
SqlSugar作为一款专为.NET平台设计的轻量级ORM(对象关系映射)框架,其进阶使用中的高级查询与性能优化涵盖了多个方面的内容。
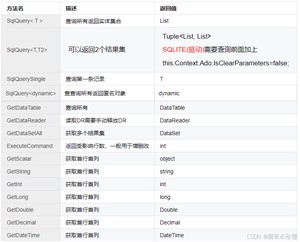
SqlSugar提供了丰富的高级查询功能,以满足复杂的业务需求,主要包括:
方法列表:
为了提升数据库操作的性能,SqlSugar提供了多种优化措施。
二级缓存是将结果集进行缓存,当SQL和参数没发生变化的时候从缓存里面读取数据,减少数据库的读取操作。
- 维护方便:SqlSugar的 二级缓存 支持单表和多表的 CRUD 自动缓存更新 ,减少了复杂的缓存KEY维护操作
- 使用方便:可以直接在Queryable.WithCache直接缓存当前对象
- 外部集成:通过实现ICacheService接口,来调用外部缓存方法,想用什么实现什么
注意:Sql语句一直在变的就不适合缓存,比如 ID=?这种SQL都在变化,并且表的数量巨大这种情况就不要使用缓存了,缓存适合加
1.BulkCopy
大数据插入
2.BulkUpdate
大数据更新
3. BulkMerge (5.1.4.109)
大数据 :插入或者更新
4. BulkQuery
普通查询就行了性能超快
5. BulkDelete
直接用分页删除就行了
自带分表支持按年、按季、按月、按周、按日进行分表(支持混合使用)。
- 可扩展架构设计,比如一个ERP用5年不卡,到了10就卡了,很多人都是备份然后清空数据
- 数据量太多 ,例如每天都有 几十上百万的数据进入库,如果不分表后面查询将会非常缓慢
- 性能瓶颈 ,数据库现有数据超过1个亿,很多情况下索引会莫名失效,性能大大下降
1.定义实体:
我们定义一个实体,主键不能用自增或者int ,设为long或者guid都可以,我例子就用自带的雪花ID实现分表。
2.同步表和结构:
假如分了20张表,实体类发生变更,那么 20张表可以自动同步结构,与实体一致。
注意:插入会自动建表不需要这行代码,主要用于实体改动后同步多个表结构,或者一张表没有初始一张,禁止写到业务里面多次执行。
1.查询: 时间过滤
通过开始时间和结束时间自动生成CreateTime的过滤并且找到对应时间的表。
2. 查询: 选择最近的表
如果下面是按年分表 Take(3) 表示 只查 最近3年的分表数据。
3.查询: 精准定位一张表
根据分表字段的值可以精准的定位到具体是哪一个分表,比Take(N)性能要高出很多
4.查询: 表达式定位哪几张表
5.查询: 分表Join正常表
6.查询: 分表JOIN分表
7. 查询: 性能优化
条件尽可能写在SplitTable前面,因为这样会先过滤在合并
8.查询: 所有分表检索
因为我们用的是Long所以采用雪花ID插入(guid也可以禁止使用自增列)
注意:.SplitTable不要漏掉了
1.推荐用法:新功能 5.0.7.7 preview及以上版本
2.最近3张表都执行一遍删除
3.精准删除
相对于上面的操作性能更高,可以精准找到具体表
4.范围删除
推荐用法: 新功能 5.0.7.7 preview及以上版本
更多用法:
1.配置从表
- 如果存在事务所有操作都走主库,不存在事务 修改、写入、删除走主库,查询操作走从库
- HitRate 越大走这个从库的概率越大
假设A从库 HitRate设置为5,假设B从库 HitRate设置为10,A的概率为33.3% B的概率为66.6%
2.强制走主库
新功能:5.0.8 用法和Queryable一样
事务
通过配置走主库
综上所述,SqlSugar的高级查询功能提供了强大的数据筛选、排序和连表查询能力,而性能优化则通过缓存、SQL优化、批量操作等多种手段来提高数据库操作的效率。这些特性使得SqlSugar在.NET开发领域具有广泛的应用前景。
“笑对人生,智慧同行!博客新文出炉,微信订阅号更新更实时,等你笑纳~”
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/9555.html