
你好呀,我是 JUnit,一个开源的 Java 单元测试框架。在了解我之前,先来了解一下什么是单元测试。单元测试,就是针对最小的功能单元编写测试代码。在 Java 中,最小的功能单元就是方法,因此,对 Java 程序员进行单元测试实际上就是对 Java 方法的测试。
为什么要进行单元测试呢?因为单元测试可以确保你编写的代码是符合软件需求和遵循开发规范的。单元测试是所有测试中最底层的一类测试,是第一个环节,也是最重要的一个环节,是唯一一次能够达到代码覆盖率 100% 的测试,是整个软件测试过程的基础和前提。可以这么说,单元测试的性价比是最好的。
微软公司之前有这样一个统计:bug 在单元测试阶段被发现的平均耗时是 3.25 小时,如果遗漏到系统测试则需要 11.5 个小时。

经我这么一说,你应该已经很清楚单元测试的重要性了。那在你最初编写测试代码的时候,是不是经常这么做?就像下面这样。
要测试 方法正确性,你在 方法中编写了一段测试代码。如果你这么做过的话,我只能说你也曾经青涩天真过啊!使用 方法来测试有很多坏处,比如说:
1)测试代码没有和源代码分开。
2)不够灵活,很难编写一组通用的测试代码。
3)无法自动打印出预期和实际的结果,没办法比对。
但如果学会使用我——JUnit 的话,就不会再有这种困扰了。我可以非常简单地组织测试代码,并随时运行它们,还能给出准确的测试报告,让你在最短的时间内发现自己编写的代码到底哪里出了问题。
好了,既然知道了我这么优秀,那还等什么,直接上手吧!我最新的版本是 JUnit 5,Intellij IDEA 中已经集成了,所以你可以直接在 IDEA 中编写并运行我的测试用例。
第一步,直接在当前的代码编辑器窗口中按下 键(Mac 版),在弹出的菜单中选择「Test...」。
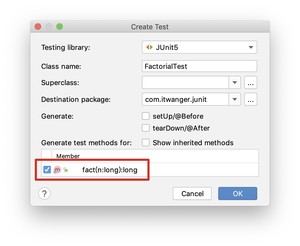
勾选上要编写测试用例的方法 ,然后点击「OK」。
此时,IDEA 会自动在当前类所在的包下生成一个类名带 Test(惯例)的测试类。如下图所示。
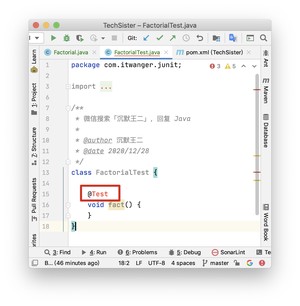
如果你是第一次使用我的话,IDEA 会提示你导入我的依赖包。建议你选择最新的 JUnit 5.4。
导入完毕后,你可以打开 pom.xml 文件确认一下,里面多了对我的依赖。
第二步,在测试方法中添加一组断言,如下所示。
注解是我要求的,我会把带有 的方法识别为测试方法。在测试方法内部,你可以使用 对期望的值和实际的值进行比对。
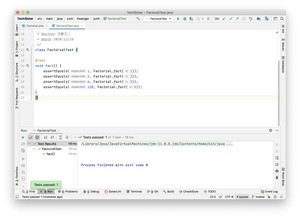
第三步,你可以在邮件菜单中选择「Run FactorialTest」来运行测试用例,结果如下所示。
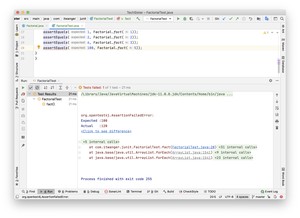
测试失败了,因为第 20 行的预期结果和实际不符,预期是 100,实际是 120。此时,你要么修正实现代码,要么修正测试代码,直到测试通过为止。
不难吧?单元测试可以确保单个方法按照正确的预期运行,如果你修改了某个方法的代码,只需确保其对应的单元测试通过,即可认为改动是没有问题的。
在一个测试用例中,可能要对多个方法进行测试。在测试之前呢,需要准备一些条件,比如说创建对象;在测试完成后呢,需要把这些对象销毁掉以释放资源。如果在多个测试方法中重复这些样板代码又会显得非常啰嗦。
这时候,该怎么办呢?
我为你提供了 和 ,作为一个文化人,我称之为“瞻前顾后”。来看要测试的代码。
新建测试用例的时候记得勾选 和 。
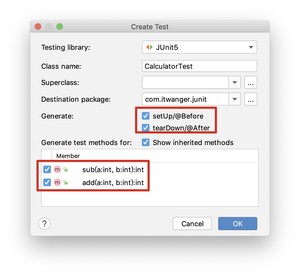
生成后的代码如下所示。
的 方法会在运行每个 方法之前运行; 的 方法会在运行每个 方法之后运行。
与之对应的还有 和 ,与 和 不同的是,All 通常用来初始化和销毁静态变量。
对于 Java 程序来说,异常处理也非常的重要。对于可能抛出的异常进行测试,本身也是测试的一个重要环节。
还拿之前的 Factorial 类来进行说明。在 方法的一开始,对参数 n 进行了校验,如果小于 0,则抛出 IllegalArgumentException 异常。
在 FactorialTest 中追加一个测试方法 。
我为你提供了一个 的方法,第一个参数是异常的类型,第二个参数 Executable,可以封装产生异常的代码。如果觉得匿名内部类写起来比较复杂的话,可以使用 Lambda 表达式。
有时候,由于某些原因,某些方法产生了 bug,需要一段时间去修复,在修复之前,该方法对应的测试用例一直是以失败告终的,为了避免这种情况,我为你提供了 注解。
注解也可以不需要说明,但我建议你还是提供一下,简单地说明一下为什么这个测试方法要忽略。在上例中,如果团队的其他成员看到说明就会明白,当编号 43 的 bug 修复后,该测试方法会重新启用的。即便是为了提醒自己,也很有必要,因为时间长了你可能自己就忘了,当初是为什么要忽略这个测试方法的。
有时候,你可能需要在某些条件下运行测试方法,有些条件下不运行测试方法。针对这场使用场景,我为你提供了条件测试。
1)不同的操作系统,可能需要不同的测试用例,比如说 Linux 和 Windows 的路径名是不一样的,通过 注解就可以针对不同的操作系统启用不同的测试用例。
2)不同的 Java 运行环境,可能也需要不同的测试用例。 和 注解就可以满足这个需求。
最后,给你说三句心里话吧。在编写单元测试的时候,你最好这样做:
1)单元测试的代码本身必须非常名单明了,能一下看明白,决不能再为测试代码编写测试代码。
2)每个单元测试应该互相独立,不依赖运行时的顺序。
3)测试时要特别注意边界条件,比如说 0,,空字符串"" 等情况。
希望我能尽早的替你发现代码中的 bug,毕竟越早的发现,造成的损失就会越小。see you!

我是 fastjson,是个地地道道的杭州土著,但我始终怀揣着一颗走向全世界的雄心。这不,我在 GitHub 上的简介都换成了英文,国际范十足吧?

