
下面有请王老师上台,来给大家讲一讲 TreeMap,鼓掌了!
之前 LinkedHashMap 那篇文章里提到过了,HashMap 是无序的,所以有了 LinkedHashMap,加上了双向链表后,就可以保持元素的插入顺序和访问顺序,那 TreeMap 呢?
TreeMap 由红黑树实现,可以保持元素的自然顺序,或者实现了 Comparator 接口的自定义顺序。
可能有些同学不了解红黑树,我这里来普及一下:
红黑树(英语:Red–black tree)是一种自平衡的二叉查找树(Binary Search Tree),结构复杂,但却有着良好的性能,完成查找、插入和删除的时间复杂度均为 log(n)。
二叉查找树是一种常见的树形结构,它的每个节点都包含一个键值对。每个节点的左子树节点的键值小于该节点的键值,右子树节点的键值大于该节点的键值,这个特性使得二叉查找树非常适合进行数据的查找和排序操作。
下面是一个简单的手绘图,展示了一个二叉查找树的结构:
在上面这个二叉查找树中,根节点是 8,左子树节点包括 3、1、6、4 和 7,右子树节点包括 10、14 和 13。
- 3<8<10
- 1<3<6
- 4<6<7
- 10<14
- 13<14
这是一颗典型的二叉查找树:
- 1)左子树上所有节点的值均小于或等于它的根结点的值。
- 2)右子树上所有节点的值均大于或等于它的根结点的值。
- 3)左、右子树也分别为二叉查找树。
二叉查找树用来查找非常方面,从根节点开始遍历,如果当前节点的键值等于要查找的键值,则查找成功;如果要查找的键值小于当前节点的键值,则继续遍历左子树;如果要查找的键值大于当前节点的键值,则继续遍历右子树。如果遍历到叶子节点仍然没有找到,则查找失败。
插入操作也非常简单,从根节点开始遍历,如果要插入的键值小于当前节点的键值,则将其插入到左子树中;如果要插入的键值大于当前节点的键值,则将其插入到右子树中。如果要插入的键值已经存在于树中,则更新该节点的值。
删除操作稍微复杂一些,需要考虑多种情况,包括要删除的节点是叶子节点、要删除的节点只有一个子节点、要删除的节点有两个子节点等等。
总之,二叉查找树是一种非常常用的数据结构,它可以帮助我们实现数据的查找、排序和删除等操作。
理解二叉查找树了吧?
不过,二叉查找树有一个明显的不足,就是容易变成瘸子,就是一侧多,一侧少,比如说这样:
在上面这个不平衡的二叉查找树中,左子树比右子树高。根节点是 6,左子树节点包括 4、3 和 1,右子树节点包括 8、7 和 9。
由于左子树比右子树高,这个不平衡的二叉查找树可能会导致查找、插入和删除操作的效率下降。
来一个更极端的情况。
在上面这个极度不平衡的二叉查找树中,所有节点都只有一个右子节点,根节点是 1,右子树节点包括 2、3、4、5 和 6。
这种极度不平衡的二叉查找树会导致查找、插入和删除操作的效率急剧下降,因为每次操作都只能在右子树中进行,而左子树几乎没有被利用到。
查找的效率就要从 log(n) 变成 o(n) 了(戳这里了解时间复杂度),对吧?
必须要平衡一下,对吧?于是就有了平衡二叉树,左右两个子树的高度差的绝对值不超过 1,就像下图这样:
根节点是 8,左子树节点包括 4、2、6、5 和 7,右子树节点包括 12、10、14、13 和 15。左子树和右子树的高度差不超过1,因此它是一个平衡二叉查找树。
平衡二叉树就像是一棵树形秤,它的左右两边的重量要尽可能的平衡。当我们往平衡二叉树中插入一个节点时,平衡二叉树会自动调整节点的位置,以保证树的左右两边的高度差不超过1。类似地,当我们删除一个节点时,平衡二叉树也会自动调整节点的位置,以保证树的左右两边的高度差不超过1。
常见的平衡二叉树包括AVL树、红黑树等等,它们都是通过旋转操作来调整树的平衡,使得左子树和右子树的高度尽可能接近。
AVL树的示意图:
AVL树是一种高度平衡的二叉查找树,它要求左子树和右子树的高度差不超过1。由于AVL树的平衡度比较高,因此在进行插入和删除操作时需要进行更多的旋转操作来保持平衡,但是在查找操作时效率较高。AVL树适用于读操作比较多的场景。
例如,对于一个需要频繁进行查找操作的场景,如字典树、哈希表等数据结构,可以使用AVL树来进行优化。另外,AVL树也适用于需要保证数据有序性的场景,如数据库中的索引。
AVL树最初由两位苏联的计算机科学家,Adelson-Velskii和Landis,于1962年提出。因此,AVL树就以他们两人名字的首字母缩写命名了。
AVL树的发明对计算机科学的发展有着重要的影响,不仅为后来的平衡二叉树提供了基础,而且为其他领域的数据结构和算法提供了启示。
红黑树的示意图(R 即 Red「红」、B 即 Black「黑」):
红黑树,顾名思义,就是节点是红色或者黑色的平衡二叉树,它通过颜色的约束来维持二叉树的平衡,它要求任意一条路径上的黑色节点数目相同,同时还需要满足一些其他特定的条件,如红色节点的父节点必须为黑色节点等。
- 1)每个节点都只能是红色或者黑色
- 2)根节点是黑色
- 3)每个叶节点(NIL 节点,空节点)是黑色的。
- 4)如果一个节点是红色的,则它两个子节点都是黑色的。也就是说在一条路径上不能出现相邻的两个红色节点。
- 5)从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
由于红黑树的平衡度比AVL树稍低,因此在进行插入和删除操作时需要进行的旋转操作较少,但是在查找操作时效率仍然较高。红黑树适用于读写操作比较均衡的场景。
那,关于红黑树,同学们就先了解到这,脑子里有个大概的印象,知道 TreeMap 是个什么玩意。
默认情况下,TreeMap 是根据 key 的自然顺序排列的。比如说整数,就是升序,1、2、3、4、5。
输出结果如下所示:
TreeMap 是怎么做到的呢?想一探究竟,就得上源码了,来看 TreeMap 的 方法:
- 首先定义一个Entry类型的变量t,用于表示当前的根节点;
- 如果t为null,说明TreeMap为空,直接创建一个新的节点作为根节点,并将size设置为1;
- 如果t不为null,说明需要在TreeMap中查找键所对应的节点。因为TreeMap中的元素是有序的,所以可以使用二分查找的方式来查找节点;
- 如果TreeMap中使用了Comparator来进行排序,则使用Comparator进行比较,否则使用Comparable进行比较。如果查找到了相同的键,则直接更新键所对应的值;
- 如果没有查找到相同的键,则创建一个新的节点,并将其插入到TreeMap中。然后使用fixAfterInsertion()方法来修正插入节点后的平衡状态;
- 最后将TreeMap的size加1,然后返回null。如果更新了键所对应的值,则返回原先的值。
注意 这行代码,就是用来进行 key 比较的,由于此时 key 是 String,所以就会调用 String 类的 方法进行比较。
来看下面的示例。
输出结果如下所示:
从结果可以看得出,是按照字母的升序进行排序的。
如果自然顺序不满足,那就可以在声明 TreeMap 对象的时候指定排序规则。
TreeMap 提供了可以指定排序规则的构造方法:
返回的是 Collections.ReverseComparator 对象,就是用来反转顺序的,非常方便。
所以,输出结果如下所示:
HashMap 是无序的,插入的顺序随着元素的增加会不停地变动。但 TreeMap 能够至始至终按照指定的顺序排列,这对于需要自定义排序的场景,实在是太有用了!
既然 TreeMap 的元素是经过排序的,那找出最大的那个,最小的那个,或者找出所有大于或者小于某个值的键来说,就方便多了。
TreeMap 考虑得很周全,恰好就提供了 、 这样获取最后一个 key 和第一个 key 的方法。
获取的是到指定 key 之前的 key; 获取的是指定 key 之后的 key(包括指定 key)。
来看一下输出结果:
再来看一下例子:
headMap、tailMap、subMap方法分别获取了小于3、大于等于4、大于等于2且小于4的键值对。
在学习 TreeMap 之前,我们已经学习了 HashMap 和 LinkedHashMap ,那如何从它们三个中间选择呢?
