
数据库:DB(DataBase)
概念:数据仓库,,安装在操作系统之上
作用:存储数据,管理数据
关系型数据库:SQL(Structured Query Language)
- MySQL、Oracle、Sql Server、DB2、SQLlite
- 通过表和表之间,行和列之间的关系进行数据的存储
- 通过外键关联来建立表与表之间的关系
非关系型数据库:NoSQL(Not Only SQL)
- Redis、MongoDB
- 指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定
DBMS(数据库管理系统)
- 数据库的管理软件,科学有效的管理、维护和获取我们的数据
- MySQL就是数据库管理系统
- MySQL最新版8.0.21安装配置教程~
所有的语句都要以分号结尾
1、创建数据库
2、删除数据库
3、使用数据库
4、查看数据库
数值
字符串
时间日期
null
- 没有值,未知
- 不要使用NULL值进行计算
UnSigned
- 无符号的
- 声明了该列不能为负数
ZEROFILL
- 0填充的
- 不足位数的用0来填充 , 如int(3),5则为005
Auto_InCrement
- 通常理解为自增,自动在上一条记录的基础上默认+1
- 通常用来设计唯一的主键,必须是整数类型
- 可定义起始值和步长
- 当前表设置步长(AUTO_INCREMENT=100) : 只影响当前表
- SET @@auto_increment_increment=5 ; 影响所有使用自增的表(全局)
NULL 和 NOT NULL
- 默认为NULL , 即没有插入该列的数值
- 如果设置为NOT NULL , 则该列必须有值
DEFAULT
- 默认的
- 用于设置默认值
- 例如,性别字段,默认为"男" , 否则为 “女” ; 若无指定该列的值 , 则默认值为"男"的值
拓展:每一个表,都必须存在以下五个字段:
:
- 表名和字段尽量使用``括起来
- AUTO_INCREMENT 代表自增
- 所有的语句后面加逗号,最后一个不加
- 字符串使用单引号括起来
- 主键的声明一般放在最后,便于查看
- 不设置字符集编码的话,会使用MySQL默认的字符集编码Latin1,不支持中文,可以在my.ini里修改
格式:
常用命令:
INNODB
- 默认使用,安全性高,支持事务的处理,多表多用户操作
MYISAM
- 早些年使用,节约空间,速度较快
数据库文件存在的物理空间位置:
- MySQL数据表以文件方式存放在磁盘中
- 包括表文件 , 数据文件 , 以及数据库的选项文件
- 位置 : (目录名对应数据库名 , 该目录下文件名对应数据表)
MySQL在文件引擎上区别:
- 数据库文件类型就包括.frm、.ibd以及在上一级目录的ibdata1文件
- 存储引擎,数据库文件类型就包括
- .frm:表结构定义文件
- .MYD:数据文件
- .MYI:索引文件
修改
修改表名 : ALTER TABLE 旧表名 RENAME AS 新表名
添加字段 : ALTER TABLE 表名 ADD字段名 列属性[属性]
修改字段 :
- ALTER TABLE 表名 MODIFY 字段名 列类型[属性]
