
关于 python 迭代器的基本介绍和使用可以看我之前写的博客: Python迭代器的创建和使用:iter()和next()方法,迭代器长度的获取
将一个列表转换为迭代器(用 iter 方法),并逐个元素打印。
现在我们把事情搞复杂一点,用类来产生一个相同的列表,并逐个元素打印。
要想让一个类作为迭代器,就要用到 __ iter __() 方法,python中实现了__iter __() 方法的对象是可迭代的,也就是一个迭代器。(对象就是类的一个实例)
__ iter __() 函数是python的魔术方法,这个函数的要求是返回值必须是一个迭代器。该方法使得类成为一个迭代器。
现在我们用类作为迭代器实现 0-4 整型迭代:
如果我们想以列表形式每次输出5个数,输出范围是0-20,比如这样:
[0, 1, 2, 3, 4]
[5, 6, 7, 8, 9]
[10, 11, 12, 13, 14]
[15, 16, 17, 18, 19]
那么第二步中的类就实现不了这样的功能,下面我们将这个类的功能进行扩展,使它变得更复杂。
__ iter__() 方法每次只能返回list中的一个元素,实现不了返回一组元素的功能。所以我们要手动分割数组来完成该功能,这里引入了一个新的方法:__ next __()
__ next __() 方法的功能是返回迭代器的下一个元素
我们有了 __ next __ () 之后,就不需要在 __ iter __ () 中返回一个列表迭代器了,因为这个功能一般由__ next __() 完成。现在引入一个概念:
把一个类作为一个迭代器使用需要在类中实现两个方法 iter() 与 next()
__ iter __() 的返回值是 self
也就是说这种情况下,__ iter__() 一般写成下面这种格式,复杂的功能实现交给 __ next __() 完成。
return self 可以理解为 我返回我自己,相当于这个类自己在递归,不断迭代自己(自嗨),那不就是一个迭代器了吗?
现在我们来实现每次输出5个数的功能:
现在我们就用自己定义的类实现了迭代器的功能,这有助于我们理解和完成更复杂的功能,毕竟在一个大的项目里,用迭代器处理数据基本都需要用类来实现。
掌握了python迭代器的基本使用之后,我们再来看看更复杂的pytorch的迭代器。pytorch进行数据处理必然离不开 Dataset 和 DataLoader, Dataset 用于产生迭代器, DataLoader加载迭代器产生可以用enumerate 迭代控制的 target和 label。
from torch.utils.data import Dataset,DataLoader
这里我们用MNIST数据集的测试集来讲解Dataset 和 DataLoader的使用。
代码中涉及到MNIST数据集的处理请参考博客 MNIST手写数字数据集读取方法
4.1 用自己定义的 MnistDataset 类,不继承 torch 的 Dataset
首先我们自己写一个MnistDataset 类用于数据集处理和加载,不继承 torch 的 Dataset 。这里用到了一个新的方法 __ getitem __(self, index) ,其中index表示索引(即下标)。
__ getitem __() 的作用是让类拥有迭代功能,它与 __ iter __() 的不同之处在于: __ iter __() 的返回值必须是迭代器,而 __ getitem __() 的返回值没有限制。
只要类中有 __ getitem __() 方法,这个类的对象就是迭代器。
这里我们直接对 dataset 进行迭代,可以发现每一次迭代都会输出一个 label,并且这个label是数字,而不是list或者tensor格式。
现在我们用 DataLoader 对dataset进行加载,改变代码如下:
可以发现,DataLoader 可以正常进行加载,并且可以设置batch_size的大小,输出的label是 tensor 格式。
所以用进行数据时并不一定需要继承 torch 的 Dataset ,自己写一个相同功能的类也可以。
那么问题来了,既然 dataset 本身就可以迭代,为什么还需要 DataLoader 呢?答案当然是用DataLoader 可以设置 batch_size、shuffle 等设置,实现更灵活的数据集加载方式。
4.2 继承 torch 的 Dataset 类进行数据处理
我们只需要对4.1的代码稍作修改就可以继承Dataset 类了:
发现程序报错了,说MnistDataset类没有 len() 方法。这里我们来看一下__ len__() 方法,它的作用是返回容器中元素的个数,这里就是指返回 MNIST 数据集中图片的数量。
为什么一定需要__ len__() 方法呢?4.1中不继承Dataset 时候没有写__ len__() 方法不是一样可以加载吗?这就是pytorch的严谨之处了,没有这个方法,程序就不知道有多少数据量,用 enumerate 迭代时怎么知道到哪里停止呢?
我们再看看 pytorch 官网对 Dataset 的解释:
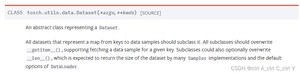
可以看到,子类必须重写__getitem__(),可以选择性覆盖__len__(),许多 Sampler 实现和 DataLoader的默认选项期望它返回数据集的大小。
所以继承了 Dataset,用 DataLoader 加载时,必须要有__len__() 方法。
那我们现在给 MnistDataset(Dataset) 类增加__len__() 方法:
现在就可以正常运行了。如果设置 shuffle=True,也没有任何问题:
以上就是基本的迭代器使用方法,对于迭代器我还有很多不理解的地方,所以这篇博客也会不断完善。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/10403.html