

XML 作为程序开发中非常常用的数据文档之一,各个语言或是开发环境都有对应的用于处理 XML 文件的库。在 C++ 语言中,TinyXML-2 就是这样的一个库。
TinyXML-2 是一个简单,小巧,高性能的 C++ 的 XML 解析器,它能够容易地集成到其他程序中。
与 TinyXML-2 有关的两个网页如下:
- GitHub 主页:github.com/leethomason…
- 在线帮助文档:leethomason.github.io/tinyxml2/
在 tinyxml2 中有两个主要文件:
- tinyxml2.cpp
- tinyxml2.h
通常来讲,你仅仅需要将上面的两个主要的文件放到你的工程中,就可以使用它了。在编译时只需要将这两个和其他的源文件一起编译即可。
另外,还有一个测试文件:
- xmltest.cpp
从这个文件里,我们可以看到关于 tinyxml2 的很多用法。不过仅仅是使用 tinyxml2 的话,可以暂时忽略这个文件。
通过 TinyXML-2 读取 XML 文件很简单,仅仅通过下面的两行代码,就能将一个 XML 文件解析到 XMLDocument 对象中:
在解析到 XMLDocument 对象中后,就可以通过这个对象来获取这个 XML 文件中的所有信息。这个对象跟其他的 C++ 对象一样,能够在栈上建立,也可以使用 new 或 delete 关键字在堆上创建或删除。
下面是一段读取和遍历 XML 文件的所有内容的代码,这也是这篇文章中最重要的部分了,如果看懂了的话,那么后面的内容就不用再看了:
这段代码也在这里 gist.github.com/Lee-swifter…,大家帮忙点个赞哈。。。
但是在详细解析这段代码之前,我们需要了解 XMLDocument 的内存模型,才能进一步分析这段代码。

上面这个图是 TinyXML-2 中用于表示 XML 内容的几个类的图。可见 TinyXML-2 将 XML 中的所有元素都归为 XMLNode。XMLNode 是一个抽象类,因此其继承出几种不同的类型以区分 XML 中的不同内容:
- XMLDocument 表示一个 XML 文档
- XMLElement 表示一个 XML 的元素
- XMLComment 表示一个 XML 中的注释
- XMLDeclaration 表示 XML 的声明,一般都是在 XML 最前面
- XMLText 表示一个 XML 中的文本信息
- XMLUnknow 未知的类型
这些类型光说一下可能不直观,所以,先放上一张示例图: 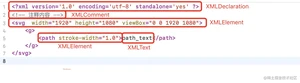
TinyXML-2 在内存中使用兄弟孩子表示法来表示生成 XML 的一个树,在 XMLNode 中最重要的两个方法就是:
- const XMLNode * FirstChild() const
- const XMLNode * NextSibling() const
这两个方法是在兄弟孩子表示法中用于遍历的常用函数。对于兄弟孩子表示法不熟的人,看一下这张图: 
在这里,我们可以只需要将图中的所有节点看成一个 XMLNode 对象就明白了。通过上面的两个方法就可以递归遍历一个 XML 中的所有节点。
对于一个 XMLNode,可以通过 方法获取其内容,而且可以通过对应的 ToXXX 方法,安全的转换为其子类型。
结合上面所说的两点,一个遍历 XML 的代码就可以出来了:
如果需要更改 XML 的话,仅仅需要创建出 XMLNode 然后对其进行操作,并添加到其他的节点上。但是这里需要特别注意的一点是:任何 XMLDocument 的子节点,例如 XMLElement、XMLText 等,只能通过调用对应的方法来创建,即 XMLDocument::NewElement、XMLDocument::NewText 这种方法。尽管你可以拥有这些节点对象的指针,这些子节点仍然归属于其 XMLDocument 对象。当 XMLDocument 对象被删除时,它所包含的所有节点也会被删除。
对于一个 XML 来讲,最需要关注的就是这个 XML 对应的 XMLDocument 对象了。它可以用来创建子节点,并进行一些最主要的操作。对于节点的插入和删除,可以使用 XMLNode 的下面的一些方法:
- XMLNode * InsertFirstChild(XMLNode *addThis)
- XMLNode * InsertAfterChild(XMLNode *afterThis, XMLNode *addThis)
- XMLNode * InsertEndChild(XMLNode *addThis)
- void DeleteChild(XMLNode *node)
- void DeleteChildren()
例如:下面的代码将创建一个 XML 文件:
其创建出来的 XML 文件如下:
想要将 XML 保存到文件中时,仅需要调用下面的方法:

这里是关于其主页上的几个特点的翻译,如果想快速上手 tinyxml2,并觉得自己不会踩坑,可以直接跳过。
在解析 XML 时,TinyXML-2 仅使用 utf-8 编码,并假定所有的 XML 文件都是用 utf-8 进行编码的。
加载/保存的文件名将会不加修改地传递给底层操作系统。
保留空白字符(默认)
Microsoft 关于空白字符的处理有一篇很牛逼的文章:msdn.microsoft.com/en-us/libra…
在默认情况下,TinyXML-2 用一种合理的方式保留空白字符。按照 XML 规范的要求,所有newlines / carriage-returns / line-feeds 都被规范化为换行字符。
在文本中的空白字符将会保留。例如:
这个 XML 中,前面的空格和后面的两个空格将会被保留。在文本中的换行符也将会被保留,例如下面的 XML:
但是,在元素之间的空白字符不会被保留。因为跟踪和报告元素之间的空白内容是很尴尬的,而且通常也没有任何价值,于是乎,TinyXML-2 会将下面的两个 XNL 认作相同的内容:
删除空白字符
某些应用程序更希望将空白字符删掉,TinyXML-2 可以通过向 XMLDocument 的构造函数传入空白字符的参数来支持,默认情况下是保留空白字符。
当你使用 来删除空白字符时,TinyXML-2 将会
- 删除前导和末尾的空白字符
- 将换行符转换为一个空白字符
- 将连续的空白字符折叠成一个空白字符
但需要注意的是,使用会有性能影响,它本质上将倒是 XML 被解析两次。
TinyXML-2 如果在解析 XML 时发生错误,那么它将会报告错误发生所在行的行号。此外,所有节点(元素、声明、文本、注释等)和属性在解析时都有一个行号记录。这样的话,应用程序就可以对解析的XML文档执行额外的验证。
TinyXML-2 能够识别一些定义好的特殊字符,即:
在读取 XML 文档时,这些字符将会别识别为他们的 UTF-8 的值。例如,如果 XML 中一段文本是:
如果你调用从这个 XMLText 对象调用 Value() 获取其值时,将会得到 "Far & Away"。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/10400.html