需要考虑以下因素:
- 是否需要按照键的自然顺序或者自定义顺序进行排序。如果需要按照键排序,则可以使用 TreeMap;如果不需要排序,则可以使用 HashMap 或 LinkedHashMap。
- 是否需要保持插入顺序。如果需要保持插入顺序,则可以使用 LinkedHashMap;如果不需要保持插入顺序,则可以使用 TreeMap 或 HashMap。
- 是否需要高效的查找。如果需要高效的查找,则可以使用 LinkedHashMap 或 HashMap,因为它们的查找操作的时间复杂度为 O(1),而是 TreeMap 是 O(log n)。
LinkedHashMap 内部使用哈希表来存储键值对,并使用一个双向链表来维护插入顺序,但查找操作只需要在哈希表中进行,与链表无关,所以时间复杂度为 O(1)
来个表格吧,一目了然。
好了,下课,关于 TreeMap 我们就讲到这里吧,希望同学们都能对 TreeMap 有一个清晰的认识。我们下节课见~
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。

好,我们这节继续有请王老师上台来给大家讲 ArrayDeque,鼓掌欢迎了👏🏻。
Java 里有一个叫做Stack的类,却没有叫做Queue的类(它只是个接口名字,和类还不一样)。
当需要使用栈时,Java 已不推荐使用Stack,而是推荐使用更高效的ArrayDeque(双端队列),原因我们第一次讲集合框架的时候,其实已经聊过了,Stack 是一个“原始”类,它的核心方法上都加了 关键字以确保线程安全,当我们不需要线程安全(比如说单线程环境下)性能就会比较差。
也就是说,当需要使用栈时候,请首选ArrayDeque。
在上面的示例中,我们先创建了一个 ArrayDeque 对象,然后使用 push 方法向栈中添加了三个元素。接着使用 peek 方法获取栈顶元素,使用 pop 方法弹出栈顶元素,使用 pop 和 push 方法修改栈顶元素,使用迭代器查找元素在栈中的位置。
ArrayDeque 又实现了 Deque 接口(Deque 又实现了 Queue 接口):
因此,当我们需要使用队列的时候,也可以选择 ArrayDeque。
在上面的示例中,我们先创建了一个 ArrayDeque 对象,然后使用 offer 方法向队列中添加了三个元素。接着使用 peek 方法获取队首元素,使用 poll 方法弹出队首元素,使用 poll 和 offer 方法修改队列中的元素,使用迭代器查找元素在队列中的位置。
我们前面讲了,LinkedList不只是个 List,还是一个 Queue,它也实现了 Deque 接口。
所以,当我们需要使用队列时,还可以选择LinkedList。
在使用 LinkedList 作为队列时,可以使用 offer() 方法将元素添加到队列的末尾,使用 poll() 方法从队列的头部删除元素,使用迭代器或者 poll() 方法依次遍历元素。
要讲栈和队列,首先要讲Deque接口。Deque的含义是“double ended queue”,即双端队列,它既可以当作栈使用,也可以当作队列使用。下表列出了Deque与Queue相对应的接口:
下表列出了Deque与Stack对应的接口:
上面两个表共定义了Deque的 12 个接口。
添加,删除,取值都有两套接口,它们功能相同,区别是对失败情况的处理不同。
一套接口遇到失败就会抛出异常,另一套遇到失败会返回特殊值(或)。除非某种实现对容量有限制,大多数情况下,添加操作是不会失败的。
虽然Deque的接口有 12 个之多,但无非就是对容器的两端进行操作,或添加,或删除,或查看。明白了这一点讲解起来就会非常简单。
ArrayDeque和LinkedList是Deque的两个通用实现,由于官方更推荐使用ArrayDeque用作栈和队列,加之上一篇已经讲解过LinkedList,本文将着重讲解ArrayDeque的具体实现。
从名字可以看出ArrayDeque底层通过数组实现,为了满足可以同时在数组两端插入或删除元素的需求,该数组还必须是循环的,即循环数组(circular array),也就是说数组的任何一点都可能被看作起点或者终点。
ArrayDeque是非线程安全的(not thread-safe),当多个线程同时使用的时候,需要手动同步;另外,该容器不允许放入元素。
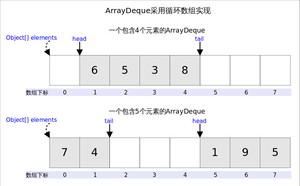
上图中我们看到,指向首端第一个有效元素,指向尾端第一个可以插入元素的空位。因为是循环数组,所以不一定总等于 0,也不一定总是比大。
的作用是在Deque的首端插入元素,也就是在的前面插入元素,在空间足够且下标没有越界的情况下,只需要将即可。

实际需要考虑:
- 空间是否够用,以及
- 下标是否越界的问题。
上图中,如果为之后接着调用,虽然空余空间还够用,但为,下标越界了。下列代码很好的解决了这两个问题。
上述代码我们看到,空间问题是在插入之后解决的,因为总是指向下一个可插入的空位,也就意味着数组至少有一个空位,所以插入元素的时候不用考虑空间问题。
下标越界的处理解决起来非常简单,就可以了,这段代码相当于取余,同时解决了为负值的情况。因为必需是的指数倍,就是二进制低位全,跟相与之后就起到了取模的作用,如果为负数(其实只可能是-1),则相当于对其取相对于的补码。
下面再说说扩容函数,其逻辑是申请一个更大的数组(原数组的两倍),然后将原数组复制过去。过程如下图所示:
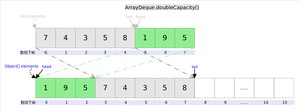
图中我们看到,复制分两次进行,第一次复制右边的元素,第二次复制左边的元素。
该方法的实现中,首先检查 head 和 tail 是否相等,如果不相等则抛出异常。然后计算出 head 右边的元素个数 r,以及新的容量 newCapacity,如果 newCapacity 太大则抛出异常。
接下来创建一个新的 Object 数组 a,将原有 ArrayDeque 中 head 右边的元素复制到 a 的前面(即图中绿色部分),将 head 左边的元素复制到 a 的后面(即图中灰色部分)。最后将 elements 数组替换为 a,head 设置为 0,tail 设置为 n(即新容量的长度)。
需要注意的是,由于 elements 数组被替换为 a 数组,因此在方法调用结束后,原有的 elements 数组将不再被引用,会被垃圾回收器回收。
的作用是在Deque的尾端插入元素,也就是在的位置插入元素,由于总是指向下一个可以插入的空位,因此只需要即可。插入完成后再检查空间,如果空间已经用光,则调用进行扩容。

下标越界处理方式中已经讲过,不再赘述。
的作用是删除并返回Deque首端元素,也即是位置处的元素。如果容器不空,只需要直接返回即可,当然还需要处理下标的问题。由于中不允许放入,当时,意味着容器为空。
的作用是删除并返回Deque尾端元素,也即是位置前面的那个元素。
的作用是返回但不删除Deque首端元素,也即是位置处的元素,直接返回即可。
的作用是返回但不删除Deque尾端元素,也即是位置前面的那个元素。
当需要实现先进先出(FIFO)或者先进后出(LIFO)的数据结构时,可以考虑使用 ArrayDeque。以下是一些使用 ArrayDeque 的场景:
- 管理任务队列:如果需要实现一个任务队列,可以使用 ArrayDeque 来存储任务元素。在队列头部添加新任务元素,从队列尾部取出任务进行处理,可以保证任务按照先进先出的顺序执行。
- 实现栈:ArrayDeque 可以作为栈的实现方式,支持 push、pop、peek 等操作,可以用于需要后进先出的场景。
- 实现缓存:在需要缓存一定数量的数据时,可以使用 ArrayDeque。当缓存的数据量超过容量时,可以从队列头部删除最老的数据,从队列尾部添加新的数据。
- 实现事件处理器:ArrayDeque 可以作为事件处理器的实现方式,支持从队列头部获取事件进行处理,从队列尾部添加新的事件。
简单总结一下吧。
ArrayDeque 是 Java 标准库中的一种双端队列实现,底层基于数组实现。与 LinkedList 相比,ArrayDeque 的性能更优,因为它使用连续的内存空间存储元素,可以更好地利用 CPU 缓存,在大多数情况下也更快。
为什么这么说呢?
