
为了避免和host的编译系统耦合,很多sdk和需要和客户联编的软件都会提供自己的工具链或者要求客户的系统满足某种工具链要求。
大概梳理下来独立的ToolChain 有如下一些好处:
下载编译需要的源代码包(上面用apt命令下载的gmp,mpfr和mpc也可以下载源代码包编译,上面为了省事直接下载了安装源上的包)
如果这3个组建是源代码编译的话,记得在gcc编译目录下面建立软连接,方便编译器能自动搜索到,否则需要单独指定代码目录
binutils也可以取最新版本的,这个无所谓:
gcc取了ubuntu18和ubuntu20上的7.x和9.x系列的最新版本,也可以取11.x,一般来说版本越新,功能越强大:
内核版本之前下载这个只是为了和host上的尽量保持一致,这样内核版本和glibc的版本匹配关系不用自己摸索了,实际上其他匹配的组合也可以:
glibc的版本很重要,决定了编译出来的版本能运行的最小支持版本,如果目标机器上的glibc版本比这个更老,则无法运行,2.23是ubuntu 16上的glibc版本:
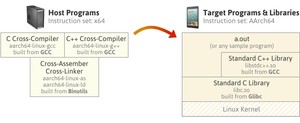
在host服务器上安装了c和c++的交叉编译工具链(假定目标系统是aarch64的系统),编译过程中会将c或者c++程序先编译成汇编临时文件,然后依赖本地的汇编器as编译成目标文件,再用链接器ld链接生成可执行文件,但这个可执行文件的格式是按目标系统来构建的,所以在host服务器上无法运行。
编译完的可执行文件通过版本发布或者拷贝到方式下载的目标系统上,例如最简单的a.out小程序,如果该程序依赖C++的库,则在目标系统上加载的过程中会先对C++的标准库进行动态链接,然后链接底层的C标准库(基本上所有编程语言底层都是基于C标准库),加载完之后内核的调度器会将该程序从入口运行起来。
解压缩上面下载的包。
创建编译目标目录。
燧原很多产品都是xxx开头,虽然我还不知道这3个字母是什么都缩写,但我还是沿用了,其实用其他路径名也可以的。
如果是直接在host上编译的话,尽量不要用root用户来操作,免得把host操作系统搞挂了痛不欲生。如果是在容器里面编译就随意了,容器的root文件系统弄坏大不了删掉当前容器重新启动一个。
目录里面最好包含gcc版本号、glibc版本号和目标硬件架构名,免得进去了之后猜:
更新好PATH全局变量,确保后面编译过程中使用的工具都是新编译出来的,而不是host上的:
正式编译gcc之前,需要先编译一个编译gcc的工具,也就是binutils包。
--disable-multilib的含义是不需要考虑同一个系列硬件架构下面的兼容性,例如aarch64目标机能运行,是否需要做aarch32上运行?x86_64的程序是否需要做i586上运行等等,一般应该没这种需求。
下面这个数字根据服务器的核数来,对应make程序最多运行的进程个数,如果运行的服务器核数非常多,完全可以配置更大,实际上编译过程中由于文件依赖关系,大多数时候运行不了这么多进程:
如果目标机的linux内核版本(软件和运行的硬件)和host完全一样的话,可以直接用apt命令下载,如果不是完全一样的话就需要重新编译一下头文件。
内核里面的硬件体系名和gcc不一样,例如这里的aarch64在linux内核里面还是叫arm64,另外一个参数指向要安装头文件的目录。
先把编译器编译出来。
csu/crt1.o csu/crti.o csu/crtn.o这几个库文件后面编译是需要的,但没有自动安装。和stubs.h后面第3.5步需要,但第3.6步会重新生成。
9.4的gcc源代码有个错误,报PATH_MAX未定义,搜了一下头文件中的定义,最大是4096,手工改成4096之后编译通过:
5 怎么用?
将编译出来的结果 /opt/xxx/xxx_aarch64_gcc9.4.0_glibc2.23linux/ 拷贝到任意的x86_64都linux编译机上(环境的glibc版本必须要高于2.23版本),将编译命令的的gcc/g++等程序换成/opt/xxx/xxx_aarch64_gcc9.4.0_glibc2.23linux/bin里面对应程序,并增加链接库的搜索路径/opt/xxx/xxx_aarch64_gcc9.4.0_glibc2.23linux/lib,增加头文件搜索路径/opt/xxx/xxx_aarch64_gcc9.4.0_glibc2.23linux/include就可以正常编译了。例如:
支持一键式从外网下载源代码并编译、安装交叉工具链
zhouronghua/CCC: the Compiler of the Cross Compiler (github.com)
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/9417.html