- ALTER TABLE 表名 CHANGE 旧字段名 新字段名 列属性[属性]
删除字段 : ALTER TABLE 表名 DROP 字段名
删除
语法:DROP TABLE [IF EXISTS] 表名
- IF EXISTS为可选 , 判断是否存在该数据表
- 如删除不存在的数据表会抛出错误
所有的创建和删除尽量加上判断,以免报错~
外键概念
如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。由此可见,外键表示了两个关系之间的相关联系。以另一个关系的外键作主关键字的表被称为主表,具有此外键的表被称为主表的从表。
在实际操作中,将一个表的值放入第二个表来表示关联,所使用的值是第一个表的主键值(在必要时可包括复合主键值)。此时,第二个表中保存这些值的属性称为外键(foreign key)。
外键作用:
保持数据一致性,完整性,主要目的是控制存储在外键表中的数据,约束。使两张表形成关联,外键只能引用外表中的列的值或使用空值。
目标:学生表(student)的gradeid字段 要去引用年级表(grade)的 gradeid字段
创建外键
方式一:在创建表的时候增加约束
删除有外键关系的表的时候,必须要先删除引用别人的表(从表),再删除被引用的表(主表)
方法二:创建表成功后,添加外键约束
以上的操作都是物理外键,数据库级别的外键,不建议使用!避免数据库过多造成困扰!
- 数据库就是用来单纯的表,只用来存数据,只有行(数据)和列(属性)
- 我们想使用多张表的数据,使用外键,用程序去实现
数据库的意义:数据存储,数据管理
:数据操作语言
1. 添加 insert
语法:
注意:
- 字段和字段之间使用英文逗号隔开
- 字段是可以省略的,但是值必须完整且一一对应
- 可以同时插入多条数据,VALUES后面的值需要使用逗号隔开
2. 修改 update
语法:
关于WHERE条件语句:
3. 删除 delete
语法:
关于删除的问题,重启数据库现象:
- INNODB 自增列会从1开始(存在内存当中,断电即失)
- MYISAM 继续从上一个子增量开始(存在内存当中,不会丢失)
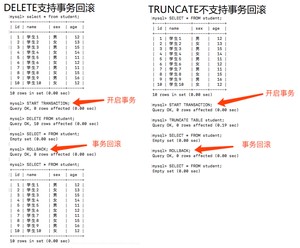
TRUNCATE
作用:完全清空一个数据库表,表的结构和索引约束不会变!
DELETE和TRUNCATE 的区别:
- DELETE可以条件删除(where子句),而TRUNCATE只能删除整个表
- TRUNCATE 重新设置自增列,计数器会归零,而DELETE不会影响自增
- DELETE是数据操作语言(DML - Data Manipulation Language),操作时原数据会被放到 rollback segment中,可以被回滚;而TRUNCATE是数据定义语言(DDL - Data Definition Language),操作时不会进行存储,不能进行回滚。
数据查询语言
- 查询数据库数据 , 如SELECT语句
- 简单的单表查询或多表的复杂查询和嵌套查询
- 是数据库语言中最核心,最重要的语句
- 使用频率最高的语句
前提配置:
语法:
- 查询列表可以是:表中的(一个或多个)字段,常量,变量,表达式,函数
- 查询结果是一个虚拟的表格
where 条件字句:检索数据中的值
语法:

语法:
区别:
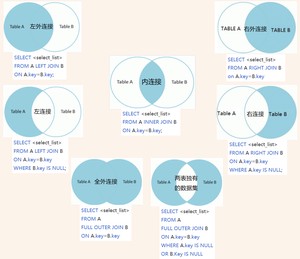
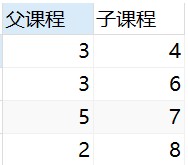
自连接
自己的表和自己的表连接,核心:一张表拆为两张一样的表即可
得到下表:

将该表进行拆分:
操作:查询父类对应的子类关系
排序
语法:
- order by的位置一般放在查询语句的最后(除limit语句之外)
分页
语法:
- offset代表的是起始的条目索引,默认从0开始
- size代表的是显示的条目数
- offset=(n-1)*pagesize
本质:在 子句中嵌套一个子查询语句
1. 常用函数
2. 聚合函数
MD5信息摘要算法(MD5 Message-Digest Algorithm)
- MD5由MD4、MD3、MD2改进而来,主要增强算法复杂度和不可逆性
- MD5激活成功教程网站的原理,背后有一个字典,MD5加密后的值,加密前的值

要么都成功,要么都失败
将一组SQL放在一个批次中去执行
- 例如银行转账:只有A转账成功且B成功到账,该事件才算结束,如果一方不成功,则该事务不成功
参考链接:https://blog.csdn.net/dengjili/article/details/
隔离所导致的一些问题:
在数据库操作中,为了有效保证并发读取数据的正确性,提出的事务隔离级别
- 读未提交:一个事务读取到其他事务未提交的数据;这种隔离级别下,查询不会加锁,一致性最差,会产生、、的问题
- 读已提交:一个事务只能读取到其他事务已经提交的数据;该隔离级别避免了问题的产生,但是和的问题仍然存在;
读提交事务隔离级别是大多数流行数据库的默认事务隔离级别,比如 Oracle,但是不是 MySQL 的默认隔离界别
- 可重复读:事务在执行过程中可以读取到其他事务已提交的新插入的数据,但是不能读取其他事务对数据的修改,也就是说多次读取同一记录的结果相同;该个里级别避免了、的问题,但是仍然无法避免的问题
可重复读是MySQL默认的隔离级别
- 串行化:事务串行化执行,事务只能一个接着一个地执行,、,并且在执行过程中完全看不到其他事务对数据所做的更新;缺点是并发能力差,最严格的事务隔离,完全符合ACID原则,但是对性能影响比较大
1️⃣ 关闭自动提交
2️⃣ 事务开启
3️⃣ 成功则提交,失败则回滚
4️⃣ 事务结束
5️⃣ 其他操作
推荐阅读:MySQL索引背后的数据结构及算法原理
索引()是帮助MySQL高效获取数据的数据结构。
- 提高查询速度
- 确保数据的唯一性
- 可以加速表和表之间的连接 , 实现表与表之间的参照完整性
- 使用分组和排序子句进行数据检索时 , 可以显著减少分组和排序的时间
- 全文检索字段进行搜索优化
主键索引(PRIMARY KEY)
唯一的标识,主键不可重复,只有一个列作为主键
- 最常见的索引类型,不允许为空值
- 确保数据记录的唯一性
- 确定特定数据记录在数据库中的位置
普通索引(KEY / INDEX)
默认的,快速定位特定数据
- index 和 key 关键字都可以设置常规索引
- 应加在查询找条件的字段
- 不宜添加太多常规索引,影响数据的插入,删除和修改操作
唯一索引(UNIQUE KEY)
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值
与主键索引的区别:主键索引只能有一个、唯一索引可以有多个
全文索引(FULLText)
快速定位特定数据(百度搜索就是全文索引)
- 在特定的数据库引擎下才有:MyISAM
- 只能用于CHAR , VARCHAR , TEXT数据列类型
- 适合大型数据集
1. 索引的创建
- 在创建表的时候给字段增加索引
- 创建完毕后,增加索引
2. 索引的删除
3. 显示索引信息
4. explain分析sql执行的情况
建表app_user:
批量插入数据:100w
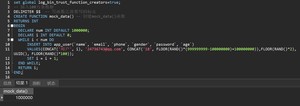
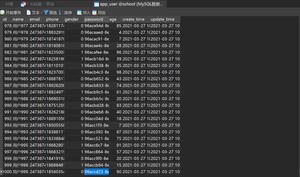
测试查询速度

增加索引后测试

对比两次结果,速度有了很大的提升
- 索引不是越多越好,小数据量的表不需要加索引
- 不要对经常变动的数据增加索引
- 索引一般加在经常要查询的列上
建议阅读:
- MySQL优化——看懂explain
- MySQL高级 之 explain执行计划详解
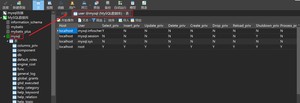
方式一:可视化管理
方式二:SQL命令操作
用户信息存储在数据库的表中,对用户的管理本质上就是对这张表进行增删改查
保证重要的数据不丢失、数据转义
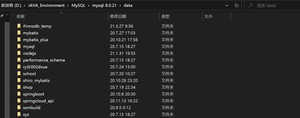
方式一:直接拷贝物理文件,MySQL数据表以文件方式存放在磁盘中
- 包括表文件 , 数据文件 , 以及数据库的选项文件
- 位置 : (目录名对应数据库名 , 该目录下文件名对应数据表)
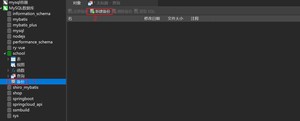
方式二:可视化管理
Navicat打开要备份的数据库,然后点击新建备份
点击对象选择,这里可以自定义选择备份的表
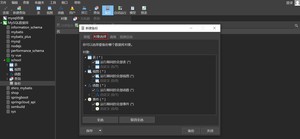
选择完毕后,点击备份即可开始备份
等待备份完成,关闭,然后便可看到备份的文件
方式三:可视化管理
选中要导出的表,右键转储SQL文件
然就就可以得到文件

