
前面我们学习了单链表(单向不带头不循环链表),这篇文章我们要学习的是双向链表(双向带头循环链表),链表的结构非常多样,一共有8种结构。
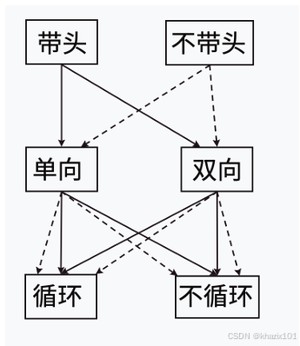
现在我们知道了链表的结构多样,那么如何区分不同种类的的链表呢?
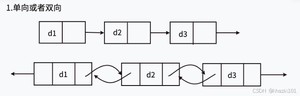
在单向链表中,一个结点有一个指针域,该指针域指向该结点的后继结点,可以实现单向的遍历。
在双向链表中,一个结点有两个指针域,分别指向该结点的后继结点和前驱结点,可以实现双向遍历。
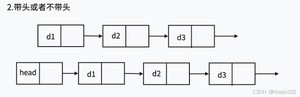
头结点:带头链表的第一个结点,头结点也被称为哨兵位等,不存储有效的数据,作用就是占位子,可以去除特殊情况,实现操作的统一。如果带头链表只有一个头结点,这个链表就是空链表。
首节点:就是第一有效的结点、真正存储有效数据的结点,如果链表带头的话,我们可以说首节点是链表的第二个结点。
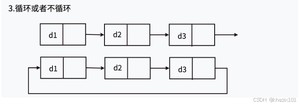
循环结构的尾结点的next指针不为NULL,而是指向第一个结点(如果带头则指向头结点,不带头就指向首节点)。
虽然链表的结构很多,但是我们实际中最常用的还是两种结构:单链表和双向带头循环链表。
1.单向无头不循环链表:结构简单,一般不会单独用来存储数据,而是作为其他数据结构的子结构,例如:哈希桶、图的邻接表等。这种结构在算法题和笔试面试中比较多。
2.带头的双向循环链表:结构最复杂,一般用在单独存储数据,实际中使用的链表数据结构,都是双向循环链表。虽然这个结构复杂,但是代码的实现会因为结构带来很多的优势反而变得简单。
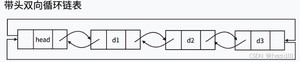
双向链表结点比单向链表的结点多了一个指针域,用来指向前驱结点。
2.2.1 初始化
在初始化步骤中,我们需要定义一个头结点并把头结点的两个指针都指向自己,来体现双向带头循环链表的带头和循环两个特性,头结点的数据域可以任意赋值。下面给出初始化的两种方式。
第二种方式是传二级指针来实现初始化,但是还是比较推荐第一种。
2.2.2 遍历打印
定义一个pcur指向首节点,遍历打印即可,直到pcur指向头结点退出循环。
2.2.3 创建一个新的结点
当我们需要插入元素的时候,第一步就是需要建立一个新的结点。
创建结点和初始化的过程类似,只是初始化结点的数据域可以任意赋值,我们可以在初始化函数中调用一下创建结点的函数来简化代码。
2.2.4 尾插
尾插的时候影响的结点是头结点的prev域和尾结点的next域。
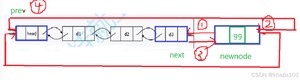
4个步骤中只需要保证步骤4在最后即可,因为phead的prev原来指向d3结点,随着其改变后我们不能很好的(但不是不能)找到d3结点。我们一般把newnode的指针域先指向被影响的结点,然后判断剩下步骤的先后顺序,把可以影响其他步骤的放在最后处理。
双向链表的尾插传的是一级指针,而单链表的尾插传的是二级指针,这一点我们在单链表文章中简单的论述过,单链表是无头的,当链表为空的时候进行尾插,plist的指向会发生改变,这时候就需要传址调用,而双向链表则不是这样,因为双向链表是有头节点的,plist始终指向的是头节点,当链表为空的时候,尾插是插入在头节点的next域的,而头结点在被初始化建立到程序结束之前,地址是不改变的,所以传一级指针即可。
测试一下尾插代码
我们可以尝试一下1243的步骤 这里给出代码
这里因为步骤4改变了phead->prev的指向,我们不能通过phead->prev来找到d3,那我们可以通过newnode->prev来找到,因为第2步已经把newnode->prev指向了d3。但是步骤4不能放在第一位,这样会导致我们不能通过O(1)的方式正确的找到d3,从而无法完成步骤1和步骤3。
2.2.5 头插
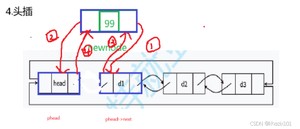
头插的时候影响的是phead的next域和首节点d1的prev域,我们还是向尾插那样,先把newnode的next、prev指针(1和2)指好,然后判断3和4,同样4不能再3的前面,因为phead->next 指针改变后就不能通过phead->next正确的找到首节点d1。
测试一下
如果我们一定要再步骤3之前先进行步骤4,那么我们还有办法正确的写出步骤3嘛?
其实也是可以的,可以通过之前步骤1newnode->next来找到首节点d1,从而完成步骤3。但是步骤4确实不能放在第一位来运行,这样甚至newnode->next也不能成功的指向首节点d1。
测试一下
在尾插和头插我们给出了指针指向顺序的论述,我们发现指针指向的顺序有多种方式,后面给出的都是通过对参数的解引用来完成步骤被影响的结点对newnode的指向的代码,不会再重点的强调其他的方式。
2.2.6 判空
当双向链表为空的时候,链表中只有一个头结点,而头结点的next和prev都是指向自己的。
2.2.7 尾删
不管是头删尾删还是其他形式的删除,首先一定要判空的。
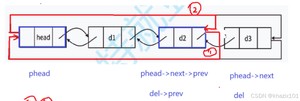
尾删的时候影响的是phead的prev和 phead->prev->prev的next,这里还有要按照先1后2的顺序并把要释放的尾结点定义为del,这样的代码更容易理解。当然还有其他的方式:例如先2再释放尾结点再1,读者可以自行尝试写出,然后对比一下。
测试一下
2.2.8 头删
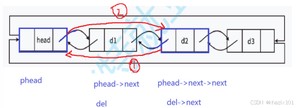
头删影响的是phead的next和 phead->next->next的prev,这里采用先1后2的方式。
测试一下
2.2.9 返回指定数据的地址
遍历对比即可,对比成功返回当前指针,对比失败跳出循环,返回NULL。
测试一下
当LTFind的传99的时候就会输出没有找到,请自行测试。
2.2.10 在pos位置后面进行插入
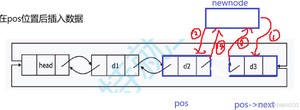
受到影响的是pos的next域和pos->next的prev域,这里最好还是按照1234的顺序。
测试一下

