
iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 /proc/diskstats。
rhel6
rrqm/s:每秒这个设备相关的读取请求有多少被merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同BLock的数据,FS会将这个请求合并merge)
wrqm/s:每秒这个设备相关的写入请求有多少被merge了。每秒进行merge写操作数据,即delta(wmerge)/s
r/s:每秒完成的读I/O设备次数。即delta(rio)/s
w/s:每秒完成的写I/O设备次数。即delta(wio)/s
rsec/s:每秒读扇区数。即delta(rsect)/s
wsec/s:每秒写扇区数。即delta(wsect)/s
rMB/s:每秒读M(K)字节数。是rsect/s的一半,因为每个扇区大小为512字节。(需要计算)
wMB/s:每秒写M(K)字节数。是wsect/s的一半(需要计算)
avgrq-sz:平均每次设备I/O操作的数据大小(扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz:平均I/O队列长度。即delta(aveq)/s/1000 。(因为aveq的单位为毫秒)
await:每一个IO请求的处理的平均时间(Linux上单位为毫秒)。这里可以理解为IO的响应时间,一般的系统IO响应时间应该低于5ms,如果大于10ms就比较大了。这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,他们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
svctm:端到端的IO请求平均服务时间,表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于avctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。
Կ#xff1a;一秒中多百分之多少的时间用于I/O操作,或者说一秒中有多少时间I/O队列是非空的。即delta(use)/s/1000(因为use的单位为毫秒)。如果梾近100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈,idle小于70%压力就较大了。一般读取速度有较多的wait。
iostat中IO平均响应时间await,平均服务响应时长svctm,svctm一般在5ms左右,svctm大一般是存储的问题,否则是主机的问题。如果await远大于svctm,优先怀疑主机业务异常或链路端口达到上限,如果awati和svctm差不多大,优先怀疑存储性能能力不够。
rhel7
kB_read/s:每秒从设备(drive expressed)读取的数据量
kB_wrtn/s:每秒从设备(drive expressed)写入的数据量
kB_read:读取的总数据量
kB_wrtn:写入的总数据量;这些单位都是Kilobytes,即KB
查看具体进程的IO消耗情况:pidstat
用户 ID(UID)和进程 ID(PID) 。
每秒读取的数据大小(kB_rd/s) ,单位是 KB。
每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
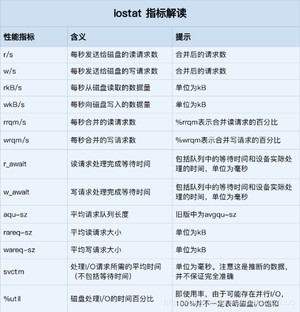
这些指标中,你要注意:Թ,就是我们前面提到的磁盘 I/O 使用率;r/s+ w/s ,就是 IOPS;rkB/s+wkB/s ,就是吞吐量;r_await+w_await ,就是响应时间。在观测指标时,也别忘了结合请求的大小( rareq-sz 和 wareq-sz)一起分析。你可能注意到,从 iostat 并不能直接得到磁盘饱和度。事实上,饱和度通常也没有其他简单的观测方法,不过,你可以把观测到的,平均请求队列长度或者读写请求完成的等待时间,跟基准测试的结果(比如通过 fio)进行对比,综合评估磁盘的饱和情况。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/13245.html