
概要
跳表(Skip List)是一种基于的数据结构,通过增加多级索引来加速查找、插入和删除操作。它可以看作是链表与二分查找的结合体,能够在保持数据有序的同时,实现快速的查找,时间复杂度与平衡树(如红黑树)相同,但实现上更为简单。(跳表又称为:)
跳表结构:
跳表的结构
跳表通过构建来提高查找效率。最底层的链表是一个完全有序的链表,包含所有的元素。随着层级升高,每一层链表都会跳过一些元素,从而使查找路径变短。通过这种分层的方式,可以在保持数据有序的同时,实现类似于平衡树的快速查找性能。
- 最底层链表:包含所有元素,按升序排列。所有的搜索最终都会回到这一层,保证能够找到元素。
- 上层索引:每一层的节点是下一层节点的一个子集,用于跳跃式查找。每层链表都按一定概率选取前一层的节点,形成多个层级。
跳表的典型结构如下图所示:
- 最底层 Level 1 包含所有元素。
- 上层的每一层是下一层的子集,用于跳跃式查找,加快定位。()
跳表的查找过程
跳表的查找类似于二分查找的思想,通过从上到下、从左到右逐步缩小范围,找到目标元素。
查找步骤:
- 从最高层(第一个非空层级)的头节点开始,向右移动,直到当前节点的右边节点大于目标值或右边没有节点。
- 如果右边节点大于目标值或者没有右节点,下降到下一层,继续从当前节点向右查找。
- 重复步骤 1 和 2,直到降到最底层。
- 在最底层找到目标元素,返回结果;如果不存在则返回 。
例如,查找值 的过程:
- 从 第3层 开始, 之后,右边的 比 大,往下到 Level 2。
- 在 第2层,,右边的 比 大,继续往下到 Level 1。
- 在 第1层,从 ,找到了目标元素 。
插入操作
插入操作同样从最上层开始,但每当插入一个新节点时,还需要决定是否将该节点插入到更高层级中(即是否创建该节点的索引)。跳表通过随机化策略来决定节点是否在更高层级出现。
插入步骤:
- 按照查找操作,从最高层开始找到插入位置,在最底层找到插入点。
- 插入元素到最底层的链表中。
- 通过随机选择决定是否将节点插入到更高层级,如果是,则在更高层中插入相应的节点索引。
- 重复步骤 3,直到随机选择决定不再向上插入或达到跳表的最高层。
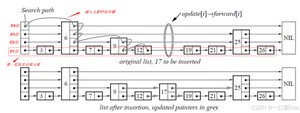
例如,插入 的过程:
- 在 Level 1 找到 和 之间的位置,插入 。
- 随机选择决定 也出现在 Level 2 中,于是在 Level 2 的 和 之间插入 。
- 再次随机决定 不会出现在更高层级,插入结束。
删除操作
删除操作与查找操作类似,从最高层开始查找需要删除的元素,找到元素后,在每一层级的链表中删除该元素的索引。
删除步骤:
- 从最高层开始,逐步向下查找目标元素。
- 一旦找到目标元素,在所有包含该元素的层级中删除该元素的节点。
- 当删除完所有层级中的节点后,跳表结构自动调整。
补充
的有序集合(Sorted Set)就是用跳表实现的,它能够高效支持插入、删除、查找、范围查询等操作。
- 复杂度和性能:B+ 树的时间复杂度是 O(log n),但是其底层结构需要维护多个层次的节点分裂、合并等复杂操作,特别是在插入和删除时,涉及平衡和重构,带来较高的性能成本。而 跳表(SkipList) 的时间复杂度同样是 O(log n),但其结构更简单,动态操作(如插入、删除、更新)的实现也更加直接,符合 Redis 追求简洁高效的设计理念。
- 基于内存的设计:Redis 是一个基于内存的数据库,不需要频繁访问磁盘,因此无需像 B+ 树那样专门为磁盘 I/O 优化。在内存环境下,跳表能够提供足够的性能,且其实现简单,内存占用也较为合理。
❤觉得有用的可以留个关注ya❤
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/14060.html