因为ArrayDeque 的底层实现是数组,而 LinkedList 的底层实现是链表。数组是一段连续的内存空间,而链表是由多个节点组成的,每个节点存储数据和指向下一个节点的指针。因此,在使用 LinkedList 时,需要频繁进行内存分配和释放,而 ArrayDeque 在创建时就一次性分配了连续的内存空间,不需要频繁进行内存分配和释放,这样可以更好地利用 CPU 缓存,提高访问效率。
现代计算机CPU对于数据的局部性有很强的依赖,如果需要访问的数据在内存中是连续存储的,那么就可以利用CPU的缓存机制,提高访问效率。而当数据存储在不同的内存块里时,每次访问都需要从内存中读取,效率会受到影响。
当然了,使用 ArrayDeque 时,数组复制操作也是需要考虑的性能消耗之一。
当 ArrayDeque 的元素数量超过了初始容量时,会触发扩容操作。扩容操作会创建一个新的数组,并将原有元素复制到新数组中。扩容操作的时间复杂度为 O(n)。
不过,ArrayDeque 的扩容策略(当 ArrayDeque 中的元素数量达到数组容量时,就需要进行扩容操作,扩容时会将数组容量扩大为原来的两倍)可以在一定程度上减少数组复制的次数和时间消耗,同时保证 ArrayDeque 的性能和空间利用率。
ArrayDeque 不仅支持常见的队列操作,如添加元素、删除元素、获取队列头部元素、获取队列尾部元素等。同时,它还支持栈操作,如 push、pop、peek 等。这使得 ArrayDeque 成为一种非常灵活的数据结构,可以用于各种场景的数据存储和处理。
参考链接:https://github.com/CarpenterLee/JCFInternals,作者:李豪,整理:沉默王二
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
继续有请王老师,来上台给大家讲讲优先级队列 PriorityQueue。
PriorityQueue 是 Java 中的一个基于优先级堆的优先队列实现,它能够在 O(log n) 的时间复杂度内实现元素的插入和删除操作,并且能够自动维护队列中元素的优先级顺序。
通俗来说,PriorityQueue 就是一个队列,但是它不是先进先出的,而是按照元素优先级进行排序的。当你往 PriorityQueue 中插入一个元素时,它会自动根据元素的优先级将其插入到合适的位置。当你从 PriorityQueue 中删除一个元素时,它会自动将优先级最高的元素出队。
下面👇🏻是一个简单的PriorityQueue示例:
在上述代码中,我们首先创建了一个 PriorityQueue 对象,并向其中添加了三个元素。然后,我们使用 while 循环遍历 PriorityQueue 中的元素,并打印出来。来看输出结果:
再来看一下示例。
在上述代码中,我们使用了 Comparator.reverseOrder() 方法指定了 PriorityQueue 的优先级顺序为降序。也就是说,PriorityQueue 中的元素会按照从大到小的顺序排序。
其他部分的代码与之前的例子相同,我们再来看一下输出结果:
对比一下两个例子的输出结果,不难发现,顺序正好相反。
PriorityQueue 的主要作用是维护一组数据的排序,使得取出数据时可以按照一定的优先级顺序进行,当我们调用 poll() 方法时,它会从队列的顶部弹出最高优先级的元素。它在很多场景下都有广泛的应用,例如任务调度、事件处理等场景,以及一些算法中需要对数据进行排序的场景。
在实际应用中,PriorityQueue 也经常用于实现 Dijkstra 算法、Prim 算法、Huffman 编码等算法。这里简单说一下这几种算法的作用,理解不了也没关系哈。
Dijkstra算法是一种用于计算带权图中的最短路径的算法。该算法采用贪心的策略,在遍历图的过程中,每次选取当前到源点距离最短的一个顶点,并以它为中心进行扩展,更新其他顶点的距离值。经过多次扩展,可以得到源点到其它所有顶点的最短路径。
Prim算法是一种用于求解最小生成树的算法,可以在加权连通图中找到一棵生成树,使得这棵生成树的所有边的权值之和最小。该算法从任意一个顶点开始,逐渐扩展生成树的规模,每次选择一个距离已生成树最近的顶点加入到生成树中。
Huffman编码是一种基于霍夫曼树的压缩算法,用于将一个字符串转换为二进制编码以进行压缩。该算法的主要思想是通过建立霍夫曼树,将出现频率较高的字符用较短的编码表示,而出现频率较低的字符用较长的编码表示,从而实现对字符串的压缩。在解压缩时,根据编码逐步解析出原字符串。
由于 PriorityQueue 的底层是基于堆实现的,因此在数据量比较大时,使用 PriorityQueue 可以获得较好的时间复杂度。
这里牵涉到了大小关系,元素大小的评判可以通过元素本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator,或者元素自身实现 Comparable 接口)来决定。
在 PriorityQueue 中,每个元素都有一个优先级,这个优先级决定了元素在队列中的位置。队列内部通过小顶堆(也可以是大顶堆)的方式来维护元素的优先级关系。具体来说,小顶堆是一个完全二叉树,任何一个非叶子节点的权值,都不大于其左右子节点的权值,这样保证了队列的顶部元素(堆顶)一定是优先级最高的元素。
完全二叉树(Complete Binary Tree)是一种二叉树,其中除了最后一层,其他层的节点数都是满的,最后一层的节点都靠左对齐。下面是一个完全二叉树的示意图:
堆是一种完全二叉树,堆的特点是根节点的值最小(小顶堆)或最大(大顶堆),并且任意非根节点i的值都不大于(或不小于)其父节点的值。
这是一颗包含整数 1, 2, 3, 4, 5, 6, 7 的小顶堆:
这是一颗大顶堆。
因为完全二叉树的结构比较规则,所以可以使用数组来存储堆的元素,而不需要使用指针等额外的空间。
在堆中,每个节点的下标和其在数组中的下标是一一对应的,假设节点下标为i,则其父节点下标为i/2,其左子节点下标为2i,其右子节点下标为2i+1。
假设有一个数组arr=[10, 20, 15, 30, 40],现在要将其转化为一个小顶堆。
首先,我们将数组按照完全二叉树的形式排列,如下图所示:
从上往下、从左往右依次给每个节点编号,如下所示:
接下来,我们按照上述公式,依次确定每个节点在数组中的位置。例如,节点1的父节点下标为1/2=0,左子节点下标为2*1=2,右子节点下标为2*1+1=3,因此节点1在数组中的位置为0,节点2在数组中的位置为2,节点3在数组中的位置为3。
对应的数组为[10, 20, 15, 30, 40],符合小顶堆的定义,即每个节点的值都小于或等于其子节点的值。
好,我们画幅图再来理解一下。
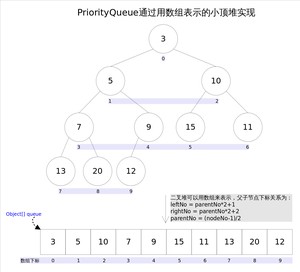
上图中我们给每个元素按照层序遍历的方式进行了编号,如果你足够细心,会发现父节点和子节点的编号是有联系的,更确切的说父子节点的编号之间有如下关系:
通过上述三个公式,可以轻易计算出某个节点的父节点以及子节点的下标。这也就是为什么可以直接用数组来存储堆的原因。
和的语义相同,都是向优先队列中插入元素,只是接口规定二者对插入失败时的处理不同,前者在插入失败时抛出异常,后则则会返回。对于PriorityQueue这两个方法其实没什么差别。
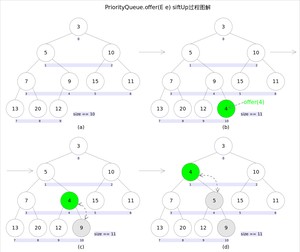
新加入的元素可能会破坏小顶堆的性质,因此需要进行必要的调整。
上述代码中,扩容函数类似于里的函数,就是再申请一个更大的数组,并将原数组的元素复制过去,这里不再赘述。需要注意的是方法,该方法用于插入元素并维持堆的特性。
调整的过程为:从指定的位置开始,将逐层与当前点的进行比较并交换,直到满足为止。注意这里的比较可以是元素的自然顺序,也可以是依靠比较器的顺序。
和的语义完全相同,都是获取但不删除队首元素,也就是队列中权值最小的那个元素,二者唯一的区别是当方法失败时前者抛出异常,后者返回。根据小顶堆的性质,堆顶那个元素就是全局最小的那个;由于堆用数组表示,根据下标关系,下标处的那个元素既是堆顶元素。所以直接返回数组下标处的那个元素即可。
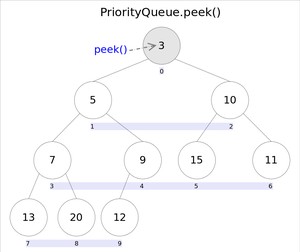
代码也就非常简洁:
和方法的语义也完全相同,都是获取并删除队首元素,区别是当方法失败时前者抛出异常,后者返回。由于删除操作会改变队列的结构,为维护小顶堆的性质,需要进行必要的调整。
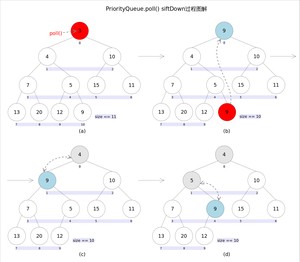
代码如下:
上述代码首先记录下标处的元素,并用最后一个元素替换下标位置的元素,之后调用方法对堆进行调整,最后返回原来下标处的那个元素(也就是最小的那个元素)。重点是方法,该方法的作用是从指定的位置开始,将逐层向下与当前点的左右孩子中较小的那个交换,直到小于或等于左右孩子中的任何一个为止。
方法用于删除队列中跟相等的某一个元素(如果有多个相等,只删除一个),该方法不是Queue接口内的方法,而是Collection接口的方法。由于删除操作会改变队列结构,所以要进行调整;又由于删除元素的位置可能是任意的,所以调整过程比其它方法稍加繁琐。
具体来说,可以分为 2 种情况:
- 删除的是最后一个元素。直接删除即可,不需要调整。
- 删除的不是最后一个元素,从删除点开始以最后一个元素为参照调用一次即可。此处不再赘述。
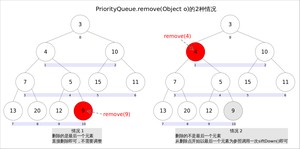
具体代码如下:
PriorityQueue 是一个非常常用的数据结构,它是一种特殊的堆(Heap)实现,可以用来高效地维护一个有序的集合。
- 它的底层实现是一个数组,通过堆的性质来维护元素的顺序。
- 取出元素时按照优先级顺序(从小到大或者从大到小)进行取出。
- 如果需要指定排序,元素必须实现 Comparable 接口或者传入一个 Comparator 来进行比较。
可以通过 LeetCode 的第 23 题:合并K个升序链表 来练习 PriorityQueue 的使用。
我把题解已经放到了技术派中,大家可以去作为参考。
合并K个升序链表
参考链接:https://github.com/CarpenterLee/JCFInternals,作者:李豪,整理:沉默王二
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
“二哥,为什么要讲时间复杂度呀?”三妹问。
“因为接下来要用到啊。后面我们学习 ArrayList、LinkedList 的时候,会比较两者在增删改查时的执行效率,而时间复杂度是衡量执行效率的一个重要标准。”我说。
“到时候跑一下代码,统计一下前后的时间差不更准确吗?”三妹反问道。
“实际上,你说的是另外一种评估方法,这种评估方法可以得出非常准确的数值,但也有很大的局限性。”我不急不慢地说。
第一,测试结果会受到测试环境的影响。你比如说,同样的代码,在我这台 iMac 上跑出来的时间和在你那台华为的 MacBook 上跑出的时间可能就差别很大。
第二,测试结果会受到测试数据的影响。你比如说,一个排序后的数组和一个没有排序后的数组,调用了同一个查询方法,得出来的结果可能会差别特别大。
“因此,我们需要这种不依赖于具体测试环境和测试数据就能粗略地估算出执行效率的方法,时间复杂度就是其中的一种,还有一种是空间复杂度。”我继续补充道,“如果你后面刷 LeetCode的话,对时间复杂度这个概念也会比较依赖。”
来看下面这段代码:
这段代码非常简单,方法体里总共 5 行代码,包括“}”那一行。每段代码的执行时间可能都不大一样,但假设我们认为每行代码的执行时间是一样的,比如说 unit_time,那么这段代码总的执行时间为多少呢?