如果你的英语功底没有我家老板 666 的话,我可以简单地翻译下(说人话,不装逼)。
我是阿里巴巴开源的一款 JSON 解析库,可以将 Java 对象序列化成 JSON 字符串,同时也可以将 JSON 字符串反序列化为 Java 对象。
- 我提供了服务器端和安卓客户端两种解析工具,性能表现还不错。
- 我提供了便捷的方式来进行 Java 对象和 JSON 之间的互转, 方法用来序列化, 方法用来反序列化。
- 我允许转换预先存在的无法修改的对象(只有 class、没有源代码)。
- 对 Java 泛型有着广泛的支持。
- 我支持任意复杂的对象(深度的继承层次)。
2012 年的时候,我就被开源中国评选为最受欢迎的国产开源软件之一。时隔多年,我的流行趋势没有丝毫减退,在 JSON 领域,我敢说我是 NO 1,因为我在 GitHub 上的粉丝数已经超过了 22k,没有任何人敢忽视我这样的成就。
在使用我的 API 之前,需要先在 pom.xml 文件中引入我的依赖。
我来写一个简单的测试用例,你看一下。
Writer 是一个普通的 Java 类,有两个字段,分别是 age 和 name,还有它们俩对应的 getter 和 setter 方法。
方法中创建了一个 Writer 对象,然后调用我提供的一个静态方法 来得到 JSON 字符串。
来看一下打印后的结果。
如果想反序列化的话,执行以下的代码即可。
调用静态方法 ,传递两个参数,一个是 JSON 字符串,一个是对象的类型。
如果想把 JSON 字符串转成集合的话,需要调用另外一个静态方法 。
如果没有特殊要求的话,我敢这么说,以上 3 个方法就可以覆盖到你绝大多数的业务场景了。
有时候,你的 JSON 字符串中的 key 可能与 Java 对象中的字段不匹配,比如大小写;有时候,你需要指定一些字段序列化但不反序列化;有时候,你需要日期字段显示成指定的格式。
这些特殊场景,我统统为你考虑到了,只需要在对应的字段上加上 注解就可以了。
先来看一下 注解的定义吧。
name 用来指定字段的名称,format 用来指定日期格式,serialize 和 deserialize 用来指定是否序列化和反序列化。
我建议在 getter 字段上使用 注解。来看一下测试代码。
此时的输出结果如下所示。
JSON 字符串中的 Age 首字母为大写,birthday 的格式符合“年月日”的预期,name 字段没有出现在结果中,说明没有被序列化。
为了满足更多个性化的需求,我在 SerializerFeature 类中定义了很多特性,你可以在调用 方法的时候进行指定。
- PrettyFormat,让 JSON 格式打印得更漂亮一些
- WriteClassName,输出类名
- UseSingleQuotes,key 使用单引号
- WriteNullListAsEmpty,List 为空则输出 []
- WriteNullStringAsEmpty,String 为空则输出“”
等等等等,更多新技能,等待你去开锁。我这里写个简单的 demo 供你参考。
对比一下配置前和配置后的结果。
众所周知,把 Java 对象序列化成 JSON 字符串,是不可能使用字符串直接拼接的,因为这样性能很差。比字符串拼接更好的办法就是使用 。
StringBuilder 尽管已经很好了,但在性能上还有上升的空间。“自己动手,丰衣足食”,于是我就创造了一个 SerializeWriter 类,专门用来序列化。
SerializeWriter 类中包含了一个 ,每序列化一次,都要做一次分配,但我使用了 ThreadLocal 来进行优化,这样就能够有效地减少对象的分配和垃圾回收,从而提升性能。
除此之外,还有很多其他的细节,比如说使用 IdentityHashMap 而不是 HashMap,既可以避免多余的 操作,又可以避免多线程并发情况下的死循环。
再比如说,使用 asm 技术来避免反射导致的开销。

我承认,快的同时,也带来了一些安全性的问题。尤其是 AutoType 的引入,让黑客有了可乘之机。
1.2.59 发布,增强 AutoType 打开时的安全性
1.2.60 发布,增加了 AutoType 黑名单,修复拒绝服务安全问题
1.2.61 发布,增加 AutoType 安全黑名单
1.2.62 发布,增加 AutoType 黑名单、增强日期反序列化和 JSONPath
1.2.66 发布,Bug 修复安全加固,并且做安全加固,补充了 AutoType 黑名单
1.2.67 发布,Bug 修复安全加固,补充了 AutoType 黑名单
1.2.68 发布,支持 GEOJSON,补充了 AutoType 黑名单。(引入一个 safeMode 的配置,配置 safeMode 后,无论白名单和黑名单,都不支持 autoType。)
1.2.69 发布,修复新发现高危 AutoType 开关绕过安全漏洞,补充了 AutoType 黑名单
1.2.70 发布,提升兼容性,补充了 AutoType 黑名单
在于黑客的反复较量中,我虽然变得越来越稳重成熟了,但与此同时,让我的用户为此也付出了沉重的代价。
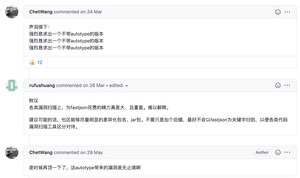
网络上也出现了很多不和谐的声音,他们声称我是最垃圾的国产开源软件之一,只不过凭借着一些投机取巧赢得了国内开发者的信赖。
但更多的是,对我的不离不弃。
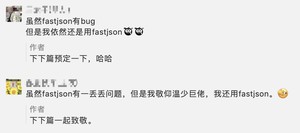
最令我感到为之动容的一句话是:
温少几乎凭一己之力撑起了一个被广泛使用 JSON 库,而其他库几乎都是靠一整个团队,就凭这一点,温少作为“初心不改的阿里初代开源人”,当之无愧。
出现漏洞并不可怕,可怕的是发现不了漏洞,或者说无法解决掉漏洞。
为了彻底解决 AutoType 带来的问题,在 1.2.68 版本中,我引入了 safeMode 的安全模式,无论白名单和黑名单,都不支持 AutoType,这样就可以彻底地杜绝攻击。
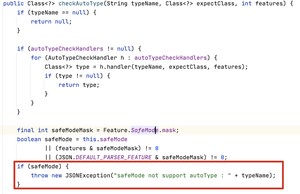
安全模式下, 方法会直接抛出异常。
不管前面的路还有多少艰难困苦,也不管还要面对多少风言风语,我都会砥砺前行,为了国产开源软件的蓬勃发展,我愿意做一个先驱者,也愿意做一个持久战者。
2020 年的最后一篇文章!看到的就点个赞吧,2021 年顺顺利利。
我叫 Gson,是一款开源的 Java 库,主要用途为序列化 Java 对象为 JSON 字符串,或反序列化 JSON 字符串成 Java 对象。从我的名字上,就可以看得出一些端倪,我并非籍籍无名,我出身贵族,我爸就是 Google,市值富可敌国。
当然了,作为一个聪明人,我是有自知之明的,我在我爸眼里,我并不是最闪耀的那颗星。
我来到这个世上,纯属一次意外,反正我爸是这样对我说的,他总说我是从河边捡回来的,虽然我一直不太相信。对于这件事,我向我妈确认过,她听完笑得合不拢嘴,说我太天真。
长大后,我喜欢四处闯荡,因此结识了不少同行,其中就有 Jackson 和 Fastjson。
说起 Jackson,我总能第一时间想到 MJ,那个被上帝带走的流行天王。Jackson 在 GitHub 上有 6.1k 的 star,虽然他的粉丝数没我多,但作为 Spring Boot 的默认 JSON 解析器,我非常地尊重他。
Fastjson 来自神秘的东方,虽然爆出过一些严重的漏洞,但这并不妨碍他成为最受欢迎的 JSON 解析器,他的粉丝数比我还要多,尽管我已经有超过 18K 的 star。
外人总说我们是竞争对手,但我必须得告诉他们,我们仨的关系,好到就差穿同一条内裤了。
我们各有优势,Jackson 在运行时占用的内存较少,Fastjson 的速度更快,而我,可以处理任意的 Java 对象,甚至在没有源代码的情况下。另外,我对泛型的支持也更加的友好。
在使用我的 API 之前,需要先把我添加到项目当中,推荐使用 Maven 和 Gradle 两种形式。
Maven:
Gradle:
PS:Gradle 是一个基于 Apache Ant 和 Apache Maven 概念的项目自动化建构工具。Gradle 构建脚本使用的是 Groovy 或 Kotlin 的特定领域语言来编写的,而不是传统的 XML。
不是我觉得,是真的,通过大量的测试证明,我在处理 JSON 的时候性能还是很牛逼的。
测试环境:双核,8G 内存,64 位的 Ubuntu 操作系统(以桌面应用为主的 Linux 发行版)
测试结果:
1)在反序列化 25M 以上的字符串时没有出现过任何问题。
2)可以序列化 140 万个对象的集合。
3)可以反序列化包含 87000 个对象的集合。
4)将字节数组和集合的反序列化限制从 80K 提高到 11M 以上。
测试用例我已经帮你写好了,放在 GitHub 上,如果你不相信的话,可以验证一下。
https://github.com/google/gson/blob/master/gson/src/test/java/com/google/gson/metrics/PerformanceTest.java
不是我自吹自擂,是真的,我还是挺好用的,上手难度几乎为零。如果你不相信话,可以来试试。
我有一个女朋友,她的名字和我一样,也叫 ,我的主要功能都由她来提供。你可以通过 的这种简单粗暴的方式创建她,也可以打电话给一个叫 GsonBuilder 的老板,让他邮寄一个复刻版过来,真的,我不骗你。
先来看一个序列化的例子。
在我女朋友的帮助下,你可以将基本数据类型 int、字符串类型 String、包装器类型 Integer、int 数组等等作为参数,传递给 方法,该方法将会返回一个 JSON 形式的字符串。
来看一下输出结果:
再来看一下反序列化的例子。
方法用于序列化,对应的, 方法用于反序列化。不过,你需要在反序列化的时候,指定参数的类型,是 int 还是 Integer,是 Boolean 还是 String,或者 String 数组。
来看一下输出结果:
上面的例子都比较简单,还体现不出来我的威力。
下面,我们来自定义一个类:
然后,我们来将其序列化:
用法和之前一样简单,来看一下输出结果:
同样,可以将结果反序列化:
这里有一些注意事项,我需要提醒你。
1)推荐使用 修饰字段。
2)不需要使用任何的注解来表明哪些字段需要序列化,哪些字段不需要序列化。默认情况下,包括所有的字段,以及从父类继承过来的字段。
3)如果一个字段被 关键字修饰的话,它将不参与序列化。
4)如果一个字段的值为 null,它不会在序列化后的结果中显示。
5)JSON 中缺少的字段将在反序列化后设置为默认值,引用数据类型的默认值为 null,数字类型的默认值为 0,布尔值默认为 false。
接下来,来看一个序列化集合的例子。
结果如下所示:
反序列化的时候,也很简单。
结果如下所示:
我女朋友是一个很细心也很贴心的人,在你调用 方法进行序列化的时候,她会先判 null,防止抛出 NPE,再通过 获取参数的类型,然后进行序列化。
但是呢?对于泛型来说, 的时候会丢掉参数化类型。来看下面这个例子。
假如你 debug 的时候,进入到 方法的内部,就可以观察到。

