
活动地址:CSDN21天学习挑战赛
1、基本功能
*Scrapy*是一个适用爬取网站数据、提取结构性数据的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
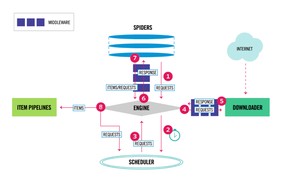
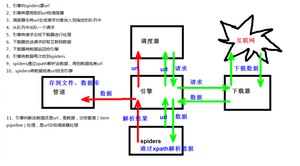
2、架构
- *Scrapy Engine(引擎)*:负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- *Scheduler(调度器)*:它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- *Downloader(下载器)*:负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
- *Spider(爬虫)*:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- *Item Pipeline(管道)*:它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- *Downloader Middlewares(下载中间件)*:一个可以自定义扩展下载功能的组件。
- *Spider Middlewares(Spider中间件)*:一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
3、scrapy项目的结构
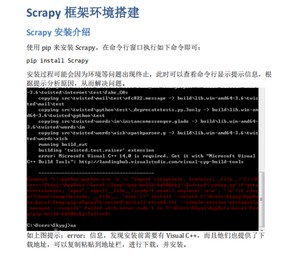
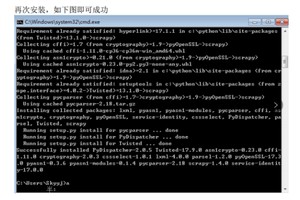
1、新建项目 :新建一个新的爬虫项目
2、明确目标 (items.py):明确你想要抓取的目标
3、制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
创建爬虫文件
爬虫文件的解释:
response的属性和方法
- response.text
获取的是响应的字符串 - response.body
获取的是二进制数据 - response.xpath
可以直接使用xpath方法来解析response中的内容 - response.extract()
提取seletor对象的data属性值 - response.extract_first()
提取的seletor列表的第一个数据
4、存储内容 (pipelines.py):设计管道存储爬取内容
如果想使用管道的话 那么就必须在settings中开启管道
然后去pippelines.py中设计管道:
方法一:
方法二:(推荐)
5、运行爬虫
- 打开cmd,创建项目
scrapy startproject scrapy_dangdang
- 创建爬虫文件
先到spiders文件下 :
cd scrapy_dangdangscrapy_dangdangspiders
然后创建爬虫文件 :
scrapy genspider dang category.dangdang.com
- 项目目录
- 确定需要下载的数据,去items.py文件中添加。这里我们准备存储图片、名字和价格
- 接下来我们就可以去爬虫文件中去爬取我们需要的内容了(这里是在dang.py文件中)
- 通过解析拿到数据之后,我们就可以去通道中添加保存的方法了(pippelines.py)
- 首先我们要去settings.py在打开通道和添加通道,完成之后进行下一步
- 通道打开后,在pippelines.py完成下列操作
- 最后在cmd中输入:scrapy crawl dang
- 完成之后就开始下载了,全部完成之后你就会看到多了book.json文件和books文件夹在自己的项目中。里面有数据,则表示项目成功了。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/7916.html