“这个我知道呀!”三妹喊道,“第 1、5 行需要 2 个 unit_time,第 2、3 行需要 2nunit_time,总的时间就是 2(n+1)*unit_time。”
“对,一段代码的执行时间 T(n) 和总的执行次数成正比,也就是说,代码执行的次数越多,花费的时间就越多。”我总结道,“这个规律可以用一个公式来表达:”
T(n) = O(f(n))
f(n) 表示代码总的执行次数,大写 O 表示代码的执行时间 T(n) 和 f(n) 成正比。
这也就是大 O 表示法,它不关心代码具体的执行时间是多少,它关心的是代码执行时间的变化趋势,这也就是时间复杂度这个概念的由来。
对于上面那段代码 来说,影响时间复杂度的主要是第 2 行代码,其余的,像系数 2、常数 2 都是可以忽略不计的,我们只关心影响最大的那个,所以时间复杂度就表示为 。
常见的时间复杂度有这么 3 个:
代码的执行时间,和数据规模 n 没有多大关系。
括号中的 1 可以是 3,可以是 5,可以 100,我们习惯用 1 来表示,表示这段代码的执行时间是一个常数级别。比如说下面这段代码:
实际上执行了 3 次,但我们也认为这段代码的时间复杂度为 。
再举一个简单的例子。当我们访问数组中的一个元素时,它的时间复杂度就是常数时间复杂度 O(1)。
时间复杂度和数据规模 n 是线性关系。换句话说,数据规模增大 K 倍,代码执行的时间就大致增加 K 倍。
当我们遍历一个数组时,它的时间复杂度就是线性时间复杂度 O(n)。
时间复杂度和数据规模 n 是对数关系。换句话说,数据规模大幅增加时,代码执行的时间只有少量增加。
来看一下代码示例,
换句话说,当数据量 n 从 2 增加到 2^64 时,代码执行的时间只增加了 64 倍。
再举个例子。当我们对一个已排序的数组进行二分查找时,它的时间复杂度就是对数时间复杂度 O(log n)。
当我们对一个数组进行嵌套循环时,它的时间复杂度就是平方时间复杂度 O(n^2)。
当我们递归求解一个问题时,每一次递归都会分成两个子问题,这种情况下,它的时间复杂度就是指数时间复杂度 O(2^n)。
上面的代码是递归求解斐波那契数列的方法,它的时间复杂度是指数级别的。
“好了,三妹,这节就讲到这吧,理解了上面 5 个时间复杂度,后面我们学习 ArrayList、LinkedList 的时候,两者在增删改查时的执行效率就很容易对比清楚了。”我伸了个懒腰后对三妹说。
“好的,二哥。”三妹重新回答沙发上,一盘王者荣耀即将开始。
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
“终于,二哥,我们要聊 LinkedList 和 ArrayList 之间的差别了,我期待了很久。”三妹嘟囔着说。
“其实经过前面两节的分析,差别已经很清晰了。”我喃喃道。
“哥,你再说点吧,深挖一下,OK?”
“好吧,那就让我们出发吧!”
PS:为了和前面两节的源码做适当的区分,这里采用的是 Java 11 的源码,请务必注意。但整体上差别很小。
ArrayList 实现了 List 接口,继承了 AbstractList 抽象类。
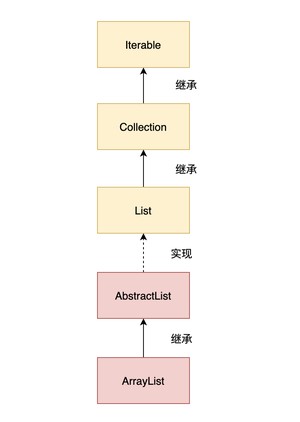
底层是基于数组实现的,并且实现了动态扩容(当需要添加新元素时,如果 elementData 数组已满,则会自动扩容,新的容量将是原来的 1.5 倍),来看一下 ArrayList 的部分源码。
ArrayList 还实现了 RandomAccess 接口,这是一个标记接口:
内部是空的,标记“实现了这个接口的类支持快速(通常是固定时间)随机访问”。快速随机访问是什么意思呢?就是说不需要遍历,就可以通过下标(索引)直接访问到内存地址。而 LinkedList 没有实现该接口,表示它不支持高效的随机访问,需要通过遍历来访问元素。
ArrayList 还实现了 Cloneable 接口,这表明 ArrayList 是支持拷贝的。ArrayList 内部的确也重写了 Object 类的 方法。
ArrayList 还实现了 Serializable 接口,同样是一个标记接口:
内部也是空的,标记“实现了这个接口的类支持序列化”。序列化是什么意思呢?Java 的序列化是指,将对象转换成以字节序列的形式来表示,这些字节序中包含了对象的字段和方法。序列化后的对象可以被写到数据库、写到文件,也可用于网络传输。
眼睛雪亮的小伙伴可能会注意到,ArrayList 中的关键字段 elementData 使用了 transient 关键字修饰,这个关键字的作用是,让它修饰的字段不被序列化。
这不前后矛盾吗?一个类既然实现了 Serilizable 接口,肯定是想要被序列化的,对吧?那为什么保存关键数据的 elementData 又不想被序列化呢?
这还得从 “ArrayList 是基于数组实现的”开始说起。大家都知道,数组是定长的,就是说,数组一旦声明了,长度(容量)就是固定的,不能像某些东西一样伸缩自如。这就很麻烦,数组一旦装满了,就不能添加新的元素进来了。
ArrayList 不想像数组这样活着,它想能屈能伸,所以它实现了动态扩容。一旦在添加元素的时候,发现容量用满了 ,就按照原来数组的 1.5 倍()进行扩容。扩容之后,再将原有的数组复制到新分配的内存地址上 。
这部分源码我们在之前讲 ArrayList 的时候就已经讲的很清楚了,这里就一笔带过。
动态扩容意味着什么?
意味着数组的实际大小可能永远无法被填满的,总有多余出来空置的内存空间。
比如说,默认的数组大小是 10,当添加第 11 个元素的时候,数组的长度扩容了 1.5 倍,也就是 15,意味着还有 4 个内存空间是闲置的,对吧?
序列化的时候,如果把整个数组都序列化的话,是不是就多序列化了 4 个内存空间。当存储的元素数量非常非常多的时候,闲置的空间就非常非常大,序列化耗费的时间就会非常非常多。
于是,ArrayList 做了一个愉快而又聪明的决定,内部提供了两个私有方法 writeObject 和 readObject 来完成序列化和反序列化。
从 writeObject 方法的源码中可以看得出,它使用了 ArrayList 的实际大小 size 而不是数组的长度()来作为元素的上限进行序列化。
此处应该有掌声啊!不是为我,为 Java 源码的作者们,他们真的是太厉害了,可以用两个词来形容他们——殚精竭虑、精益求精。
666
这是readObject方法的源码:
LinkedList 是一个继承自 AbstractSequentialList 的双向链表,因此它也可以被当作堆栈、队列或双端队列进行操作。
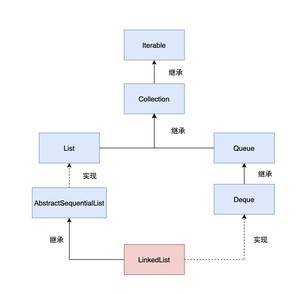
来看一下部分源码:
LinkedList 内部定义了一个 Node 节点,它包含 3 个部分:元素内容 item,前引用 prev 和后引用 next。这个在讲 LinkedList 的时候也讲过了,这里略过。
LinkedList 还实现了 Cloneable 接口,这表明 LinkedList 是支持拷贝的。
LinkedList 还实现了 Serializable 接口,这表明 LinkedList 是支持序列化的。眼睛雪亮的小伙伴可能又注意到了,LinkedList 中的关键字段 size、first、last 都使用了 transient 关键字修饰,这不又矛盾了吗?到底是想序列化还是不想序列化?