foo 的实际类型为 ,但我女朋友在调用 的时候,只会得到 Foo,这就意味着她并不知道 foo 的实际类型。
序列化的时候还好,反序列化的时候就无能为力了。
这段代码在运行的时候就报错了。
默认情况下,泛型的参数类型会被转成 LinkedTreeMap,这显然并不是我们预期的 Bar,女朋友对此表示很无奈。
作为 Google 的亲儿子,我的血液里流淌着“贵族”二字,我又怎能忍心女朋友无助时的落寞。
于是,我在女朋友的体内植入了另外两种方法,带 Type 类型参数的:
这样的话,你在进行泛型的序列化和反序列化时,就可以指定泛型的参数化类型了。
debug 进入 方法内部查看的话,就可以看到 foo 的真实类型了。

在反序列化的时候,和此类似。
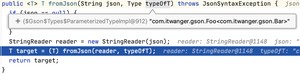
这样的话,bar1 就可以通过 到了。
瞧,我考虑得多周全,女朋友都忍不住夸我了!
你知道的,Java 不建议使用混合类型,也就是下面这种情况。
Event 的定义如下所示:
由于 list 没有指定具体的类型,因此它里面可以存放各种类型的数据。这样虽然省事,我女朋友在序列化的时候也没问题,但反序列化的时候就要麻烦多了。
输出结果如下所示:
反序列化的时候,就需要花点心思才能拿到 Event 对象。
承认了,JsonParser 是我的前任。希望你不要喷我渣男,真不是我花心,是因为我们性格上有些不太适合。但我们仍然保持着朋友的关系,因为我们谁都没有错,只是代码更加规范了,已经很少有开发者使用混合类型了。
考虑到你是一个追求时髦的人,我一直对自己要求很高,力争能够满足你的所有需求。这种高标准的要求,让我女朋友对我是又爱又恨。
爱的是,我这种追求完美的态度;恨的是,她有时候力不从心,帮不上忙。
使用 序列化 Java 对象时,返回的 JSON 字符串中没有空格,很紧凑。如果你想要打印更漂亮的 JSON 格式,你需要打电话给一个叫 GsonBuilder 的老板,让他进行一些定制,然后再把复刻版邮寄给你,就像我在使用指南中提到的那样。
来对比一下输出结果:
通过 定制后,输出的格式更加层次化、立体化,字段与值之间有空格,每个不同的字段之间也会有换行。
之前提到了,默认情况下,我女朋友在序列化的时候会忽略 null 值的字段,如果不想这样的话,同样可以打电话给 GsonBuilder。
来对比一下输出结果:
通过 定制后,序列化的时候就不会再忽略 null 值的字段。
也许,你在序列化和反序列化的时候想要筛选一些字段,我也考虑到这种需求了,特意为你准备了几种方案,你可以根据自己的口味挑选适合你的。
第一种,通过 Java 修饰符。
你之前也看到了,使用 关键字修饰的字段将不会参与序列化和反序列化。同样的, 关键字修饰的字段也不会。如果你想保留这些关键字修饰的字段,可以这样做。
保留单种。
保留多种。
第二种,通过 注解。
要使用 注解,你需要先这样做:
再在需要序列化和反序列化的字段上加上 注解,如果没加的话,该字段将会被忽略。
如果你还想了解更多的话,请来参观我的 GitHub 主页:
https://github.com/google/gson
我会向你坦露我的一切,毫不保留的,除了我和女朋友之间的一些秘密,只为能够帮助到你。
如果你觉得我有点用的话,不妨点个赞,留个言,see you。
在当今的编程世界里,JSON 已经成为将信息从客户端传输到服务器端的首选协议,可以好不夸张的说,XML 就是那个被拍死在沙滩上的前浪。
很不幸的是,JDK 没有 JSON 库,不知道为什么不搞一下。Log4j 的时候,为了竞争,还推出了 java.util.logging,虽然最后也没多少人用。
Java 之所以牛逼,很大的功劳在于它的生态非常完备,JDK 没有 JSON 库,第三方类库有啊,还挺不错,比如说本篇的猪脚——Jackson,GitHub 上标星 6.1k,Spring Boot 的默认 JSON 解析器。
怎么证明这一点呢?
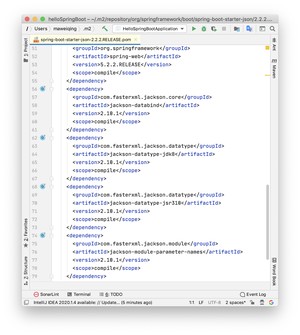
当我们通过 starter 新建一个 Spring Boot 的 Web 项目后,就可以在 Maven 的依赖项中看到 Jackson 的身影。
Jackson 有很多优点:
- 解析大文件的速度比较快;
- 运行时占用的内存比较少,性能更佳;
- API 很灵活,容易进行扩展和定制。
Jackson 的核心模块由三部分组成:
- jackson-core,核心包,提供基于“流模式”解析的相关 API,包括 JsonPaser 和 JsonGenerator。
- jackson-annotations,注解包,提供标准的注解功能;
- jackson-databind ,数据绑定包,提供基于“对象绑定”解析的相关 API ( ObjectMapper ) 和基于“树模型”解析的相关 API (JsonNode)。
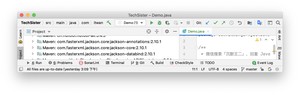
要想使用 Jackson,需要在 pom.xml 文件中添加 Jackson 的依赖。
jackson-databind 依赖于 jackson-core 和 jackson-annotations,所以添加完 jackson-databind 之后,Maven 会自动将 jackson-core 和 jackson-annotations 引入到项目当中。
Maven 之所以讨人喜欢的一点就在这,能偷偷摸摸地帮我们把该做的做了。
Jackson 最常用的 API 就是基于”对象绑定” 的 ObjectMapper,它通过 writeValue 的系列方法将 Java 对象序列化为 JSON,并且可以存储成不同的格式。
- 方法,将对象存储成字符串
- 方法,将对象存储成字节数组
- 方法,将对象存储成文件
来看一下存储成字符串的代码示例:
程序输出结果如下所示:
不是所有的字段都支持序列化和反序列化,需要符合以下规则:
- 如果字段的修饰符是 public,则该字段可序列化和反序列化(不是标准写法)。
- 如果字段的修饰符不是 public,但是它的 getter 方法和 setter 方法是 public,则该字段可序列化和反序列化。getter 方法用于序列化,setter 方法用于反序列化。
- 如果字段只有 public 的 setter 方法,而无 public 的 getter 方 法,则该字段只能用于反序列化。
如果想更改默认的序列化和反序列化规则,需要调用 ObjectMapper 的 方法。否则将会抛出 InvalidDefinitionException 异常。
ObjectMapper 通过 readValue 的系列方法从不同的数据源将 JSON 反序列化为 Java 对象。
- 方法,将字符串反序列化为 Java 对象
- 方法,将字节数组反序列化为 Java 对象
- 方法,将文件反序列化为 Java 对象
来看一下将字符串反序列化为 Java 对象的代码示例:
程序输出结果如下所示:
PS:如果反序列化的对象有带参的构造方法,它必须有一个空的默认构造方法,否则将会抛出 一行。
Jackson 最常用的 API 就是基于”对象绑定” 的 ObjectMapper,
ObjectMapper 也可以将 JSON 解析为基于“树模型”的 JsonNode 对象,来看下面的示例。
借助 TypeReference 可以将 JSON 字符串数组转成泛型 List,来看下面的示例:
Jackson 之所以牛掰的一个很重要的因素是可以实现高度灵活的自定义配置。
在实际的应用场景中,JSON 中常常会有一些 Java 对象中没有的字段,这时候,如果直接解析的话,会抛出 UnrecognizedPropertyException 异常。
下面是一串 JSON 字符串:
但 Java 对象 Writer 中没有定义 sex 字段:
我们来尝试解析一下:
不出意外,抛出异常了,sex 无法识别。
怎么办呢?可以通过 方法忽略掉这些“无法识别”的字段。
除此之外,还有其他一些有用的配置信息,来了解一下:
对于日期类型的字段,比如说 java.util.Date,如果不指定格式,序列化后将显示为 long 类型的数据,这种默认格式的可读性很差。
怎么办呢?
第一种方案,在 getter 上使用 注解。
再来看一下结果:
具体代码如下所示:
第二种方案,调用 ObjectMapper 的 方法。
输出结果如下所示:
在将 Java 对象序列化为 JSON 时,可能有些字段需要过滤,不显示在 JSON 中,Jackson 有一种比较简单的实现方式。
@JsonIgnore 用于过滤单个字段。
@JsonIgnoreProperties 用于过滤多个字段。
当 Jackson 默认序列化和反序列化不能满足实际的开发需要时,可以自定义新的序列化和反序列化类。
自定义的序列化类需要继承 StdSerializer,同时重写 方法,利用 JsonGenerator 生成 JSON,示例如下:
定义好自定义序列化类后,要想在程序中调用它们,需要将其注册到 ObjectMapper 的 Module 中,示例如下所示:
程序输出结果如下所示:
自定义序列化类 CustomSerializer 中没有添加 age 字段,所以只输出了 name 字段。
再来看一下自定义的反序列化类,继承 StdDeserializer,同时重写 方法,利用 JsonGenerator 读取 JSON,示例如下:
通过 JsonNode 把 JSON 读取到一个树形结构中,然后通过 JsonNode 的 get 方法将对应字段读取出来,然后生成新的 Java 对象,并返回。
定义好自定义反序列化类后,要想在程序中调用它们,同样需要将其注册到 ObjectMapper 的 Module 中,示例如下所示:
程序输出结果如下所示:
哎呀,好像不错哦,Jackson 绝对配得上“最牛掰”这三个字,虽然有点虚。如果只想简单的序列化和反序列化,使用 ObjectMapper 的 write 和 read 方法即可。
如果还想更进一步的话,就需要对 ObjectMapper 进行一些自定义配置,或者加一些注解,以及直接自定义序列化和反序列化类,更贴近一些 Java 对象。
需要注意的是,对日期格式的字段要多加小心,尽量不要使用默认配置,可读性很差。
好了,通过这篇文章的系统化介绍,相信你已经完全摸透 Jackson 了,我们下篇文章见。
空了的时候,我都会在群里偷偷摸摸地潜水,对小伙伴们的一举一动、一言一行筛查诊断。一副班主任的即时感,让我感到非常的快乐,略微夹带一丝丝的枯燥。
这不,我在战国时代读者群里发现了这么一串聊天记录:
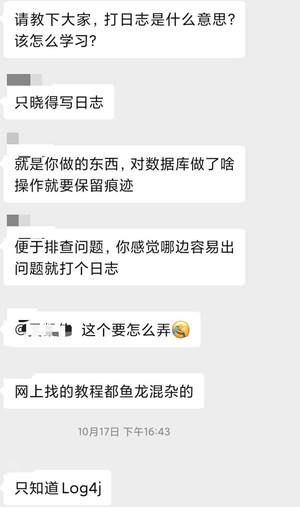
竟然有小伙伴不知道“打日志”是什么意思,不知道该怎么学习,还有小伙伴回答说,只知道 Log4j!
有那么一刻,我遭受到了一万点暴击,内心莫名的伤感,犹如一匹垂头丧气的狗。因为网络上总有一些不怀好意的人不停地攻击我,说我写的文章入门,毫无深度——他们就是我命中注定的黑子,不信你到脉脉上搜“沉默王二”,就能看到他们毫无新意的抨击。
我就想问一下,怎么了,入门的文章有入门的群体需要,而我恰好帮助了这么一大批初学者,我应该受到褒奖好不好?
(说好的不在乎,怎么在乎起来了呢?手动狗头)

