
正则表达式
Java网络通信:URL
IO流
Map—HashMap
字符串操作
异常处理
如果这篇博客对你有一点点小帮助,希望您能给我来波一键三连;
python优点:
1.各种爬虫框架,方便高效的下载网页;
2.多线程、进程模型成熟稳定,爬虫是一个典型的多任务处理场景,请求页面时会有较长的延迟,总体来说更多的是等待。多线程或进程会更优化程序效率,提升整个系统下载和分析能力。
3.gae 的支持,当初写爬虫的时候刚刚有 gae,而且只支持 python ,利用 gae 创建的爬虫几乎免费,最多的时候我有近千个应用实例在工作。
通用型的爬虫: 宽度遍历
垂直型的爬虫
1.在Module建立一个maven工程
(因为我提前建立了一个大的maven工程项目,本次为了节省时间,就不重新创建一个maven工程,直接利用现有的)
建立一个简单的maven,不选用现成的骨架
点击module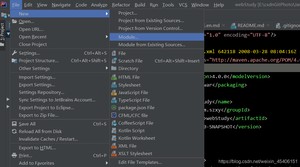
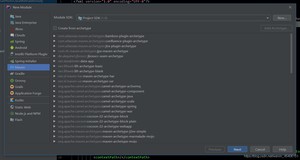
选择好你需要的jdk版本,点击next
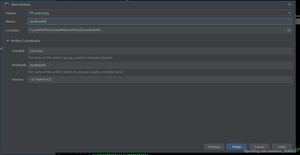
设置好工程名称,和域名倒写。点击finish
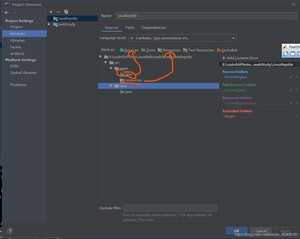
点击file,点击Project structure,再点击module

将 java设为Source 将resources 设为Resource
引入你需要的maven依赖
org.jsoup jsoup 1.10.3
org.apache.httpcomponents httpcore 4.4.10
org.apache.httpcomponents httpclient 4.5.6
commons-io commons-io 2.6
建立好包
本次爬取网站:昵图网传送门 以一个图片网站作为本次爬取对象
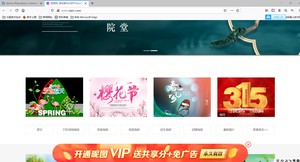
在网站中审查元素:确定图片的html代码结构
crtl+(a标签里面的http://www.nipic.com/topic/show_27400_1.html)
分析html代码,观察里面的结点结构特点。建立一个URL的值,把里面所有的html的保存起来。
然后来处理里面的每一个html,再来根据里面的每一个html,来取这个界面中间的图片。
需要分开处理,img图片和上面的a标签,来爬取上面的图片,将图片保存起来。
创建一个UrlPool类,用来存放html。
代码全在我的gitee:传送门
对你有用的话,可以点个收藏关注;给我的gitee点一个star;谢谢;
运行上面的UrlPool类,得到下面的控制台输出:
为了拿到被爬取的内容图片,对内容解析并持久化,创建ImageCrawl类
这一部分:因为考虑到待会教程太长了,放到下一篇博客中说明;
正则表达式
Java网络通信:URL
IO流
Map—HashMap
字符串操作
异常处理
点赞+加一键三连
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/8695.html