答案是 LinkedList 想按照自己的方式序列化,来看它自己实现的 方法:
发现没?LinkedList 在序列化的时候只保留了元素的内容 item,并没有保留元素的前后引用。这样就节省了不少内存空间,对吧?
那有些小伙伴可能就疑惑了,只保留元素内容,不保留前后引用,那反序列化的时候怎么办?
注意 for 循环中的 方法,它可以把链表重新链接起来,这样就恢复了链表序列化之前的顺序。很妙,对吧?
和 ArrayList 相比,LinkedList 没有实现 RandomAccess 接口,这是因为 LinkedList 存储数据的内存地址是不连续的,所以不支持随机访问。
前面我们已经从多个维度了解了 ArrayList 和 LinkedList 的实现原理和各自的特点。那接下来,我们就来聊聊 ArrayList 和 LinkedList 在新增元素时究竟谁快?
ArrayList 新增元素有两种情况,一种是直接将元素添加到数组末尾,一种是将元素插入到指定位置。
添加到数组末尾的源码(这部分前面讲 ArrayList 的时候讲过了,这里再温故一下):
很简单,先判断是否需要扩容,然后直接通过索引将元素添加到末尾。
插入到指定位置的源码:
先检查插入的位置是否在合理的范围之内,然后判断是否需要扩容,再把该位置以后的元素复制到新添加元素的位置之后,最后通过索引将元素添加到指定的位置。
LinkedList 新增元素也有两种情况,一种是直接将元素添加到队尾,一种是将元素插入到指定位置。
添加到队尾的源码:
先将队尾的节点 last 存放到临时变量 l 中,然后生成新的 Node 节点,并赋给 last,如果 l 为 null,说明是第一次添加,所以 first 为新的节点;否则将新的节点赋给之前 last 的 next。
插入到指定位置的源码:
先检查插入的位置是否在合理的范围之内,然后判断插入的位置是否是队尾,如果是,添加到队尾;否则执行 方法。
在执行 方法之前,会调用 方法查找指定位置上的元素,这一步是需要遍历 LinkedList 的。如果插入的位置靠前前半段,就从队头开始往后找;否则从队尾往前找。也就是说,如果插入的位置越靠近 LinkedList 的中间位置,遍历所花费的时间就越多。
找到指定位置上的元素(参数succ)之后,就开始执行 方法,先将 succ 的前一个节点(prev)存放到临时变量 pred 中,然后生成新的 Node 节点(newNode),并将 succ 的前一个节点变更为 newNode,如果 pred 为 null,说明插入的是队头,所以 first 为新节点;否则将 pred 的后一个节点变更为 newNode。
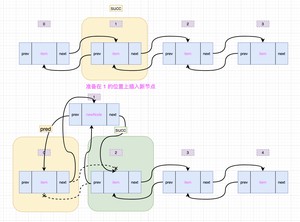
经过源码分析以后,你是不是在想:“好像 ArrayList 在新增元素的时候效率并不一定比 LinkedList 低啊!”
当两者的起始长度是一样的情况下:
- 如果是从集合的头部新增元素,ArrayList 花费的时间应该比 LinkedList 多,因为需要对头部以后的元素进行复制。
我们来测试一下:
num 为 10000,代码实测后的时间如下所示:
此时,ArrayList 花费的时间比 LinkedList 要多很多。
- 如果是从集合的中间位置新增元素,ArrayList 花费的时间搞不好要比 LinkedList 少,因为 LinkedList 需要遍历。
来看测试代码。
num 为 10000,代码实测后的时间如下所示:
ArrayList 花费的时间比 LinkedList 要少很多很多。
- 如果是从集合的尾部新增元素,ArrayList 花费的时间应该比 LinkedList 少,因为数组是一段连续的内存空间,也不需要复制数组;而链表需要创建新的对象,前后引用也要重新排列。
来看测试代码:
num 为 10000,代码实测后的时间如下所示:
ArrayList 花费的时间比 LinkedList 要少一些。
这样的结论和预期的是不是不太相符?ArrayList 在添加元素的时候如果不涉及到扩容,性能在两种情况下(中间位置新增元素、尾部新增元素)比 LinkedList 好很多,只有头部新增元素的时候比 LinkedList 差,因为数组复制的原因。
当然了,如果涉及到数组扩容的话,ArrayList 的性能就没那么可观了,因为扩容的时候也要复制数组。
ArrayList 删除元素的时候,有两种方式,一种是直接删除元素(),需要直先遍历数组,找到元素对应的索引;一种是按照索引删除元素()。
来看一下源码(其实前面也讲过了,这里温习一下):
本质上讲,两个方法是一样的,它们最后调用的都是 方法。
从源码可以看得出,只要删除的不是最后一个元素,都需要重新移动数组。删除的元素位置越靠前,代价就越大。
LinkedList 删除元素的时候,有四种常用的方式:
- ,删除指定位置上的元素
先检查索引,再调用 方法( 前后半段遍历,和新增元素操作一样)找到节点 Node,然后调用 解除节点的前后引用,同时更新前节点的后引用和后节点的前引用:
- ,直接删除元素
也是先前后半段遍历,找到要删除的元素后调用 。
- ,删除第一个节点
删除第一个节点就不需要遍历了,只需要把第二个节点更新为第一个节点即可。
- ,删除最后一个节点
删除最后一个节点和删除第一个节点类似,只需要把倒数第二个节点更新为最后一个节点即可。
可以看得出,LinkedList 在删除比较靠前和比较靠后的元素时,非常高效,但如果删除的是中间位置的元素,效率就比较低了。
这里就不再做代码测试了,感兴趣的话可以自己试试,结果和新增元素保持一致:
- 从集合头部删除元素时,ArrayList 花费的时间比 LinkedList 多很多;
- 从集合中间位置删除元素时,ArrayList 花费的时间比 LinkedList 少很多;
- 从集合尾部删除元素时,ArrayList 花费的时间比 LinkedList 少一点。
我本地的统计结果如下所示,可以作为参考:
遍历 ArrayList 找到某个元素的话,通常有两种形式:
- ,根据索引找元素
由于 ArrayList 是由数组实现的,所以根据索引找元素非常的快,一步到位。
- ,根据元素找索引
根据元素找索引的话,就需要遍历整个数组了,从头到尾依次找。
遍历 LinkedList 找到某个元素的话,通常也有两种形式:
- ,找指定位置上的元素
既然需要调用 方法,就意味着需要前后半段遍历了。
- ,找元素所在的位置
需要遍历整个链表,和 ArrayList 的 类似。
那在我们对集合遍历的时候,通常有两种做法,一种是使用 for 循环,一种是使用迭代器(Iterator)。
如果使用的是 for 循环,可想而知 LinkedList 在 get 的时候性能会非常差,因为每一次外层的 for 循环,都要执行一次 方法进行前后半段的遍历。
那如果使用的是迭代器呢?
迭代器只会调用一次 方法,在执行 的时候:先调用 AbstractSequentialList 类的 方法,再调用 AbstractList 类的 方法,再调用 LinkedList 类的 方法,如下图所示。
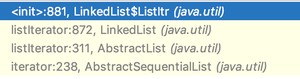
最后返回的是 LinkedList 类的内部私有类 ListItr 对象:
执行 ListItr 的构造方法时调用了一次 方法,返回第一个节点。在此之后,迭代器就执行 判断有没有下一个,执行 方法下一个节点。
由此,可以得出这样的结论:遍历 LinkedList 的时候,千万不要使用 for 循环,要使用迭代器。
也就是说,for 循环遍历的时候,ArrayList 花费的时间远小于 LinkedList;迭代器遍历的时候,两者性能差不多。
当需要频繁随机访问元素的时候,例如读取大量数据并进行处理或者需要对数据进行排序或查找的场景,可以使用 ArrayList。例如一个学生管理系统,需要对学生列表进行排序或查找操作,可以使用 ArrayList 存储学生信息,以便快速访问和处理。
当需要频繁插入和删除元素的时候,例如实现队列或栈,或者需要在中间插入或删除元素的场景,可以使用 LinkedList。例如一个实时聊天系统,需要实现一个消息队列,可以使用 LinkedList 存储消息,以便快速插入和删除消息。
在一些特殊场景下,可能需要同时支持随机访问和插入/删除操作。例如一个在线游戏系统,需要实现一个玩家列表,需要支持快速查找和遍历玩家,同时也需要支持玩家的加入和离开。在这种情况下,可以使用 LinkedList 和 ArrayList 的组合,例如使用 LinkedList 存储玩家,以便快速插入和删除玩家,同时使用 ArrayList 存储玩家列表,以便快速查找和遍历玩家。
“好了,三妹,关于 LinkedList 和 ArrayList 的差别,我们就先聊到这,你也不用太去扣细节,直到其中的差别就好了。”
“好的,二哥。”
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
“二哥,为什么要设计泛型啊?”三妹开门见山地问。
“三妹啊,听哥慢慢给你讲啊。”我说。
Java 在 1.5 时增加了泛型机制,据说专家们为此花费了 5 年左右的时间(听起来是相当不容易)。有了泛型之后,尤其是对集合类的使用,就变得更规范了。
看下面这段简单的代码。
“三妹,你能想象到在没有泛型之前该怎么办吗?”