管他呢,我行我素吧,保持初心不改就对了!这篇文章就来说说 Log4j,这个打印日志的鼻祖。Java 中的日志打印其实是个艺术活,我保证,这句话绝不是忽悠。
事实证明,打印日志绝逼会影响到程序的性能,这是不可否认的,毕竟多做了一项工作。尤其是在交易非常频繁的程序里,涌现大量的日志确实会比较低效。
基于性能上的考量,小伙伴们很有必要认认真真地学习一下如何优雅地打印 Java 日志。毕竟,性能是一个程序员优不优秀的重要考量。
恐怕是我们在学习 Java 的时候,最常用的一种打印日志的方式了,几乎每个 Java 初学者都这样干过,甚至一些老鸟。
之所以这样打印日志,是因为很方便,上手难度很低,尤其是在 IDEA 的帮助下,只需在键盘上按下 两个字母就可以调出 。
在本地环境下,使用 打印日志是没问题的,可以在控制台看到信息。但如果是在生产环境下的话, 就变得毫无用处了。
控制台打印出的信息并没有保存到日志文件中,只能即时查看,在一屏日志的情况下还可以接受。如果日志量非常大,控制台根本就装不下。所以就需要更高级的日志记录 API(比如 Log4j 和 java.util.logging)。
它们可以把大量的日志信息保存到文件中,并且控制每个文件的大小,如果满了,就存储到下一个,方便查找。
使用 Java 日志的时候,一定要注意日志的级别,比如常见的 DEBUG、INFO、WARN 和 ERROR。
DEBUG 的级别最低,当需要打印调试信息的话,就用这个级别,不建议在生产环境下使用。
INFO 的级别高一些,当一些重要的信息需要打印的时候,就用这个。
WARN,用来记录一些警告类的信息,比如说客户端和服务端的连接断开了,数据库连接丢失了。
ERROR 比 WARN 的级别更高,用来记录错误或者异常的信息。
FATAL,当程序出现致命错误的时候使用,这意味着程序可能非正常中止了。
OFF,最高级别,意味着所有消息都不会输出了。
这个级别是基于 Log4j 的,和 java.util.logging 有所不同,后者提供了更多的日志级别,比如说 SEVERE、FINER、FINEST。

为什么说错误的日志记录方式会影响程序的性能呢?因为日志记录的次数越多,意味着执行文件 IO 操作的次数就越多,这也就意味着会影响到程序的性能,能 get 吧?
虽然说普通硬盘升级到固态硬盘后,读写速度快了很多,但磁盘相对于内存和 CPU 来说,还是太慢了!就像马车和奔驰之间的速度差距。
这也就是为什么要选择日志级别的重要性。对于程序来说,记录日志是必选项,所以能控制的就是日志的级别,以及在这个级别上打印的日志。
对于 DEBUG 级别的日志来说,一定要使用下面的方式来记录:
当 DEBUG 级别是开启的时候再打印日志,这种方式在你看很多源码的时候就可以发现,很常见。
切记,在生产环境下,一定不要开启 DEBUG 级别的日志,否则程序在大量记录日志的时候会变很慢,还有可能在你不注意的情况下,悄悄地把磁盘空间撑爆。

java.util.logging 属于原生的日志 API,Log4j 属于第三方类库,但我建议使用 Log4j,因为 Log4j 更好用。java.util.logging 的日志级别比 Log4j 更多,但用不着,就变成了多余。
Log4j 的另外一个好处就是,不需要重新启动 Java 程序就可以调整日志的记录级别,非常灵活。可以通过 log4j.properties 文件来配置 Log4j 的日志级别、输出环境、日志文件的记录方式。
Log4j 还是线程安全的,可以在多线程的环境下放心使用。
先来看一下 java.util.logging 的使用方式:
程序运行后会在 target 目录下生成一个名叫 javautillog.txt 的文件,内容如下所示:

再来看一下 Log4j 的使用方式。
第一步,在 pom.xml 文件中引入 Log4j 包:
第二步,在 resources 目录下创建 log4j.properties 文件,内容如下所示:
1)配置根 Logger,语法如下所示:
level 就是日志的优先级,从高到低依次是 ERROR、WARN、INFO、DEBUG。如果这里定义的是 INFO,那么低级别的 DEBUG 日志信息将不会打印出来。
appenderName 就是指把日志信息输出到什么地方,可以指定多个地方,当前的配置文件中有 3 个地方,分别是 stdout、D、E。
2)配置日志输出的目的地,语法如下所示:
Log4j 提供的目的地有下面 5 种:
- org.apache.log4j.ConsoleAppender:控制台
- org.apache.log4j.FileAppender:文件
- org.apache.log4j.DailyRollingFileAppender:每天产生一个文件
- org.apache.log4j.RollingFileAppender:文件大小超过阈值时产生一个新文件
- org.apache.log4j.WriterAppender:将日志信息以流格式发送到任意指定的地方
3)配置日志信息的格式,语法如下所示:
Log4j 提供的格式有下面 4 种:
- org.apache.log4j.HTMLLayout:HTML 表格
- org.apache.log4j.PatternLayout:自定义
- org.apache.log4j.SimpleLayout:包含日志信息的级别和信息字符串
- org.apache.log4j.TTCCLayout:包含日志产生的时间、线程、类别等等信息
自定义格式的参数如下所示:
- %m:输出代码中指定的消息
- %p:输出优先级
- %r:输出应用启动到输出该日志信息时花费的毫秒数
- %c:输出所在类的全名
- %t:输出该日志所在的线程名
- %n:输出一个回车换行符
- %d:输出日志的时间点
- %l:输出日志的发生位置,包括类名、线程名、方法名、代码行数,比如:
第三步,写个使用 Demo:
1)获取 Logger 对象
要使用 Log4j 的话,需要先获取到 Logger 对象,它用来负责日志信息的打印。通常的格式如下所示:
2)打印日志
有了 Logger 对象后,就可以按照不同的优先级打印日志了。常见的有以下 4 种:
程序运行后会在 target 目录下生成两个文件,一个名叫 debug.log,内容如下所示:
另外一个名叫 error.log,内容如下所示:
1)在打印 DEBUG 级别的日志时,切记要使用 !那小伙伴们肯定非常好奇,为什么要这样做呢?
先来看一下 方法的源码:
内部使用了 方法进行了日志级别的判断,如果 DEBUG 是禁用的话,就 return false 了。
再来看一下 方法的源码:
咦,不是也用 方法判断吗?难道使用 不是画蛇添足吗?直接用 不香吗?我来给小伙伴们解释下。
如果我们在打印日志信息的时候需要附带一个方法去获取参数值,就像下面这样:
假如 方法需要耗费的时间长达 6 秒,那完了!尽管配置文件里的日志级别定义的是 INFO, 方法仍然会倔强地执行 6 秒,完事后再 ,这就很崩了!
明明 INFO 的时候 是不执行的,意味着 也不需要执行的,偏偏就执行了 6 秒,是不是很傻?
换成上面这种方式,那确定此时 是不执行的,对吧?
为了程序性能上的考量, 就变得很有必要了!假如说 的时候没有传参,确实是不需要判断 DEBUG 是否启用的。
2)慎重选择日志信息的打印级别,因为这太重要了!如果只能通过日志查看程序发生了什么问题,那必要的信息是必须要打印的,但打印得太多,又会影响到程序的性能。
所以,该 INFO 的 ,该 DEBUG 的 ,不要随便用。
3)使用 Log4j 而不是 、 或者 来打印日志,原因之前讲过了,就不再赘述了。
4)使用 log4j.properties 文件来配置日志,尽管它不是必须项,使用该文件会让程序变得更灵活,有一种我的地盘我做主的味道。
5)不要忘记在打印日志的时候带上类的全名和线程名,在多线程环境下,这点尤为重要,否则定位问题的时候就太难了。
6)打印日志信息的时候尽量要完整,不要太过于缺省,尤其是在遇到异常或者错误的时候(信息要保留两类:案发现场信息和异常堆栈信息,如果不做处理,通过 throws 关键字往上抛),免得在找问题的时候都是一些无用的日志信息。
7)要对日志信息加以区分,把某一类的日志信息在输出的时候加上前缀,比如说所有数据库级别的日志里添加 ,这样的日志非常大的时候可以通过 这样的 Linux 命令快速定位。
8)不要在日志文件中打印密码、银行账号等敏感信息。

打印日志真的是一种艺术活,搞不好会严重影响服务器的性能。最可怕的是,记录了日志,但最后发现屁用没有,那简直是苍了个天啊!尤其是在生产环境下,问题没有记录下来,但重现有一定的随机性,到那时候,真的是叫天天不应,叫地地不灵啊!
Log4j 2,顾名思义,它就是 Log4j 的升级版,就好像手机里面的 Pro 版。我作为一个写文章方面的工具人,或者叫打工人,怎么能不写完这最后一篇。
Log4j、SLF4J、Logback 是一个爹——Ceki Gulcu,但 Log4j 2 却是例外,它是 Apache 基金会的产品。
SLF4J 和 Logback 作为 Log4j 的替代品,在很多方面都做了必要的改进,那为什么还需要 Log4j 2 呢?我只能说 Apache 基金会的开发人员很闲,不,很拼,要不是他们这种精益求精的精神,这个编程的世界该有多枯燥,毕竟少了很多可以用“拿来就用”的轮子啊。
上一篇也说了,老板下死命令要我把日志系统切换到 Logback,我顺利交差了,老板很开心,夸我这个打工人很敬业。为了表达对老板的这份感谢,我决定偷偷摸摸地试水一下 Log4j 2,尽管它还不是个成品,可能会会项目带来一定的隐患。但谁让咱是一个敬岗爱业的打工人呢。

