
交叉验证是在机器学习建立模型和验证模型参数时常用的办法,一般被用于评估一个机器学习模型的表现。更多的情况下,我们也用交叉验证来进行模型选择(model selection)。
交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓“交叉”。
那么什么时候才需要交叉验证呢?交叉验证用在数据不是很充足的时候。如果数据样本量小于一万条,我们就会采用交叉验证来训练优化选择模型。如果样本大于一万条的话,我们一般随机的把数据分成三份,一份为训练集(Training Set),一份为验证集(Validation Set),最后一份为测试集(Test Set)。用训练集来训练模型,用验证集来评估模型预测的好坏和选择模型及其对应的参数。把最终得到的模型再用于测试集,最终决定使用哪个模型以及对应参数。
回到交叉验证,根据切分的方法不同,交叉验证分为下面三种:
第一种是简单交叉验证,所谓的简单,是和其他交叉验证方法相对而言的。首先,我们随机的将样本数据分为两部分(比如: 70%的训练集,30%的测试集),然后用训练集来训练模型,在测试集上验证模型及参数。接着,我们再把样本打乱,重新选择训练集和测试集,继续训练数据和检验模型。最后我们选择损失函数评估最优的模型和参数。
第二种是 S折交叉验证( S-Folder Cross Validation),也是经常会用到的。和第一种方法不同, S折交叉验证先将数据集 D随机划分为 S个大小相同的互斥子集,即 ,每次随机的选择 S-1份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择 S份来训练数据。若干轮(小于 S )之后,选择损失函数评估最优的模型和参数。注意,交叉验证法评估结果的稳定性和保真性在很大程度上取决于 S取值。
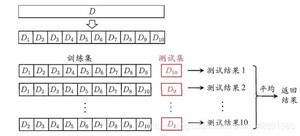
图来自:周志华《机器学习》
第三种是留一交叉验证(Leave-one-out Cross Validation),它是第二种情况的特例,此时 S等于样本数 N,这样对于 N个样本,每次选择 N-1个样本来训练数据,留一个样本来验证模型预测的好坏。此方法主要用于样本量非常少的情况,比如对于普通适中问题, N小于50时,我一般采用留一交叉验证。
通过反复的交叉验证,用损失函数来度量得到的模型的好坏,最终我们可以得到一个较好的模型。那这三种情况,到底我们应该选择哪一种方法呢?一句话总结,如果我们只是对数据做一个初步的模型建立,不是要做深入分析的话,简单交叉验证就可以了。否则就用S折交叉验证。在样本量少的时候,使用S折交叉验证的特例留一交叉验证。
此外还有一种比较特殊的交叉验证方式,也是用于样本量少的时候。叫做自助法(bootstrapping)。比如我们有m个样本(m较小),每次在这m个样本中随机采集一个样本,放入训练集,采样完后把样本放回。这样重复采集m次,我们得到m个样本组成的训练集。当然,这m个样本中很有可能有重复的样本数据。同时,用原始的m个样本做测试集。这样接着进行交叉验证。由于我们的训练集有重复数据,这会改变数据的分布,因而训练结果会有估计偏差,因此,此种方法不是很常用,除非数据量真的很少,比如小于20个。
1、保留交叉验证 hand-out cross validation
首先随机地将已给数据分为两部分:训练集和测试集 (例如,70% 训练集,30% 测试集);
然后用训练集在各种条件下 (比如,不同的参数个数) 训练模型,从而得到不同的模型;
在测试集上评价各个模型的测试误差,选出测试误差最小的模型。
这种方式其实严格意义上并不能算是交叉验证,因为训练集的样本数始终是那么多,模型并没有看到更多的样本,没有体现交叉的思想。
由于是随机的将原始数据分组,所以最后测试集上准确率的高低与原始数据的分组有很大的关系,所以这种方法得到的结果其实并不具有说服性。
2、k折交叉验证 k-fold cross validation
这是应用最多的交叉验证方式。
首先随机地将数据集切分为 k 个互不相交的大小相同的子集;
然后将 k-1 个子集当成训练集训练模型,剩下的 (held out) 一个子集当测试集测试模型;
将上一步对可能的 k 种选择重复进行 (每次挑一个不同的子集做测试集);
这样就训练了 k 个模型,每个模型都在相应的测试集上计算测试误差,得到了 k 个测试误差,对这 k 次的测试误差取平均便得到一个交叉验证误差。这便是交叉验证的过程。
计算平均测试误差 (交叉验证误差) 来评估当前参数下的模型性能。
在模型选择时,假设模型有许多 tuning parameter 可供调参,一组 tuning parameter 便确定一个模型,计算其交叉验证误差,最后选择使得交叉验证误差最小的那一组 tuning parameter。这便是模型选择过程。