“嗯,想不到,还是二哥你说吧。”
嗯,我们可以使用 Object 数组来设计 类。
然后,我们向 中存取数据。
“三妹,你有没有发现这两个问题?”
- Arraylist 可以存放任何类型的数据(既可以存字符串,也可以混入日期),因为所有类都继承自 Object 类。
- 从 Arraylist 取出数据的时候需要强制类型转换,因为编译器并不能确定你取的是字符串还是日期。
“嗯嗯,是的呢。”三妹说。
对比一下,你就能明显地感受到泛型的优秀之处:使用类型参数解决了元素的不确定性——参数类型为 String 的集合中是不允许存放其他类型元素的,取出数据的时候也不需要强制类型转换了。
“二哥,那怎么才能设计一个泛型呢?”
“三妹啊,你一个小白只要会用泛型就行了,还想设计泛型啊?!不过,既然你想了解,哥义不容辞。”
首先,我们来按照泛型的标准重新设计一下 类。
一个泛型类就是具有一个或多个类型变量的类。Arraylist 类引入的类型变量为 E(Element,元素的首字母),使用尖括号 括起来,放在类名的后面。
然后,我们可以用具体的类型(比如字符串)替换类型变量来实例化泛型类。
Date 类型也可以的。
其次,我们还可以在一个非泛型的类(或者泛型类)中定义泛型方法。
不过,说实话,泛型方法的定义看起来略显晦涩。来一副图吧(注意:方法返回类型和方法参数类型至少需要一个)。

现在,我们来调用一下泛型方法。
然后,我们再来说说泛型变量的限定符 。
在解释这个限定符之前,我们假设有三个类,它们之间的定义是这样的。
我们使用限定符 来重新设计一下 类。
当我们向 中添加 元素的时候,编译器会提示错误: 只允许添加 及其子类 对象,不允许添加其父类 。
也就是说,限定符 可以缩小泛型的类型范围。
“哦,明白了。”三妹若有所思的点点头,“二哥,听说虚拟机没有泛型?”
“三妹,你功课做得可以啊。哥可以肯定地回答你,虚拟机是没有泛型的。”
“怎么确定虚拟机有没有泛型呢?”三妹问。
“只要我们把泛型类的字节码进行反编译就看到了!”用反编译工具(我写这篇文章的时候用的是 jad,你也可以用其他的工具)将 class 文件反编译后,我说,“三妹,你看。”
类型变量 消失了,取而代之的是 Object !
“既然如此,那如果泛型类使用了限定符 ,结果会怎么样呢?”三妹这个问题问的很巧妙。
来看这段代码。
反编译后的结果如下。
“你看,类型变量 不见了,E 被替换成了 ”,我说,“通过以上两个例子说明,Java 虚拟机会将泛型的类型变量擦除,并替换为限定类型(没有限定的话,就用 )”
“二哥,类型擦除会有什么问题吗?”三妹又问了一个很有水平的问题。
“三妹啊,你还别说,类型擦除真的会有一些问题。”我说,“来看一下这段代码。”
在浅层的意识上,我们会想当然地认为 和 是两种不同的类型,因为 String 和 Date 是不同的类。
但由于类型擦除的原因,以上代码是不会通过编译的——编译器会提示一个错误(这正是类型擦除引发的那些“问题”):
大致的意思就是,这两个方法的参数类型在擦除后是相同的。
也就是说, 和 是同一种参数类型的方法,不能同时存在。类型变量 和 在擦除后会自动消失,method 方法的实际参数是 。
有句俗话叫做:“百闻不如一见”,但即使见到了也未必为真——泛型的擦除问题就可以很好地佐证这个观点。
“哦,明白了。二哥,听说泛型还有通配符?”
“三妹啊,哥突然觉得你很适合作一枚可爱的程序媛啊!你这预习的功课做得可真到家啊,连通配符都知道!”
通配符使用英文的问号来表示。在我们创建一个泛型对象时,可以使用关键字 限定子类,也可以使用关键字 限定父类。
我们来看下面这段代码。
1)新增 方法,判断元素在 中的位置。注意参数为 而不是泛型 。
2)新增 方法,判断元素是否在 中。注意参数为 而不是泛型 。
3)新增 方法,方便对 进行打印。
4)新增 方法,方便对 元素的更改。
因为泛型擦除的原因, 这样的语句是无法通过编译的,尽管 Wangxiaoer 是 Wanger 的子类。但如果我们确实需要这种 “向上转型” 的关系,该怎么办呢?这时候就需要通配符来发挥作用了。
利用 形式的通配符,可以实现泛型的向上转型,来看例子。
list2 的类型是 ,翻译一下就是,list2 是一个 ,其类型是 及其子类。
注意,“关键”来了!list2 并不允许通过 方法向其添加 或者 的对象,唯一例外的是 。
“那就奇了怪了,既然不让存放元素,那要 这样的 list2 有什么用呢?”三妹好奇地问。
虽然不能通过 方法往 list2 中添加元素,但可以给它赋值。
语句把 list 的值赋予了 list2,此时 。由于 list2 不允许往其添加其他元素,所以此时它是安全的——我们可以从容地对 list2 进行 、 和 。想一想,如果可以向 list2 添加元素的话,这 3 个方法反而变得不太安全,它们的值可能就会变。
利用 形式的通配符,可以向 Arraylist 中存入父类是 的元素,来看例子。
需要注意的是,无法从 这样类型的 list3 中取出数据。
好了,三妹,关于泛型,我们再来做一个简单的总结。
在 Java 中,泛型是一种强类型约束机制,可以在编译期间检查类型安全性,并且可以提高代码的复用性和可读性。
泛型的本质是参数化类型,也就是说,在定义类、接口或方法时,可以使用一个或多个类型参数来表示参数化类型。
例如这样可以定义一个泛型类。
在这个例子中, 表示类型参数,可以在类中任何需要使用类型的地方使用 T 代替具体的类型。通过使用泛型,我们可以创建一个可以存储任何类型对象的盒子。
泛型在实际开发中的应用非常广泛,例如集合框架中的 List、Set、Map 等容器类,以及并发框架中的 Future、Callable 等工具类都使用了泛型。
在 Java 的泛型机制中,有两个重要的概念:类型擦除和通配符。
泛型在编译时会将泛型类型擦除,将泛型类型替换成 Object 类型。这是为了向后兼容,避免对原有的 Java 代码造成影响。
例如,对于下面的代码:
在编译时,Java 编译器会将泛型类型 替换成 ,将 get 方法的返回值类型 Integer 替换成 Object,生成的字节码与下面的代码等价:
Java 泛型只在编译时起作用,运行时并不会保留泛型类型信息。
通配符用于表示某种未知的类型,例如 表示一个可以存储任何类型对象的 List,但是不能对其中的元素进行添加操作。通配符可以用来解决类型不确定的情况,例如在方法参数或返回值中使用。
使用通配符可以使方法更加通用,同时保证类型安全。
例如,定义一个泛型方法:
这个方法可以接受任意类型的 List,例如 、 等等。
泛型还提供了上限通配符 ,表示通配符只能接受 T 或 T 的子类。使用上限通配符可以提高程序的类型安全性。
例如,定义一个方法,只接受 Number 及其子类的 List:
这个方法可以接受 、 等等。
下限通配符(Lower Bounded Wildcards)用 super 关键字来声明,其语法形式为 ,其中 T 表示类型参数。它表示的是该类型参数必须是某个指定类的超类(包括该类本身)。
当我们需要往一个泛型集合中添加元素时,如果使用的是上限通配符,集合中的元素类型可能会被限制,从而无法添加某些类型的元素。但是,如果我们使用下限通配符,可以将指定类型的子类型添加到集合中,保证了元素的完整性。
举个例子,假设有一个类 Animal,以及两个子类 Dog 和 Cat。现在我们有一个 集合,它的类型参数必须是 Dog 或其父类类型。我们可以向该集合中添加 Dog 类型的元素,也可以添加它的子类。但是,不能向其中添加 Cat 类型的元素,因为 Cat 不是 Dog 的子类。
下面是一个使用下限通配符的示例:
需要注意的是,虽然使用下限通配符可以添加某些子类型元素,但是在读取元素时,我们只能确保其是 Object 类型的,无法确保其是指定类型或其父类型。因此,在读取元素时需要进行类型转换,如下所示:
总的来说,Java 的泛型机制是一种非常强大的类型约束机制,可以在编译时检查类型安全性,并提高代码的复用性和可读性。但是,在使用泛型时也需要注意类型擦除和通配符等问题,以确保代码的正确性。
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
PS: 这篇同样来换一个风格,一起来欣赏。
那天,小二去海康威视面试,面试官老王一上来就甩给了他一道面试题:请问 Iterator与Iterable有什么区别?