1)在多线程场景下,Log4j 2 的吞吐量比 Logback 高出了 10 倍,延迟降低了几个数量级。这话听起来像吹牛,反正是 Log4j 2 官方自己吹的。
Log4j 2 的异步 Logger 使用的是无锁数据结构,而 Logback 和 Log4j 的异步 Logger 使用的是 ArrayBlockingQueue。对于阻塞队列,多线程应用程序在尝试使日志事件入队时通常会遇到锁争用。
下图说明了多线程方案中无锁数据结构对吞吐量的影响。 Log4j 2 随着线程数量的扩展而更好地扩展:具有更多线程的应用程序可以记录更多的日志。其他日志记录库由于存在锁竞争的关系,在记录更多线程时,总吞吐量保持恒定或下降。这意味着使用其他日志记录库,每个单独的线程将能够减少日志记录。
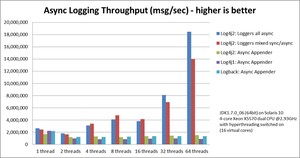
性能方面是 Log4j 2 的最大亮点,至于其他方面的一些优势,比如说下面这些,可以忽略不计,文字有多短就代表它有多不重要。
2)Log4j 2 可以减少垃圾收集器的压力。
3)支持 Lambda 表达式。
4)支持自动重载配置。
废话不多说,直接实操开干。理论知识有用,但不如上手实操一把,这也是我多年养成的一个“不那么良好”的编程习惯:在实操中发现问题,解决问题,寻找理论基础。
第一步,在 pom.xml 文件中添加 Log4j 2 的依赖:
(这个 artifactId 还是 log4j,没有体现出来 2,而在 version 中体现,多少叫人误以为是 log4j)
第二步,来个最简单的测试用例:
运行 Demo 类,可以在控制台看到以下信息:
Log4j 2 竟然没有在控制台打印“ log4j2”,还抱怨我们没有为它指定配置文件。在这一点上,我就觉得它没有 Logback 好,毕竟人家会输出。
这对于新手来说,很不友好,因为新手在遇到这种情况的时候,往往不知所措。日志里面虽然体现了 ERROR,但代码并没有编译出错或者运行出错,凭什么你不输出?
那作为编程老鸟来说,我得告诉你,这时候最好探究一下为什么。怎么做呢?
我们可以复制一下日志信息中的关键字,比如说:“No log4j2 configuration file found”,然后在 Intellij IDEA 中搜一下,如果你下载了源码和文档的话,不除意外,你会在 ConfigurationFactory 类中搜到这段话。
可以在方法中打个断点,然后 debug 一下,你就会看到下图中的内容。
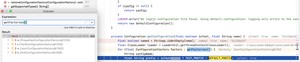
通过源码,你可以看得到,Log4j 2 会去寻找 4 种类型的配置文件,后缀分别是 properties、yaml、json 和 xml。前缀是 log4j2-test 或者 log4j2。
得到这个提示后,就可以进行第三步了。
第三步,在 resource 目录下增加 log4j2-test.xml 文件(方便和 Logback 做对比),内容如下所示:
Log4j 2 的配置文件格式和 Logback 有点相似,基本的结构为 元素,包含 0 或多个 元素,其后跟 0 或多个 元素,里面再跟最多只能存在一个的 元素。
1)配置 appender,也就是配置日志的输出目的地。
有 Console,典型的控制台配置信息上面你也看到了,我来简单解释一下里面 pattern 的格式:
- 表示输出到毫秒的时间
- 输出当前线程名称
- 输出日志级别,-5 表示左对齐并且固定输出 5 个字符,如果不足在右边补空格
- 输出 logger 名称,最多 36 个字符
- 日志文本
- 换行
顺带补充一下其他常用的占位符:
- 输出所在的类文件名,如 Demo.java
- 输出行号
- 输出所在方法名
- 输出语句所在的行数, 包括类名、方法名、文件名、行数
- 输出日志级别
- 输出包名,如果后面跟有 参数,比如说 ,它将输出报名的第一个字符,如 的实际报名将只输出
再次运行 Demo 类,就可以在控制台看到打印的日志信息了:
2)配置 Loggers,指定 Root 的日志级别,并且指定具体启用哪一个 Appenders。
3)自动重载配置。
Logback 支持自动重载配置,Log4j 2 也支持,那想要启用这个功能也非常简单,只需要在 Configuration 元素上添加 属性即可。
注意值要设置成非零,上例中的意思是至少 30 秒后检查配置文件中的更改。最小间隔为 5 秒。
除了 Console,还有 Async,可以配合文件的方式来异步写入,典型的配置信息如下所示:
对比 Logback 的配置文件来看,Log4j 2 真的复杂了一些,不太好用,就这么直白地说吧!但自己约的,含着泪也得打完啊。把这个 Async 加入到 Appenders:
再次运行 Demo 类,可以在项目根路径下看到一个 debug.log 文件,内容如下所示:
当然了,Log4j 和 Logback 我们都配置了 RollingFile,Log4j 2 也少不了。RollingFile 会根据 Triggering(触发)策略和 Rollover(过渡)策略来进行日志文件滚动。如果没有配置 Rollover,则使用 DefaultRolloverStrategy 来作为 RollingFile 的默认配置。
触发策略包含有,基于 cron 表达式(源于希腊语,时间的意思,用来配置定期执行任务的时间格式)的 CronTriggeringPolicy;基于文件大小的 SizeBasedTriggeringPolicy;基于时间的 TimeBasedTriggeringPolicy。
过渡策略包含有,默认的过渡策略 DefaultRolloverStrategy,直接写入的 DirectWriteRolloverStrategy。一般情况下,采用默认的过渡策略即可,它已经足够强大。
来看第一个基于 SizeBasedTriggeringPolicy 和 TimeBasedTriggeringPolicy 策略,以及缺省 DefaultRolloverStrategy 策略的配置示例:
为了验证文件的滚动策略,我们调整一下 Demo 类,让它多打印点日志:
再次运行 Demo 类,可以看到根目录下多了 3 个日志文件:

结合日志文件名,再来看 RollingFile 的配置,就很容易理解了。
1)fileName 用来指定文件名。
2)filePattern 用来指定文件名的模式,它取决于过渡策略。
由于配置文件中没有显式指定过渡策略,因此 RollingFile 会启用默认的 DefaultRolloverStrategy。
先来看一下 DefaultRolloverStrategy 的属性:
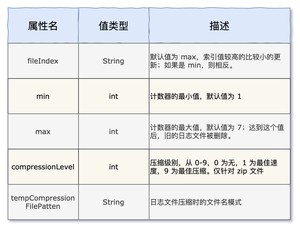
再来看 filePattern 的值 ,其中 很好理解,就是年月日;其中 是什么意思呢?
第一个日志文件名为 rolling.log(最近的日志放在这个里面),第二个文件名除去日期为 rolling-1.log,第二个文件名除去日期为 rolling-2.log,根据这些信息,你能猜到其中的规律吗?
其实和 DefaultRolloverStrategy 中的 max 属性有关,目前使用的默认值,也就是 7,那就当 rolling-8.log 要生成的时候,删除 rolling-1.log。可以调整 Demo 中的日志输出量来进行验证。
3)SizeBasedTriggeringPolicy,基于日志文件大小的时间策略,大小以字节为单位,后缀可以是 KB,MB 或 GB,例如 20 MB。
再来看一个日志文件压缩的示例,来看配置:
- fileName 的属性值中包含了一个目录 gz,也就是说日志文件都将放在这个目录下。
- filePattern 的属性值中增加了一个 gz 的后缀,这就表明日志文件要进行压缩了,还可以是 zip 格式。
运行 Demo 后,可以在 gz 目录下看到以下文件:

到此为止,Log4j 2 的基本使用示例就已经完成了。测试环境搞定,我去问一下老板,要不要在生产环境下使用 Log4j 2。
就在昨天,老板听我说完 Logback 有多牛逼之后,彻底动心了,对我下了死命令,“这么好的日志系统,你还不赶紧点,把它切换到咱的项目当中!”
我们项目之前用的 Log4j,在我看来,已经足够用了,毕竟是小公司,性能上的要求没那么苛刻。

Log4j 介绍过了,SLF4J 也介绍过了,那接下来,你懂的,Logback 就要隆重地登场了,毕竟它哥仨有一个爹,那就是巨佬 Ceki Gulcu。
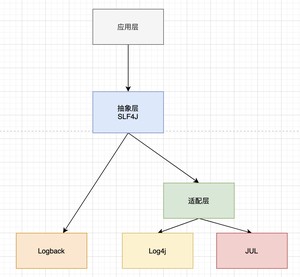
1)非常自然地实现了 SLF4J,不需要像 Log4j 和 JUL 那样加一个适配层。
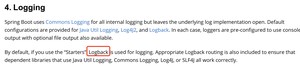
2)Spring Boot 的默认日志框架使用的是 Logback。一旦某款工具库成为了默认选项,那就说明这款工具已经超过了其他竞品。

