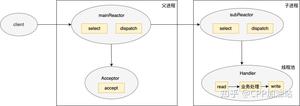
工作原理如下
- 主进程主要负责 accept 连接,接收后会将其传给 subReactor,subReactor 将其连接加入连接队列中来监控其事件
- 一旦子进程中有新的事件被监听到了,则 subReactor 会将其交给 Handler 进入处理
使用这种方式由于数据的 read,业务处理,write 都在一个线程中处理,所以避免了数据的同步加锁操作,父子进程职责很明确,父进程负责 accept,子进程则负责完成后续业务处理
以上介绍的只是标准的 Reactor 模型,但实际上生产上应用的 Reactor 不一定完全遵照这些标准,可能会有一些变化,比如 Nginx 的 Reactor 虽然也是多 Reactor 多进程模型,但它是一种变体:每个子进程都监听了同一个端口,内核接收到连接已建立的事件后会通过负载均衡的方式将其转给其中一个子进程,然后子进程会将其加入到连接队列中监控其事件,监控到事件后也不会转交给其他线程而是自己处理
随着互联网的发展,server 面对的连接越来越多,传统的网络 IO 模型由于在 connect,accept,read/write 这三步中会有阻塞操作,显然无法满足我们 C10K 要求,于是人们提出了多进程/线程模型,每接收一个连接分配一个进程/线程来负责后续的交互,但创建进程/线程本身需要创建堆栈,复制页表等资源,而且进程/线程的上下文切换涉及到用户态,内核态的切换,会造成严重的性能瓶颈,那么把阻塞操作改成非阻塞呢,这样做进程/线程确实是不会被阻塞了,但也意味着 CPU 会做大量的无用功,承担不必要的高负载
综合考虑人们提出了 IO 多路复用这种先进的理念,即一个线程管理监听多个 socket 的事件,当然了其实将 socket 设置成非阻塞的,然后让一个线程不断地去轮询也是能达到一个线程监听多个 socket 的目的,但这样做需要对每个 socket 调用一个 read 系统调用,所以 IO 多路复用还有另一层更重要的意义:将多个系统调用转成一个系统调用再交给内核去监听事件。
IO 多路复用主要有三个模型,select,poll,epoll,每一个都是对前者的改进:
- select 是每次调用时都要把 fd 集合拷贝给内核,而且内核是通过不断遍历这种同步的方式来检查 fd 是否有事件就绪,并且一旦检测到有事件后也只是返回有就绪事件的 fd 的个数,用户线程也需要遍历 fd 集合来查看 fd 是否已就绪,select 限制了 fd 的集合只能有 1024 个
- poll 和 select 的原理差不多,只不过是放开了 1024 个 fd 的限制,fd 的个数可以任意设置,这样也就让支持 C10k 成为了可能,但由于它的实现机制与 select 类似,所以也存在和 select 一样的性能瓶颈
- 为了彻底解决 select,poll 的性能瓶颈,epoll 出现了,它把需要监听的 fd 传给内核 epoll 实例,epoll 以红黑树的形式来管理这些 fd,这样每次 epoll 只需调用 epoll_wait 即可将控制权转给内核来监听 fd 的事件,避免了无意义的 fd 集合的拷贝,同时由于红黑树的高效,一旦某个 socket 来事件了,可以迅速从红黑树中查找到相应的 socket,然后再唤醒用户进程,此过程是异步的,比起 select 的同步唤醒又是一大进步,此时唤醒用户进程后,内核会把数据已就绪的 fd 放到一个就绪列表里传给用户进程,用户进程只需要遍历此就绪列表即可,比起 select 需要全部遍历也是一大进步,除此之外 epoll 引入了边缘触发让其在高并发下的表现也更加优异,正是由于 epoll 对 select,poll 的这些改进,也让它成为了 IO 多路复用绝对的王者
IO 多路复用是指用一个进程/线程去监听多个 socket 的事件,也即意味着一旦事件就绪了进程需要快速地处理这些事件(不然其他 socket 事件的处理的会阻塞),这种对 Redis 非常合适,因为它是基于内存操作的,处理非常快,但对于其它的开源框架,只有一个进程/线程显然是不太满足业务需要的,比如业务处理,可能是 CPU 密集型的,如果只一个进程/线程的话,可能会阻塞在业务处理上,于是人们基于 IO 多路复用又提出了 Reactor 模型,Reactor 即对事件的反应,然后派发事件给相应的处理器,Reator 模型有多个变种,如单 Reactor,单 Reactor 多线程,多 Reacor 多进程/线程模型,这三种模型各有各的优势,主要是为了充分利用多线程/多核来提升性能或是为了避免瞬时的高并发让主线程崩溃
由此可见,网络 IO 模型经历了传统的网络 IO 模型 ---> IO 多路程复用(select,poll,epoll) --> Reactor 模型这三个阶段,主要是为了满足日益增长的 C10k 甚至 C100K 等超高连接数的要求。
原文:高并发之网络IO模型
侵删~
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/9600.html