k 一般大于等于2,实际操作时一般从3开始取,只有在原始数据集样本数量小的时候才会尝试取2。
k折交叉验证可以有效的避免过拟合以及欠拟合状态的发生,最后得到的结果也比较具有说服性。
k折交叉验证最大的优点:
• 所有数据都会参与到训练和预测中,有效避免过拟合,充分体现了交叉的思想
交叉验证可能存在 bias 或者 variance。如果我们提高切分的数量 k,variance 会上升但 bias 可能会下降。相反得,如果降低 k,bias 可能会上升但 variance 会下降。bias-variance tradeoff 是一个有趣的问题,我们希望模型的 bias 和 variance 都很低,但有时候做不到,只好权衡利弊,选取他们二者的平衡点。
通常使用10折交叉验证,当然这也取决于训练数据的样本数量。
3、留一交叉验证 leave-one-out cross validation
k折交叉验证的特殊情况,k=N,N 是数据集的样本数量,往往在数据缺乏的情况下使用。
留一交叉验证的优点是:
缺点是:
• 计算成本高,因为需要建立的模型数量和原始数据集样本数量一致,尤其当样本数量很大的时候。可以考虑并行化训练模型减少训练时间。
总之,交叉验证对于我们选择模型以及模型的参数都是很有帮助的。
但以上交叉验证的方法都有一个问题,就是在数据分组的时候缺乏随机性,以 k折交叉验证 为例,每个数据样本只能固定属于 k 个子集中的一个,可能会造成对于最终结果的影响。于是有人提出了 bootstrapping。
cv 和 bootstrapping 都是重采样 (resampling) 的方法。机器学习中常用的 bagging 和 boosting 都是 bootstrapping 思想的应用。
bootstrapping 的思想是依靠自己的资源,称为自助法,它是一种有放回的抽样方法。
bootstrapping 的过程如下:
- 数据假设要分成10组,则先设置一个采样比例,比如采样比例70%。则10组数据是每次从原始数据集中随机采样总数70%的数据构成训练集1,没有选中的样本作为测试集1;然后把数据放回,再随机采样总数70%的数据构成训练集2,没选中的作为测试集2……以此类推,放回式采样10组。
- 训练生成10个模型
- 计算平均测试误差来评估当前参数下的模型性能
除此之外,bootstrapping 在集成学习方法中也很有用。比如我们可以用经过 bootstrapping 的多组数据集构建模型 (比如决策树),然后将这些模型打包 (bag,就像随机森林),最后使用这些模型的最大投票结果作为我们最终的输出。
交叉验证可以有效评估模型的质量
交叉验证可以有效选择在数据集上表现最好的模型
交叉验证可以有效避免过拟合和欠拟合
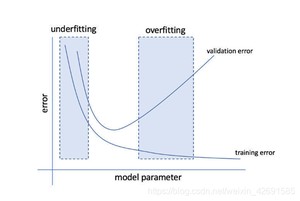
• 欠拟合(Underfitting)
是指模型不能获取数据集的主要信息,在训练集及测试集上的表示都十分糟糕。
• 过拟合(Overfitting)
是指模型不仅获取了数据集的信息还提取了噪声数据的信息是的模型在训练集有非常好的表现但在测试集上的表现及其糟糕。
所以可以得出一个较为草率的结论:一个最佳的ML模型在训练集和测试集上都有较好的表现。
通常,基于数据的具体划分方式有多种交叉验证方法。
在Python中使用:xtrain,xtest,ytrain,ytest = sklearn.model_selection.train_test_split()实现
Args:
data要进行划分的数据集,支持列表、数据帧、数组、矩阵
test_size 测试集所占比例,默认为0.25
train_size训练集所占比例
random_state随机数种子,用于生成重复随机数,保证实验可复现
shuffle 是否在划分数据集之前打乱数据集
使用sklearn库实现交叉验证
最后输出结果
有了交叉验证,通过指定不同的模型参数 (上面的 knn 的参数就是 n_neighbors),计算平均测试误差 (当然评估指标是根据问题的类型而定,acc 用于分类模型,mse 用于回归模型),指标最好的模型对应的参数就是我们要选择的模型参数。
对于一些复杂的自定义的模型,数据集的读取并不是 sklearn 风格的,比如我最近写的一个层次分类模型,每一个层中每一个分类器的数据读取都是要到特征配置文件中找到对应的特征组再去数据集中读出来,这样很难使用 sklearn 的接口,于是我自己写了一个切分数据集的函数,来进行交叉验证。
k 折切分数据集后,在包含 k 个 (训练集,测试集) 组的列表中逐一训练、测试模型,得到 k 个模型,最后计算这些模型的平均测试误差,这样就完成了一次交叉验证。
1.模型选择之交叉验证
2.交叉验证
3.交叉验证
4. 交叉验证的原理及实现
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/13767.html