
昨天小编看到了一部不错的小说,但是没有办法下载,只能一页一页地看,于是想到了爬虫,现在Java也有了爬虫的框架,很简单,就算小白也能轻易入门,话不多说,直接上手。
1.首先引入相关依赖
不会maven的话可以按照右边直接去maven库下载添加jar包,注意不要少包,否则会报找不到类
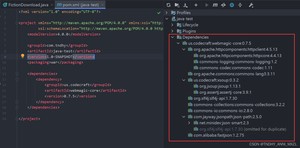
依赖示例代码:
2.新建类,实现 PageProcessor 接口,重写两个方法
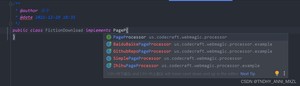
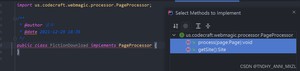
3.设置爬取文件配置属性,在 getSite 方法返回
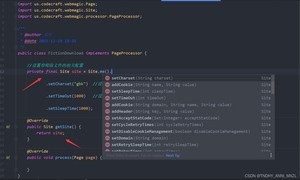
site对象的方法是方法链,可以连着设置很多属性,具体说几个重要的
4.添加main方法
当 Spider.create(...)...run()执行的时候,重写的 process() 方法就会执行
5.添加持久化属性和方法
这个就不多说,两个属性一个是爬取网页保存的书名,一个是数据,方法是用来保存持久化数据的
6.分析爬取网站的属性,F12打开网页元素控制台,有些浏览器按键可能不同
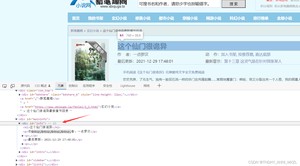
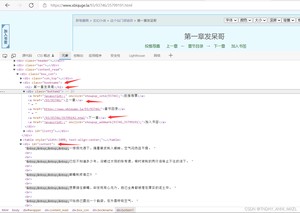 记住这些需要的元素标签和 id 或 class ,我们要获取他们的内容或属性
记住这些需要的元素标签和 id 或 class ,我们要获取他们的内容或属性
7.编写 process 方法,获取具体的数据
html.xpath()可以获取页面的属性或内容
html.xpath("[@id='content']").all()获取id为content的所有内容,包括下面的子标签html.xpath("[@class='bookname']/h1/text()")获取class为bookname的标签下h1标签下的文本html.xpath("[@class='bottem1']/a[4]/@href")获取class为bottem1的下第四个a标签下的href属性
page.addTargetRequest(url);//添加单条待爬虫队列
注:爬取网站我看了一下,最后一章再点下一页是退回小说章节目录,所有我加了一个判断,如果当前页面是章节目录,就说明最后一章结束,执行自定义方法保存数据,如果不是,则获取下一页链接,添加到爬取队列。
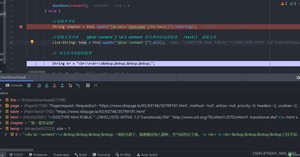
8.测试
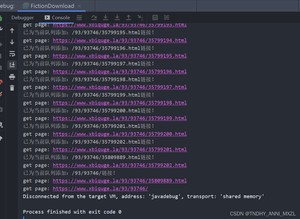
9.爬取成功 ,附上所有代码
10.创作不易,装载请注明出处。如果此文章对您有帮助,麻烦点个赞,收藏加关注,谢谢!
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/7971.html