
这篇博客主要讲:、、。
1、Analysis 和 Analyzer
: 文本分析是把全文本转换一系列单词(term/token)的过程,也叫分词。Analysis是通过Analyzer来实现的。
当一个文档被索引时,每个Field都可能会创建一个倒排索引(Mapping可以设置不索引该Field)。
倒排索引的过程就是将文档通过Analyzer分成一个一个的Term,每一个Term都指向包含这个Term的文档集合。
当查询query时,Elasticsearch会根据搜索类型决定是否对query进行analyze,然后和倒排索引中的term进行相关性查询,匹配相应的文档。
2 、Analyzer组成
分析器(analyzer)都由三种构件块组成的: , , 。
英文分词可以根据空格将单词分开,中文分词比较复杂,可以采用机器学习算法来分词。
将切分的单词进行加工。大小写转换(例将“Quick”转为小写),去掉词(例如停用词像“a”、“and”、“the”等等),或者增加词(例如同义词像“jump”和“leap”)。
:Character Filters--->Tokenizer--->Token Filter
:analyzer = CharFilters(0个或多个) + Tokenizer(恰好一个) + TokenFilters(0个或多个)
3、Elasticsearch的内置分词器
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
4、创建索引时设置分词器
这里讲解下常见的几个分词器:、、。
1、Standard Analyzer(默认)
1)示例
standard 是默认的分析器。它提供了基于语法的标记化(基于Unicode文本分割算法),适用于大多数语言
运行结果
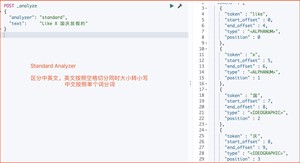
2)配置
标准分析器接受下列参数:
- max_token_length : 最大token长度,默认255
- stopwords : 预定义的停止词列表,如或 包含停止词列表的数组,默认是
- stopwords_path : 包含停止词的文件路径
2、Simple Analyzer
simple 分析器当它遇到只要不是字母的字符,就将文本解析成term,而且所有的term都是小写的。
运行结果
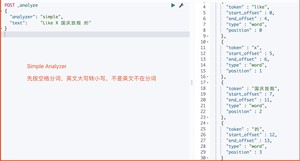
3、Whitespace Analyzer
返回

中文的分词器现在大家比较推荐的就是 ,当然也有些其它的比如 smartCN、HanLP。
这里只讲如何使用IK做为中文分词。
1、IK分词器安装
开源分词器 Ik 的github:https://github.com/medcl/elasticsearch-analysis-ik
IK分词器的版本要你安装ES的版本一致,我这边是7.1.0那么就在github找到对应版本,然后启动命令
运行结果

安装完插件后需重启Es,才能生效。
2、IK使用
IK有两种颗粒度的拆分:
: 会做最粗粒度的拆分
: 会将文本做最细粒度的拆分
1) ik_smart 拆分
运行结果
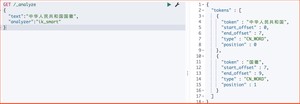
2)ik_max_word 拆分
运行结果
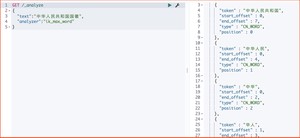
1、Elasticsearch Analyzers
2、Elasticsearch 分词器
3、Elasticsearch拼音分词和IK分词的安装及使用

版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/7354.html