小二表示很开心,因为他3 天前刚好在《二哥的Java进阶之路》上读过这篇文章,所以回答得胸有成竹。
以下↓是小二当时读过的文章内容,他印象深刻。
在 Java 中,我们对 List 进行遍历的时候,主要有这么三种方式。
第一种:for 循环。
第二种:迭代器。
第三种:for-each。
第一种我们略过,第二种用的是 Iterator,第三种看起来是 for-each,其实背后也是 Iterator,看一下反编译后的代码(如下所示)就明白了。
for-each 只不过是个语法糖,让我们开发者在遍历 List 的时候可以写更少的代码,更简洁明了。
Iterator 是个接口,JDK 1.2 的时候就有了,用来改进 Enumeration 接口:
- 允许删除元素(增加了 remove 方法)
- 优化了方法名(Enumeration 中是 hasMoreElements 和 nextElement,不简洁)
来看一下 Iterator 的源码:
JDK 1.8 时,Iterable 接口中新增了 forEach 方法。该方法接受一个 Consumer 对象作为参数,用于对集合中的每个元素执行指定的操作。该方法的实现方式是使用 for-each 循环遍历集合中的元素,对于每个元素,调用 Consumer 对象的 accept 方法执行指定的操作。
该方法实现时首先会对 action 参数进行非空检查,如果为 null 则抛出 NullPointerException 异常。然后使用 for-each 循环遍历集合中的元素,并对每个元素调用 action.accept(t) 方法执行指定的操作。由于 Iterable 接口是 Java 集合框架中所有集合类型的基本接口,因此该方法可以被所有实现了 Iterable 接口的集合类型使用。
它对 Iterable 的每个元素执行给定操作,具体指定的操作需要自己写Consumer接口通过accept方法回调出来。
写得更浅显易懂点,就是:
如果我们仔细观察ArrayList 或者 LinkedList 的“户口本”就会发现,并没有直接找到 Iterator 的影子。
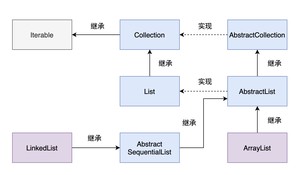
反而找到了 Iterable!
也就是说,List 的关系图谱中并没有直接使用 Iterator,而是使用 Iterable 做了过渡。
回头再来看一下第二种遍历 List 的方式。
发现刚好呼应上了。拿 ArrayList 来说吧,它重写了 Iterable 接口的 iterator 方法:
返回的对象 Itr 是个内部类,实现了 Iterator 接口,并且按照自己的方式重写了 hasNext、next、remove 等方法。
那可能有些小伙伴会问:为什么不直接将 Iterator 中的核心方法 hasNext、next 放到 Iterable 接口中呢?直接像下面这样使用不是更方便?
从英文单词的后缀语法上来看,(Iterable)able 表示这个 List 是支持迭代的,而 (Iterator)tor 表示这个 List 是如何迭代的。
支持迭代与具体怎么迭代显然不能混在一起,否则就乱的一笔。还是各司其职的好。
想一下,如果把 Iterator 和 Iterable 合并,for-each 这种遍历 List 的方式是不是就不好办了?
原则上,只要一个 List 实现了 Iterable 接口,那么它就可以使用 for-each 这种方式来遍历,那具体该怎么遍历,还是要看它自己是怎么实现 Iterator 接口的。
Map 就没办法直接使用 for-each,因为 Map 没有实现 Iterable 接口,只有通过 、、 这种返回一个 Collection 的方式才能 使用 for-each。
如果我们仔细研究 LinkedList 的源码就会发现,LinkedList 并没有直接重写 Iterable 接口的 iterator 方法,而是由它的父类 AbstractSequentialList 来完成。
LinkedList 重写了 listIterator 方法:
这里我们发现了一个新的迭代器 ListIterator,它继承了 Iterator 接口,在遍历List 时可以从任意下标开始遍历,而且支持双向遍历。
我们知道,集合(Collection)不仅有 List,还有 Set,那 Iterator 不仅支持 List,还支持 Set,但 ListIterator 就只支持 List。
那可能有些小伙伴会问:为什么不直接让 List 实现 Iterator 接口,而是要用内部类来实现呢?
这是因为有些 List 可能会有多种遍历方式,比如说 LinkedList,除了支持正序的遍历方式,还支持逆序的遍历方式——DescendingIterator:
可以看得到,DescendingIterator 刚好利用了 ListIterator 向前遍历的方式。可以通过以下的方式来使用:
好了,关于Iterator与Iterable我们就先聊这么多,总结两点:
- 学会深入思考,一点点抽丝剥茧,多想想为什么这样实现,很多问题没有自己想象中的那么复杂。
- 遇到疑惑不放弃,这是提升自己最好的机会,遇到某个疑难的点,解决的过程中会挖掘出很多相关的东西。
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
这篇文章同样采用小二去面试的形式,给大家换个胃口。
那天,小二去阿里面试,面试官老王一上来就甩给了他一道面试题:为什么阿里的 Java 开发手册里会强制不要在 foreach 里进行元素的删除操作?

小二听完这句话就乐了。为什么呢?因为一天前他刚在《二哥的Java进阶之路》上看到过这道题的答案。
以下是整篇文章的内容。
为了镇楼,先搬一段英文来解释一下 fail-fast。
In systems design, a fail-fast system is one which immediately reports at its interface any condition that is likely to indicate a failure. Fail-fast systems are usually designed to stop normal operation rather than attempt to continue a possibly flawed process. Such designs often check the system's state at several points in an operation, so any failures can be detected early. The responsibility of a fail-fast module is detecting errors, then letting the next-highest level of the system handle them.
这段话的大致意思就是,fail-fast 是一种通用的系统设计思想,一旦检测到可能会发生错误,就立马抛出异常,程序将不再往下执行。
一旦检测到 wanger 为 null,就立马抛出异常,让调用者来决定这种情况下该怎么处理,下一步 就不会执行了——避免更严重的错误出现。
很多时候,我们会把 fail-fast 归类为 Java 集合框架的一种错误检测机制,但其实 fail-fast 并不是 Java 集合框架特有的机制。
之所以我们把 fail-fast 放在集合框架篇里介绍,是因为问题比较容易再现。
这段代码看起来没有任何问题,但运行起来就报错了。

根据错误的堆栈信息,我们可以定位到 ArrayList 的第 901 行代码。
也就是说,remove 的时候触发执行了 方法,该方法对 modCount 和 expectedModCount 进行了比较,发现两者不等,就抛出了 异常。
为什么会执行 方法呢?
是因为 for-each 本质上是个语法糖,底层是通过迭代器 Iterator 配合 while 循环实现的,来看一下反编译后的字节码。
来看一下 ArrayList 的 iterator 方法吧:
内部类 Itr 实现了 Iterator 接口,这是 Itr 的源码。
也就是说 的时候 expectedModCount 被赋值为 modCount,而 modCount 是 ArrayList 中的一个计数器,用于记录 ArrayList 对象被修改的次数。ArrayList 的修改操作包括添加、删除、设置元素值等。每次对 ArrayList 进行修改操作时,modCount 的值会自增 1。
在迭代 ArrayList 时,如果迭代过程中发现 modCount 的值与迭代器的 expectedModCount 不一致,则说明 ArrayList 已被修改过,此时会抛出 ConcurrentModificationException 异常。这种机制可以保证迭代器在遍历 ArrayList 时,不会遗漏或重复元素,同时也可以在多线程环境下检测到并发修改问题。
我们来继续定位之前报错的错误堆栈。这是之前的代码。
由于 list 此前执行了 3 次 add 方法。
- add 方法调用 ensureCapacityInternal 方法
- ensureCapacityInternal 方法调用 ensureExplicitCapacity 方法
- ensureExplicitCapacity 方法中会执行
所以 modCount 的值在经过三次 add 后为 3,于是 后 expectedModCount 的值也为 3(回到前面去看一下 Itr 的源码)。
接着来执行 for-each 的循环遍历。
执行第一次循环时,发现“沉默王二”等于 str,于是执行 。
- remove 方法调用 fastRemove 方法
- fastRemove 方法中会执行
modCount 的值变成了 4。
第二次遍历时,会执行 Itr 的 next 方法(),next 方法就会调用 方法。
此时 expectedModCount 为 3,modCount 为 4,就只好抛出 ConcurrentModificationException 异常了。
那其实在阿里巴巴的 Java 开发手册里也提到了,不要在 for-each 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator 方式。

那原因其实就是我们上面分析的这些,出于 fail-fast 保护机制。
break 后循环就不再遍历了,意味着 Iterator 的 next 方法不再执行了,也就意味着 方法不再执行了,所以异常也就不会抛出了。
但是呢,当 List 中有重复元素要删除的时候,break 就不合适了。
for 循环虽然可以避开 fail-fast 保护机制,也就说 remove 元素后不再抛出异常;但是呢,这段程序在原则上是有问题的。为什么呢?
