
uvm中的phase共有9种,按照是否消耗仿真时间可以分为function phase和task phase。其中只有run_phase是耗时的,给DUT施加激励和检测输出也是在这个phase里完成的。
UVM整体框架的运行都是从tb中的一句run_test("my_test")开始 ,那么在这句程序背后发生了什么呢?
首先uvm的树根uvm_root类对象uvm_top创建了uvm_test_top,这一过程体现在仿真中就是在0时刻创建。接着引入的phase机制清晰地实现UVM树的层次例化,同时将仿真过程层次化。具体而言,uvm_top从时间和空间两个维度规定了执行顺序。时间上,仿真时不同phase按照某种时间顺序执行。空间上,仿真时同—phase不同组件按照某种层次顺序执行。
而这一切都是由UVM自动完成的,整体流程就是先例化uvm_top,之后例化uvm_test_top,之后全部component按照一定顺序实现build_phase之后,全部component再按照定顺序实现connect_phase()等等,直到最终的$finish()。
以一个case举例,包含的phase的执行顺序代码可能如下:
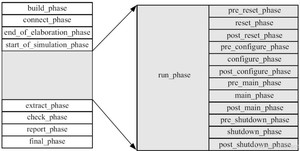
其中run_phase又可以分成12个小phase,他们是并行执行的关系:
当然,并不是所有的phase都一定会被使用到,在验证时使用频率最高的phase一般是:build_phase,connect_phase,main_phase。
UVM这么做的好处是什么呢?一是方便验证工程师将不同的代码写进对应的phase中,二是有利于其他验证方法学向UVM迁移。因为它的阶段划分非常细致,在迁移时总能找到一个phase对应原来方法学中的仿真阶段。
UVM为什么要引入run_phase里的12个小phase呢?
这有助于实现更加精细化的控制:reset、configure、main、shutdown四个phase是核心,可以模拟DUT复位,配置,运行,断电的行为。在没有这些细分的phase之前,这些操作要在scoreboard、reference model等加入一些额外的代码来保证验证平台不会出错。但是现在分别在scoreboard、reference model及其他部分的reset_ phase写好相关代码,之后如果想做一次复位操作,那么只要通过phase的跳转,就会自动跳转回reset_phase。
9个phase之间是自上向下的执行顺序,这是一种的时间的概念。而每种phase本身又具有执行顺序,这是一种空间的概念,描述的是运行某一phase时component从顶层到底层或是底层到顶层的执行顺序。
为什么需要规定是这样的执行顺序呢?以build_phase为例,driver和monitor作为agent中的成员变量,需要在agent的build_phase中进行实例化。如果driver的build_phase在agent的build_phase之前执行,此时driver本身还没有实例化,这样调用就会发生错误。
可以发现其实大部分的phase都是以自下向上的顺序执行,包括run_phase。但与其它function phase不同的是,run_phase消耗时间,并不是等drv之类的run_phase执行完才执行agt的run_phase,而是将这些run_phase通过fork join_none的形式全部启动,同时运行。
对于同一个component来说,12个小phase是顺序执行的,但这不意味着前一个phase执行结束后就会马上执行下一个phase。以component A 和 B举例,A的main_phase在100时刻执行结束,B的main_phase在400时刻执行结束,那么A和B的post_main_phase都会在400时刻才开始执行。在100~400时刻中,A处于等待B的状态;但从整个平台来看,各个phase之间当然不存在空白。
而这种同步不仅适用于不同component之间,对同一个component的run_phase和post_shutdown_phase来说也需要实现同步:只有当run_phase和它的post_shutdown_phase都完成后才会进入下一个phase。
验证平台非常复杂,要搭建一个验证平台是一件相当繁杂的事情,要正确地掌握并理顺这些步骤是一个相当艰难的过程。比如在env中会实例化agent、scoreboard、reference model等,agent下面又会有sequencer、driver、monitor。并且,这些组件之间还有连接关系,如agent中monitor的输出要送给scoreboard或reference model,这种通信的前提是要先将reference model和scoreboard连接在一起。那么可以:
这里面反应出来的问题就是最后一句话一定要放在最后写,因为连接的前提是所有的组件已经实例化。但是,reference_model.connect(scoreboard)的要求则没有那么高,只需要在上述代码中reference_model = new之后任何一个地方编写即可。可以看出,代码的书写顺序会影响代码的实现。若要将代码顺序的影响降低到最低,可以按照如下方式:
UVM采用了这种方法,它将前面实例化的部分都放在build_phase来做,而连接关系放在connect_phase来做,这就是phase机制的优势:在不同的时间做不同的事。
遵循UVM的代码顺序划分原则:build做实例化,connect做连接等等可以很大程度上减少验证平台开发者的工作量,并且便于我们理解运用。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/9884.html