方式四:命令导出

然后便可看到导出的文件
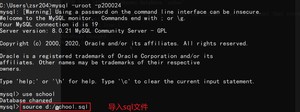
然后可以命令行登录mysql,切换到指定的数据库,用命令导入
规范化理论:改造关系模式,通过分解关系模式来消除其中不合适的数据依赖,以解决插入异常、删除异常、更新异常和数据冗余的问题。
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定规范化理论。在关系型数据库中这种规则就称为
三大范式的通俗理解
- 如果一个关系模式R的所有属性都是不可分的数据项,则R属于
- 如果关系模式R属于第一范式,且每一个非主属性完全函数依赖于码,则R属于
- 若关系模式R属于第二范式,且R中所有的非主属性都直接依赖于码,则R属于

规范性问题:
数据库的范式是为了规范数据库的设计,但是实际中相比规范性,往往更需要看中性能、成本、用户体验等问题;
因此有时会故意给某些表增加一个冗余的字段,使多表查询变为单表查询。有时还会增加一些计算列,从大数据量变为小数据量(数据量大时,count(*)很耗时,可以直接添加一列,每增加一行+1,查该列即可);阿里也曾提出关联查询的表最多不超过三张表。
这些就是为了性能、成本而舍弃一定规范性的例子
我们编写的程序会通过数据库驱动来和数据库进行交互

然后不同的数据库有不同的驱动,这不便于我们程序对各种数据库进行操作;因此为了简化对不同数据库的操作,SUN公司提供了一个Java操作数据库的规范;不同数据库的规范由对应的数据库厂商完成,对于开发人员,只需要掌握JDBC接口的操作即可

1️⃣ 新建空项目

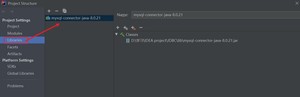
2️⃣ 导入mysql-connector-java
在项目目录下新建目录,放入jar包

3️⃣ 编写代码&测试
在目录下新建用来操作数据库
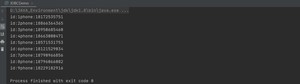
DriverManager
DriverManager:驱动管理
本质上执行
代表数据库,因此可以设置事务自动提交,事务回滚等
Statement
Statement:执行sql的对象,用于向数据库发送SQL语句,想完成对数据库的增删改査,只需要通过这个对象向数据库发送增删改查语句即可


ResultSet
ResultSet:查询的结果集,封装了所有查询的结果

1. 编写数据库配置文件
在目录下新建,用于存放数据库配置信息

2. 编写工具类
然后再目录下新建作为工具类
3. 测试
修改
SQL注入即是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息。
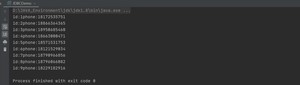
sql注入案例:主函数中传入用户名,查找指定名字用户信息
结果:查询到了数据库中所有的数据
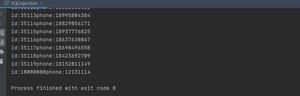
这里传入一个不是用户名,而是一个不合法字符串,却获取到了全部的数据,为什么呢?
拼接整条sql语句是,其中永远是真的,所以该sql语句相当于查询表中所有的数据;这就是sql注入,主要是字符串拼接引起的问题,十分危险!!
是的子类,与其相比,可以防止SQL注入,并且效率更高
同样测试sql注入案例

根据结果,PreparedStatement对象完美避免了sql注入问题
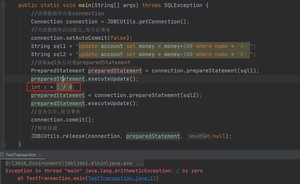
首先创建account表

然后编写Java代码
运行结果:

如果两次更新之间加
则会报错,且事务执行失败,两条语句都不会执行成功
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/904.html