
==SQL(Structured Query Language)==是“结构化查询语言”,它是对关系型数据库的操作语言。它可以应用到所有关系型数据库中,例如:MySQL、Oracle、SQL Server 等。SQL 标准(ANSI/ISO)有:
- SQL-92:1992 年发布的 SQL 语言标准;
- SQL:1999:1999 年发布的 SQL 语言标签;
- SQL:2003:2003 年发布的 SQL 语言标签;
这些标准就与 JDK 的版本一样,在新的版本中总要有一些语法的变化。不同时期的数据库对不同标准做了实现。
虽然 SQL 可以用在所有关系型数据库中,但很多数据库还都有标准之后的一些语法,我们可以称之为“方言”。例如 MySQL 中的 LIMIT 语句就是 MySQL 独有的方言,其它数据库都不支持!当然,Oracle 或 SQL Server 都有自己的方言。
- SQL 语句可以单行或多行书写,以分号结尾;
- 可以用空格和缩进来来增强语句的可读性;
- 关键字不区别大小写,建议使用大写;
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等;
- DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据);
- DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别;
- DQL(Data Query Language):数据查询语言,用来查询记录(数据)
查看所有数据库:show databases;
切换数据库:use mydb1,切换到 mydb1 数据库;
- 创建数据库:CREATE DATABASE [IF NOT EXISTS] mydb1;
- 删除数据库:DROP DATABASE [IF EXISTS] mydb1;
例如:,删除名为 mydb1 的数据库。如果这个数据库不存在,那么会报错。DROP DATABASE IF EXISTS mydb1,就算 mydb1不存在,也不会的报错。
- 修改数据库编码:ALTER DATABASE mydb1 CHARACTER SET utf8
MySQL 与 Java、C 一样,也有数据类型MySQL 中数据类型主要应用在列上。
常用类型:
- int:整型
- double:浮点型,例如 double(5,2)表示最多 5 位,其中必须有 2 位小数,即最大值为 999.99;
- decimal:泛型型,在表单线方面使用该类型,因为不会出现精度缺失问题;
- char:固定长度字符串类型;(当输入的字符不够长度时会补空格)
- varchar:固定长度字符串类型;
- text:字符串类型;
- blob:字节类型;
- date:日期类型,格式为:yyyy-MM-dd;
- time:时间类型,格式为:hh:mm:ss
- timestamp:时间戳类型;
创建表
例如,创建stu表
查看表的结构
DESC 表名;
删除表
DROP TABLE 表名;
修改表
- 添加列:给 stu 表添加 classname 列
- 修改列的数据类型:修改 stu 表的 gender 列类型为 CHAR(2)
- 修改列名:修改 stu 表的 gender 列名为 sex
- 删除列:删除 stu 表的 classname 列
- 修改表名称:修改 stu 表名称为 student
语法 1:
语法 2:
因为没有指定要插入的列,表示按创建表时列的顺序插入所有列的值:
注意:所有字符串数据必须使用单引用!
语法:
语法 1:
语法 2:
TRUNCATE TABLE 表名;
两者之间的区别:
虽然 TRUNCATE 和 DELETE 都可以删除表的所有记录,但有原理不同。DELETE的效率没有 TRUNCATE 高!
TRUNCATE 其实属性 DDL 语句,因为它是先 DROP TABLE,再 CREATE TABLE。
而且TRUNCATE删除的记录是无法回滚的,但DELETE删除的记录是可以回滚的(回滚是事务的知识!)。
语法:
语法:
语法:
语法:
语法:
语法 :
数据库执行 DQL 语句不会对数据进行改变,而是让数据库发送结果集给客户端。
语法:
select 列名 ----> 要查询的列名称
from 表名 ----> 要查询的表名称
where 条件 ----> 行条件
group by 分组列 ----> 对结果分组
having 分组条件 ----> 分组后的行条件
order by 排序列 ----> 对结果分组
limit 起始行, 行数 ----> 结果限定
☆学生表:stu:


☆雇员表:emp

☆部门表:dept

查询所有列
(* :通配符,表示所有列)
查询指定列
条件查询介绍
条件查询就是在查询时给出 WHERE 子句,在 WHERE 子句中可以使用如下运算符及关键字:
- =、!=、<>、<、<=、>、>=;
- BETWEEN…AND;
- IN(set);
- IS NULL;
- AND;
- OR;
- NOT;
举例说明
查询性别为女,并且年龄小于 50 的记录
查询学号为 S_1001,或者姓名为 liSi 的记录
查询学号为 S_1001,S_1002,S_1003 的记录
查询学号不是 S_1001,S_1002,S_1003 的记录
查询年龄为 null 的记录
查询年龄在 20 到 40 之间的学生记录
或者
查询性别非男的学生记录
或者
或者
查询姓名不为 null 的学生记录
或者
- :表示任意 0 个或多个字符。可匹配任意类型和长度的字符,有些情
况下若是中文,请使用两个百分号(%%)表示。 - : 表示任意单个字符。匹配单个任意字符,它常用来限制表达式的字 符长度语句。
举例说明
查询姓名由 5 个字母构成的学生记录
查询姓名由 5 个字母构成,并且第 5 个字母为“i”的学生记录
查询姓名以“z”开头的学生记录
其中“%”匹配 0~n 个任何字母。
查询姓名中第 2 个字母为“i”的学生记录
去掉重复记录
去除重复记录(两行或两行以上记录中系列的上的数据都相同),例如 emp 表中 sal 字段就存在相同的记录。当只查询 emp 表的 sal 字段时,那么会出现重复记录,那么想去除重复记录,需要使用 DISTINCT:
查看雇员的月薪与佣金之和
因为 sal 和 comm 两列的类型都是数值类型,所以可以做加运算。如果 sal 或 comm 中有一个字段不是数值类型,那么会出错。
comm 列有很多记录的值为 NULL,因为任何东西与 NULL 相加结果还是 NULL,所以结算结果可能会出现 NULL。下面使用了把 NULL 转换成数值 0 的函数 IFNULL:
给列名添加别名
在上面查询中出现列名为 sal+IFNULL(comm,0),这很不美观,现在我们给这一列给出一个别名,为 total:
给列起别名时,是可以省略 AS 关键字的:
查询所有学生记录,按年龄升序排序
或者
查询所有学生记录,按年龄降序排序
查询所有雇员,按月薪降序排序,如果月薪相同时,按编号升序排序
聚合函数是用来做纵向运算的函数:
- COUNT():统计指定列不为 NULL 的记录行数;
- MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
- MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
- SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为 0;
- AVG():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为 0;
COUNT:当需要纵向统计时可以使用 COUNT()。
查询 emp 表中有佣金的人数:
注意,因为 count()函数中给出的是 comm 列,那么只统计 comm 列非 NULL 的行数。
统计月薪与佣金之和大于 2500 元的人数:
查询有佣金的人数,以及有领导的人数:
SUM 和 AVG:当需要纵向求和时使用 sum()函数。
统计所有员工平均工资:
或者
MAX 和 MIN
查询最高工资和最低工资:
分组查询
当需要分组查询时需要使用 子句,例如查询每个部门的工资和,这说明要使用部分来分组。
查询每个部门的部门编号和每个部门的工资和:
查询每个部门的部门编号以及每个部门的人数:
查询每个部门的部门编号以及每个部门工资大于 1500 的人数:
HAVING 子句
查询工资总和大于 9000 的部门编号以及工资和:
注意,WHERE 是对分组前记录的条件,如果某行记录没有满足 WHERE 子句的条件,那
么这行记录不会参加分组;而 HAVING 是对分组后数据的约束。
查询 5 行记录,起始行从 0 开始
注意,起始行从 0 开始,即第一行开始!
分页查询
如果一页记录为 10 条,希望查看第 3 页记录应该怎么查呢?
第一页记录起始行为 0,一共查询 10 行;
第二页记录起始行为 10,一共查询 10 行;
第三页记录起始行为 20,一共查询 10 行;
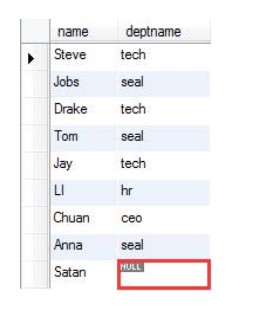
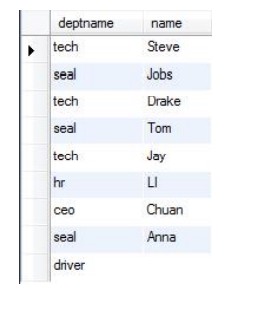
他们之间最主要的区别:内连接仅选出两张表中互相匹配的记录,外连接会选出其他不匹配的记录。
例如: 以下是员工表 staff 和职位表 deptno:
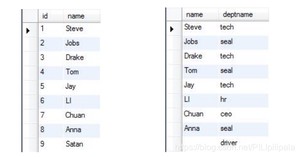
内连接
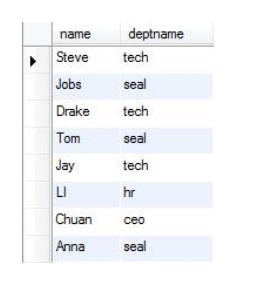
外连接分为左连接和右连接
外连接(左连接):
外连接(右连接):
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/8145.html