第一次循环的时候,i 为 0, 为 3,当执行完 remove 方法后,i 为 1, 却变成了 2,因为 list 的大小在 remove 后发生了变化,也就意味着“沉默王三”这个元素被跳过了。能明白吗?
remove 之前 为“沉默王三”;但 remove 之后 变成了“一个文章真特么有趣的程序员”,而 变成了“沉默王三”。
为什么使用 Iterator 的 remove 方法就可以避开 fail-fast 保护机制呢?看一下 remove 的源码就明白了。
删除完会执行 ,保证了 expectedModCount 与 modCount 的同步。
为什么不能在foreach里执行删除操作?
因为 foreach 循环是基于迭代器实现的,而迭代器在遍历集合时会维护一个 expectedModCount 属性来记录集合被修改的次数。如果在 foreach 循环中执行删除操作会导致 expectedModCount 属性值与实际的 modCount 属性值不一致,从而导致迭代器的 hasNext() 和 next() 方法抛出 ConcurrentModificationException 异常。
为了避免这种情况,应该使用迭代器的 remove() 方法来删除元素,该方法会在删除元素后更新迭代器状态,确保循环的正确性。如果需要在循环中删除元素,应该使用迭代器的 remove() 方法,而不是集合自身的 remove() 方法。
就像这样。
除此之外,我们还可以采用 Stream 流的filter() 方法来过滤集合中的元素,然后再通过 collect() 方法将过滤后的元素收集到一个新的集合中。
好了,关于这个问题,就聊到这里吧,希望能帮助到你。
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
在前面学习优先级队列的时候,我们曾提到过 Comparable和Comparator,那这篇继续以面试官的角度去切入,一起来看。
那天,小二去马蜂窝面试,面试官老王一上来就甩给了他一道面试题:请问Comparable和Comparator有什么区别?小二差点笑出声,因为三年前,也就是 2021 年,他在《二哥的Java进阶之路》上看到过这题😆。
Comparable 和 Comparator 是 Java 的两个接口,从名字上我们就能够读出来它们俩的相似性:以某种方式来比较两个对象。
但它们之间到底有什么区别呢?请随我来,打怪进阶喽!
Comparable 接口的定义非常简单,源码如下所示。
如果一个类实现了 Comparable 接口(只需要干一件事,重写 方法),就可以按照自己制定的规则将由它创建的对象进行比较。下面给出一个例子。
在上面的示例中,我创建了一个 Cmower 类,它有两个字段:age 和 name。Cmower 类实现了 Comparable 接口,并重写了 方法。
程序输出的结果是“沉默王三比较年轻有为”,因为他比沉默王二小三岁。这个结果有什么凭证吗?
凭证就在于 方法,该方法的返回值可能为负数,零或者正数,代表的意思是该对象按照排序的规则小于、等于或者大于要比较的对象。如果指定对象的类型与此对象不能进行比较,则引发 异常(自从有了泛型,这种情况就少有发生了)。
Comparator 接口的定义相比较于 Comparable 就复杂的多了,不过,核心的方法只有两个,来看一下源码。
第一个方法 的返回值可能为负数,零或者正数,代表的意思是第一个对象小于、等于或者大于第二个对象。
第二个方法 需要传入一个 Object 作为参数,并判断该 Object 是否和 Comparator 保持一致。
有时候,我们想让类保持它的原貌,不想主动实现 Comparable 接口,但我们又需要它们之间进行比较,该怎么办呢?
Comparator 就派上用场了,来看一下示例。
Cmower 类有两个字段:age 和 name,意味着该类可以按照 age 或者 name 进行排序。
按照 age 进行比较。当然也可以再实现一个比较器,按照 name 进行自然排序,示例如下。
创建了三个对象,age 不同,name 不同,并把它们加入到了 List 当中。然后使用 List 的 方法进行排序,来看一下输出的结果。
这意味着沉默王三的年纪比沉默王二小,排在第一位;沉默王一的年纪比沉默王二大,排在第三位。和我们的预期完全符合。
借此机会,再来看一下 sort 方法的源码:
可以看到,参数就是一个 Comparator 接口,并且使用了泛型 。
通过上面的两个例子可以比较出 Comparable 和 Comparator 两者之间的区别:
- 一个类实现了 Comparable 接口,意味着该类的对象可以直接进行比较(排序),但比较(排序)的方式只有一种,很单一。
- 一个类如果想要保持原样,又需要进行不同方式的比较(排序),就可以定制比较器(实现 Comparator 接口)。
- Comparable 接口在 包下,而 接口在 包下,算不上是亲兄弟,但可以称得上是表(堂)兄弟。
举个不恰当的例子。我想从洛阳出发去北京看长城,体验一下好汉的感觉,要么坐飞机,要么坐高铁;但如果是孙悟空的话,翻个筋斗就到了。我和孙悟空之间有什么区别呢?
孙悟空自己实现了 Comparable 接口(他那年代也没有飞机和高铁,没得选),而我可以借助 Comparator 接口(现代化的交通工具)。
好了,关于 Comparable 和 Comparator 我们就先聊这么多。总而言之,如果对象的排序需要基于自然顺序,请选择 ,如果需要按照对象的不同属性进行排序,请选择 。
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
在Java中,我们一般都会使用到Map,比如HashMap这样的具体实现。更高级一点,我们可能会使用WeakHashMap。
WeakHashMap其实和HashMap大多数行为是一样的,只是WeakHashMap不会阻止GC回收key对象(不是value),那么WeakHashMap是怎么做到的呢,这就是我们研究的主要问题。
在开始WeakHashMap之前,我们先要对弱引用有一定的了解。
在Java中,有四种引用类型
- 强引用(Strong Reference),我们正常编码时默认的引用类型,强应用之所以为强,是因为如果一个对象到GC Roots强引用可到达,就可以阻止GC回收该对象
- 软引用(Soft Reference)阻止GC回收的能力相对弱一些,如果是软引用可以到达,那么这个对象会停留在内存更时间上长一些。当内存不足时垃圾回收器才会回收这些软引用可到达的对象
- 弱引用(WeakReference)无法阻止GC回收,如果一个对象时弱引用可到达,那么在下一个GC回收执行时,该对象就会被回收掉。
- 虚引用(Phantom Reference)十分脆弱,它的唯一作用就是当其指向的对象被回收之后,自己被加入到引用队列,用作记录该引用指向的对象已被销毁
这其中还有一个概念叫做引用队列(Reference Queue)
- 一般情况下,一个对象标记为垃圾(并不代表回收了)后,会加入到引用队列。
- 对于虚引用来说,它指向的对象会只有被回收后才会加入引用队列,所以可以用作记录该引用指向的对象是否回收。
如源码所示,
- WeakHashMap的Entry继承了WeakReference。
- 其中Key作为了WeakReference指向的对象
- 因此WeakHashMap利用了WeakReference的机制来实现不阻止GC回收Key
在Javadoc中关于WeakHashMap有这样的描述,当key不再引用时,其对应的key/value也会被移除。
那么是如何移除的呢,这里我们通常有两种假设策略
- 当对象被回收的时候,进行通知
- WeakHashMap轮询处理时效的Entry
而WeakHashMap采用的是轮询的形式,在其put/get/size等方法调用的时候都会预先调用一个poll的方法,来检查并删除失效的Entry
为什么没有使用看似更好的通知呢,我想是因为在Java中没有一个可靠的通知回调,比如大家常说的finalize方法,其实也不是标准的,不同的JVM可以实现不同,甚至是不调用这个方法。
当然除了单纯的看源码,进行合理的验证是检验分析正确的一个重要方法。
这里首先,我们定义一个MyObject类,处理一下finalize方法(在我的测试机上可以正常调用,仅仅做为辅助验证手段)
然后是调用者的代码,如下
我们按照如下操作
- 点击fab控件,每次对WeakhashMap对象增加一个Entry,并打印WeakHashMap的size 执行3此
- 在没有强制触发GC时,WeakHashMap对象size一直会增加
- 手动出发Force GC,我们会看到MyObject有finalize方法被调用
- 再次点击fab空间,然后输出的WeakHashMap size急剧减少。
- 同样我们收到在WeakHashMap增加的日志也会输出
注意:System.gc()并不一定可以工作,建议使用Android Studio的Force GC
完整的测试代码可以访问这里 https://github.com/androidyue/WeakHashMapSample
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/11923.html