注意看下图(证据找到了,来自 Spring Boot 官网):
也可以通过源码的形式看得到:
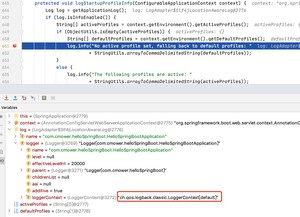
3)支持自动重新加载配置文件,不需要另外创建扫描线程来监视。
4)既然是巨佬的新作,那必然在性能上有了很大的提升,不然呢?
第一步,在 pom.xml 文件中添加 Logback 的依赖:
Maven 会自动导入另外两个依赖:

logback-core 是 Logback 的核心,logback-classic 是 SLF4J 的实现。
第二步,来个最简单的测试用例:
Logger 和 LoggerFactory 都来自 SLF4J,所以如果项目是从 Log4j + SLF4J 切换到 Logback 的话,此时的代码是零改动的。
运行 Test 类,可以在控制台看到以下信息:
在没有配置文件的情况下,一切都是默认的,Logback 的日志信息会输出到控制台。可以通过 StatusPrinter 来打印 Logback 的内部信息:
在 main 方法中添加以上代码后,再次运行 Test 类,可以在控制台看到以下信息:
也就是说,Logback 会在 classpath 路径下先寻找 logback-test.xml 文件,没有找到的话,寻找 logback.groovy 文件,还没有的话,寻找 logback.xml 文件,都找不到的话,就输出到控制台。
一般来说,我们会在本地环境中配置 logback-test.xml,在生产环境下配置 logback.xml。
第三步,在 resource 目录下增加 logback-test.xml 文件,内容如下所示:
Logback 的配置文件非常灵活,最基本的结构为 元素,包含 0 或多个 元素,其后跟 0 或多个 元素,其后再跟最多只能存在一个的 元素。
1)配置 appender,也就是配置日志的输出目的地,通过 name 属性指定名字,通过 class 属性指定目的地:
- ch.qos.logback.core.ConsoleAppender:输出到控制台。
- ch.qos.logback.core.FileAppender:输出到文件。
- ch.qos.logback.core.rolling.RollingFileAppender:文件大小超过阈值时产生一个新文件。
除了输出到本地,还可以通过 SocketAppender 和 SSLSocketAppender 输出到远程设备,通过 SMTPAppender 输出到邮件。甚至可以通过 DBAppender 输出到数据库中。
encoder 负责把日志信息转换成字节数组,并且把字节数组写到输出流。
pattern 用来指定日志的输出格式:
- :输出的时间格式。
- :日志的线程名。
- :日志的输出级别,填充到 5 个字符。比如说 info 只有 4 个字符,就填充一个空格,这样日志信息就对齐了。
反例(没有指定 -5 的情况):

- :logger 的名称,length 用来缩短名称。没有指定表示完整输出;0 表示只输出 logger 最右边点号之后的字符串;其他数字表示输出小数点最后边点号之前的字符数量。
- :日志的具体信息。
- :换行符。
- :输出从程序启动到创建日志记录的时间,单位为毫秒。
2)配置 root,它只支持一个属性——level,值可以为:TRACE、DEBUG、INFO、WARN、ERROR、ALL、OFF。
appender-ref 用来指定具体的 appender。
3)查看内部状态信息。
可以在代码中通过 StatusPrinter 来打印 Logback 内部状态信息,也可以通过在 configuration 上开启 debug 来打印内部状态信息。
重新运行 Test 类,可以在控制台看到以下信息:
4)自动重载配置。
之前提到 Logback 很强的一个功能就是支持自动重载配置,那想要启用这个功能也非常简单,只需要在 configuration 元素上添加 即可。
默认情况下,扫描的时间间隔是一分钟一次。如果想要调整时间间隔,可以通过 scanPeriod 属性进行调整,单位可以是毫秒(milliseconds)、秒(seconds)、分钟(minutes)或者小时(hours)。
下面这个示例指定的时间间隔是 30 秒:
注意:如果指定了时间间隔,没有指定时间单位,默认的时间单位为毫秒。
当设置 后,Logback 会起一个 ReconfigureOnChangeTask 的任务来监视配置文件的变化。
如果你的项目以前用的 Log4j,那么可以通过下面这个网址把 log4j.properties 转成 logback-test.xml:
http://logback.qos.ch/translator/
把之前 log4j.properties 的内容拷贝一份:
粘贴到该网址的文本域:

点击「Translate」,可以得到以下内容:
可以确认一下内容,发现三个 appender 都在。

但是呢,转换后的文件并不能直接使用,需要稍微做一些调整,因为:
第一,日志的格式化有细微的不同,Logback 中没有 。
第二,RollingFileAppender 需要指定 RollingPolicy 和 TriggeringPolicy,前者负责日志的滚动功能,后者负责日志滚动的时机。如果 RollingPolicy 也实现了 TriggeringPolicy 接口,那么只需要设置 RollingPolicy 就好了。
TimeBasedRollingPolicy 和 SizeAndTimeBasedRollingPolicy 是两种最常用的滚动策略。
TimeBasedRollingPolicy 同时实现了 RollingPolicy 与 TriggeringPolicy 接口,因此使用 TimeBasedRollingPolicy 的时候就可以不指定 TriggeringPolicy。
TimeBasedRollingPolicy 可以指定以下属性:
- fileNamePattern,用来定义文件的名字(必选项)。它的值应该由文件名加上一个 的占位符。 应该包含 中规定的日期格式,缺省是 。滚动周期是通过 fileNamePattern 推断出来的。
- maxHistory,最多保留多少数量的日志文件(可选项),将会通过异步的方式删除旧的文件。比如,你指定按月滚动,指定 ,那么 6 个月内的日志文件将会保留,超过 6 个月的将会被删除。
- totalSizeCap,所有日志文件的大小(可选项)。超出这个大小时,旧的日志文件将会被异步删除。需要配合 maxHistory 属性一起使用,并且是第二条件。
来看下面这个 RollingFileAppender 配置:
基于按天滚动的文件策略,最多保留 30 天,最大大小为 30G。
SizeAndTimeBasedRollingPolicy 比 TimeBasedRollingPolicy 多了一个日志文件大小设定的属性:maxFileSize,其他完全一样。
基于我们对 RollingPolicy 的了解,可以把 logback-test.xml 的内容调整为以下内容:
修改 Test 类的内容:
运行后,可以在 target 目录下看到两个文件:debug.log 和 errror.log。

到此为止,项目已经从 Log4j 切换到 Logback 了,过程非常的丝滑顺畅,嘿嘿。
Logback 的官网上是有一份手册的,非常详细,足足 200 多页,只不过是英文版的。小伙伴们可以看完我这篇文章入门实操的 Logback 教程后,到下面的地址看官方手册。
http://logback.qos.ch/manual/index.html
如果英文阅读能力有限的话,可以到 GitHub 上查看雷锋翻译的中文版:
https://github.com/itwanger/logback-chinese-manual
当然了,还有一部分小伙伴喜欢看离线版的 PDF,我已经整理好了:
链接:https://pan.baidu.com/s/16FrbwycYUUIfKknlLhRKYA 密码:bptl
我在读嵩山版的阿里巴巴开发手册(没有的小伙伴,记着找我要)的时候,就发现了一条「强制」性质的日志规约:
应用中不可以直接使用日志系统(Log4j、Logback)中的 API,而应该使用日志框架中的 API,比如说 SLF4J,使用门面模式的日志框架,有利于维护和统一各个类的日志处理方式。
(为什么我把这段文字手敲了下来呢,因为我发现阿里巴巴开发手册上的有语病,瞧下面红色标出的部分)
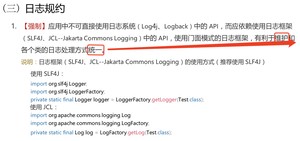
(维护和统一,把统一放在最后面读起来真的是别扭,和的有点牵强,请问手册的小编是数学老师教的语文吧?)

那看到这条强制性的规约,我就忍不住想要问:“为什么阿里巴巴开发手册会强制使用 SLF4J 作为 Log4J 的门面担当呢?”究竟这背后藏了什么“不可告人”的秘密?
(请小伙伴们自行配上 CCTV 12 台的那种 BGM)
PS:顺带给小伙伴们普及一点小知识,阿里巴巴开发手册上出现的 Jakarta 其实是 Apache 软件基金会下的一个开源项目。其实 Commons 是以前隶属于 Jakarta,现在是作为 Apache 下的一个单独项目,阿里巴巴开发手册上的描述已经不太恰当了,换成是 Apache Commons Logging 会更合适一点。
(忍不住又给阿里巴巴开发手册挑了一个毛病,请原谅我“一丝不苟”的做事态度)
SLF4J 是 Simple Logging Facade for Java 的缩写(for≈4),也就是简易的日志门面,以外观模式(Facade pattern,一种设计模式,为子系统中的一组接口提供一个统一的高层接口,使得子系统更容易使用)实现,支持 java.util.logging、Log4J 和 Logback。
SLF4J 的作者就是 Log4J 和 Logback 的作者,他的 GitHub 主页长下面这样:
一股秋风瑟瑟的清冷感扑面而来,有没有?可能巨佬不屑于维护他的 GitHub 主页吧?我的 GitHub 主页够凄惨了,没想到巨佬比我还惨,终于可以吹牛逼地说,“我,沉默王二,GitHub 主页比 SLF4J、Log4J 和 Logback 的作者 Ceki Gulcu 绿多了。。。。。。”
1996 年初,欧洲安全电子市场项目决定编写自己的跟踪 API,最后该 API 演变成了 Log4j,已经推出就备受宠爱。
2002 年 2 月,Sun 推出了自己的日志包 java.util.logging(可称 JUL),据说实现思想借鉴了 Log4j,毕竟此时的 Log4j 已经很成熟了。
2002 年 8 月,Apache 就推出了自己的日志包,也就是阿里巴巴开发手册上提到的 JCL(Jakarta Commons Logging)。JCL 的野心很大,它在 JUL 和 Log4j 的基础上提供了一个抽象层的接口,方便使用者在 JUL 和 Log4j 之间切换。
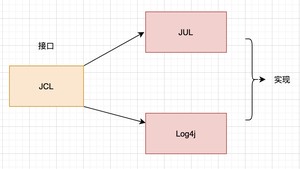
但 JCL 好像并不怎么招人喜欢,有人是这样抱怨的:

Ceki Gulcu 也觉得 JCL 不好,要不然他也不会在 2005 年自己撸一个名叫 SLF4J 的新项目,对吧?但出来混总是要付出代价的,SLF4J 只有接口,没有实现,总不能强逼着 Java 和 Apache 去实现 SLF4J 接口吧?这太难了,不现实。
但巨佬之所以称之为巨佬,是因为他拥有超出普通人的惊人之处,他在 SLF4J 和 JUL、Log4j、JCL 之间搭了三座桥:
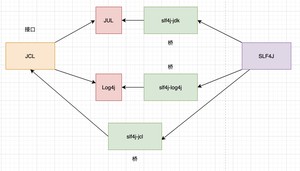
巨佬动手,丰衣足食,有没有?狠起来连自己的 Log4j 都搭个桥。
面对巨佬的霸气,我只想弱弱地说一句,“ SLF4J 这个门面担当,你以为好当的啊?”
春秋战国的时候,每个国家都有自己的货币,用别国的货币也不合适,对吧?那在发生贸易的时候就比较麻烦了,货币不统一,就没法直接交易,因为货币可能不等价。
那秦始皇统一六国后,就推出了新的货币政策,全国都用一种货币,那之前的问题就解决掉了。
你看,同样的道理,日志系统有 JUL、JCL,Ceki Gulcu 自己又写了 2 种,Log4j 和 Logback,各有各的优缺点,再加上使用者千千万,萝卜白菜各有所爱,这就导致不同的应用可能会用不同的日志系统。
假设我们正在开发一套系统,打算用 SLF4J 作为门面,Log4j 作为日志系统,我们在项目中使用了 A 框架,而 A 框架的门面是 JCL,日志系统是 JUL,那就相等于要维护两套日志系统,对吧?
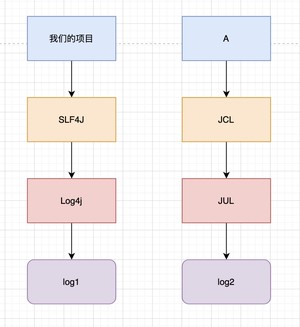
这就难受了!
Ceki Gulcu 想到了这个问题,并且帮我们解决了!来看 SLF4J 官网给出的解决方案。
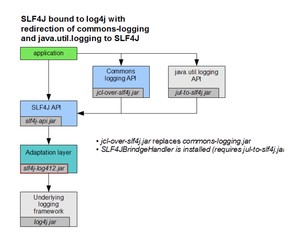
- 使用 jcl-over-slf4j.jar 替换 commons-logging.jar
- 引入 jul-to-slf4j.jar
为了模拟这个过程,我们来建一个使用 JCL 的项目。
第一步,在 pom.xml 文件中引入 commons-logging.jar:
第二步,新建测试类:
该类会通过 LogFactory 获取一个 Log 对象,并且使用 方法打印一行日志。
调试这段代码的过程中你会发现,Log 的实现有四种:
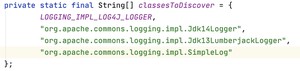
如果没有绑定 Log4j 的话,就会默认选择 Jdk14Logger——它返回的 Logger 对象,正是 java.util.logging.Logger,也就是 JUL。
因此,就可以在控制台看到以下信息:
怎么把使用 JCL 的项目改造成使用 SLF4J 的呢?
第三步,使用 jcl-over-slf4j.jar 替换 commons-logging.jar,并加入 jul-to-slf4j.jar、slf4j-log4j12.jar(会自动引入 slf4j-api.jar 和 log4j.jar):
第四步,在 resources 目录下创建 log4j.properties 文件,内容如下所示:
再次运行 Demo 类,你会发现 target 目录下会生成一个名叫 debug.log 的文件,内容如下所示:
并且可以在控制台看到以下信息:
仔细对比一下,你就会发现,这次输出的格式和之前不一样,这就是因为 Log4j 和 JUL 的日志格式不同导致的。
另外,你有没有发现?我们并没有改动测试类 Demo,它里面使用的仍然是 JCL 获取 Log 的方式:
但输出的格式已经切换到 Log4j 了!
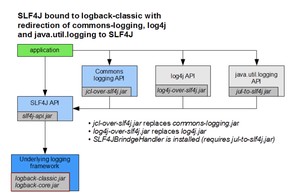
SLF4J 除了提供这种解决方案,绑定 Log4j 替换 JUL 和 JCL;还提供了绑定 Logback 替换 JUL、JCL、Log4j 的方案:
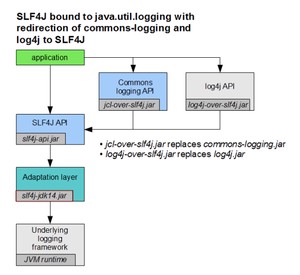
还有绑定 JUL 替换 JCL 和 Log4j 的方案:
太强了,有木有?有的话请在留言区敲出 666。

SLF4J 除了解决掉以上的痛点,帮助我们的应用程序独立于任何特定的日志系统,还有一个非常牛逼的功能,那就是 SLF4J 在打印日志的时候使用了占位符 ,它有点类似于 String 类的 方法(使用 等填充参数),但更加便捷,这在很大程度上提高了程序的性能。
众所周知,字符串是不可变的,字符串拼接会创建很多不必要的字符串对象,极大的消耗了内存空间。但 Log4J 在打印带参数的日志时,只能使用字符串拼接的方式:
非常笨重,但加入了 SLF4J 后,这个问题迎刃而解。我们来看一下在 Log4j 项目中加入 SLF4J 的详细的步骤。
第一步,把 log4j 的依赖替换为 slf4j-log4j12(Maven 会自动引入 slf4j-api.jar 和 log4j.jar):
第二步,在 resources 目录下创建 log4j.properties 文件,内容和 Log4j 那一篇完全相同:
第三步,新建测试类:
看到了吧,使用占位符要比“+”操作符方便的多。并且此时不再需要 先进行判断, 方法会在字符串拼接之前执行。

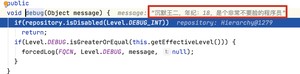
如果只是 Log4J 的话,会先进行字符串拼接,再执行 方法,来看示例代码:
在调试这段代码的时候,你会发现的,如下图所示:
这也就意味着,如果日志系统的级别不是 DEBUG,就会多执行了字符串拼接的操作,白白浪费了性能。
注意,阿里巴巴开发手册上还有一条「强制」级别的规约:

这是因为如果参数是基本数据类型的话,会先进行自动装箱()。测试代码如下所示:
通过反编译工具就可以看得到:
如果参数需要调用其他方法的话, 方法会随后调用。
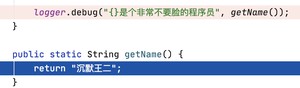
也就是说,如果不 的话,在不是 DEBUG 级别的情况下,会多执行自动装箱和调用其他方法的操作——程序的性能就下降了!
测试类运行的结果和之前 Log4J 的一样,小伙伴们可以点击链接跳转到 Log4j 那篇对比下。
简单总结一下这篇文章哈。
1)在使用日志系统的时候,一定要使用 SLF4J 作为门面担当。
2)SLF4J 可以统一日志系统,作为上层的抽象接口,不需要关注底层的日志实现,可以是 Log4j,也可以是 Logback,或者 JUL、JCL。
3)SLF4J 在打印日志的时候可以使用占位符,既提高了程序性能(临时字符串少了,垃圾回收的工作量就小),又让代码变得美观统一。
4)小伙伴们如果知道更多秘密的话,建议在留言区贴出来哦。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/6875.html