2.2.11 在pos位置前插入
在pos的位置前插入和在pos位置后插入差不多
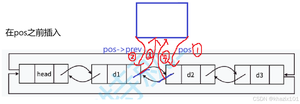
按照1234的顺序来
测试

2.2.12 删除pos位置的数据
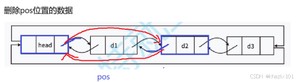
受到影响的是pos->prev的next和pos->next的prev,只需要把两者指针的指向即可,没有先后顺序的限制。
测试一下
2.2.13 销毁链表
遍历销毁即可,这里要注意的是头结点也要被销毁,因为头结点也是malloc来的。

这里的函数传的是二级指针,因为头结点也要被销毁,plist的指向要发生改变,但是我们前面是实现的所有函数都是一级指针,唯独销毁函数是二级,这样就会出现记忆成本,那我们能不能把销毁函数也传一级指针还能实现销毁呢?
这样就能实现销毁了嘛?其实还差一点,因为传的是一级指针,所有形参的改变不影响实参,phead = NULL,没有改变 实参plist的值,我们需要额外的把plist == NULL才完成了销毁的效果,大家可以自行调试观察销毁过程。
- 双向链表的大部分函数的时间复杂度都是O(1),单链表的很多的时间复杂度为O(n),这是因为双向链表有两个指针,可以不通过循环的方式来找到节点,更加灵活,同时因为双向链表的有两个指针域,所以存储密度是偏低的。
- 双向链表函数实现的时候大多传的是一级指针,这是因为在双向链表plist指向的是头结点,各种函数实现的过程中plist是不需要改变的,而单链表plist指向的是首节点,在函数的实现过程中有时是需要变化的。
- 头结点的作用:1.可以统一函数的实现,不需要考虑的情况。2. 使plist指向头结点,在大多数情况下只需要传递一级指针,增加代码的可读性。
- 双向链表是实际存储使用的数据结构,单链表一般不会用来存储数据,是实现其他数据结构的子结构。
我们在链表的部分讲解了无头单向循环链表和有头双向循环链表,这是在两种经常用到的链表,大家也可以根据自己的兴趣实现一下剩下的六种链表。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/8692.html