
交叉验证是一种在机器学习中广泛应用的评估技术,主要用于评估模型的泛化能力和性能。 交叉验证(Cross-validation)是一种将数据集分割成多个小部分,然后多次对模型进行训练和验证的过程。通过多次进行这个过程,可以评估模型的泛化性能和稳定性。
注:上面所说的"模型的泛化能力"、"模型的稳定性"可能对一些读者来说比较难理解。
(1)"模型的泛化能力":机器学习的“泛化”能力是指机器学习算法对"新鲜样本"的适应能力。这种能力使得机器学习模型在面对新数据时,能够更好地适应并做出准确的预测。
(2)"模型的稳定性":是指模型对于输入数据的变化的响应程度。如果模型对于不同的输入数据变化能够产生相对一致的输出结果,那么这个模型就被认为是稳定的。
如果对"泛化"和"稳定性"这两个概念还不太了解,也没有关系,其实不影响对下面内容的阅读和理解
下面介绍2种常见的交叉验证方法:
(1)留出交叉验证(Leave-one-out cross-validation): 每次选择一个样本作为测试集,剩下的样本作为训练集,然后进行模型训练和测试。在所有样本都被选作测试集之后,可以计算出模型的平均性能指标。
(2)k折交叉验证(k-fold cross-validation): 将数据集分成k个子集,每次选择k-1个子集作为训练集,剩下的一个子集作为验证集。这种方法的好处是可以在较短的时间内完成验证,适用于大规模数据集。
下面将以一个简单的例子讲解上面这三种交叉验证的方法。
我们的数据来源于英雄联盟S12。result指的是比赛的胜负,FAC1指的是队伍在比赛中的技战术指标。我们要用这6个FAC1来预测比赛的胜负result。
样本一共有10个,样本的序号我们设为0-1-2-3-4-5-6-7-8-9
3.1 进行留出交叉验证法
用上面的10个样本数据做机器学习的模型。在这种情况下,要进行10次的模型训练和测试。 下面的数字代表的样本序号(0-9)。
第01次: 训练集为0-1-2-3-4-5-6-7-8 测试集为9
第02次: 训练集为1-2-3-4-5-6-7-8-9 测试集为0
第03次: 训练集为2-3-4-5-6-7-8-9-0 测试集为1
第04次: 训练集为3-4-5-6-7-8-9-0-1 测试集为2
第05次: 训练集为4-5-6-7-8-9-0-1-2 测试集为3
第06次: 训练集为5-6-7-8-9-0-1-2-3 测试集为4
第07次: 训练集为6-7-8-9-0-1-2-3-4 测试集为5
第08次: 训练集为7-8-9-0-1-2-3-4-5 测试集为6
第09次: 训练集为8-9-0-1-2-3-4-5-6 测试集为7
第10次: 训练集为9-0-1-2-3-4-5-6-7 测试集为8
3.2 k折交叉验证法(shuffle=False)
用上面的10个样本数据做机器学习的模型。在这种情况下,要进行k次的模型训练和测试。而k是我们自己设定的,在这里我们设定为5(即下面代码的n_splits=5)。
kf = KFold(n_splits=5, shuffle=False) -- 这是一段进行k折交叉验证中的python代码
shuffle=False即"数据分成5份"时是不是随机分的,而是按照原有的样本序号分的; "shuffle"的英文意思是"洗牌; 洗(牌); 拖着脚走; 坐立不安; 把(纸张等)变换位置,打乱次序"
k折交叉验证法(shuffle=False)实现的效果如下:
第01次: 训练集为0-1-2-3-4-5-6-7 测试集为8-9
第02次: 训练集为2-3-4-5-6-7-8-9 测试集为0-1
第03次: 训练集为4-5-6-7-8-9-0-1 测试集为2-3
第04次: 训练集为6-7-8-9-0-1-2-3 测试集为4-5
第05次: 训练集为8-9-0-1-2-3-4-5 测试集为6-7
注:上面的数字代表的样本序号(0-9)。
3.3 k折交叉验证法(shuffle=True)
用上面的10个样本数据做机器学习的模型。在这种情况下,要进行k次的模型训练和测试。而k是我们自己设定的,在这里我们设定为5(即下面代码的n_splits=5)。
kf = KFold(n_splits=5, shuffle=True) -- 这是一段进行k折交叉验证中的python代码
shuffle=True即"数据分成5份"时是随机分的; "shuffle"的英文意思是"洗牌; 洗(牌); 拖着脚走; 坐立不安; 把(纸张等)变换位置,打乱次序"
k折交叉验证法(shuffle=True)实现的效果如下:
第01次: 训练集为0-1-3-4-5-6-7-8 测试集为2-9
第02次: 训练集为1-2-3-5-6-7-8-9 测试集为0-4
第03次: 训练集为0-1-2-4-6-7-8-9 测试集为3-5
第04次: 训练集为0-2-3-4-5-7-8-9 测试集为1-6
第05次: 训练集为0-1-2-3-4-5-6-9 测试集为7-8
注:上面的数字代表的样本序号(0-9)。
01 导入库
>引入库函数
>导入进行模型训练与测试前的进行数据处理的库
>导入逻辑回归模型的库(linear_model字面理解是线性模型的意思)
>导入“集成学习”的库(集成学习(ensemble learning),并不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器(基学习器,Base learner)来完成学习任务。)
>导入含机器学习评价函数的库
>导入含混淆矩阵的库
>导入机器学习的评价指标准确率、精确率、召回率、F1值
>导入做ROC曲线的库
>导入作图的库
02 获取数据源并整理数据
(数据集可在此获取:机器学习交叉验证教程 - 飞桨AI Studio星河社区 (baidu.com))
运行结果:

>查看前几行数据
数据解释:result是胜负结果;FAC1_1等是通过主成分分析后得到的技战术指标
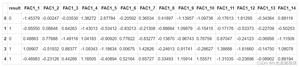
>使用loc函数进行数据获取
运行结果:
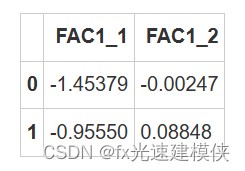
>使用iloc函数进行数据获取
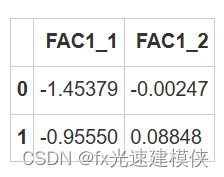
03 对数据集进行7次“训练”和“测试”
> 使用KFold设定交叉验证的参数
(n_splits=7即把数据分成7份,也是要进行7次的"训练"和"测试"; shuffle=True即"数据分成7份"时是随机分的;random=40,按正常的理解,应该是"random_state=40指定随机数生成器的种子")
>创建一个全是1的7×5的矩阵
>用i来表明是第几次的交叉验证;从0开始计数
>使用kf.split( )这个函数进行数据的划分
(在每一次循环的"train_index"、"test_index"都是不一样的 ; "train_index"指的是第i次训练和测试时的训练集数据的行索引; "train_index"指的是第i次训练和测试时的测试集数据的行索引)
运行结果:
- 第1次:

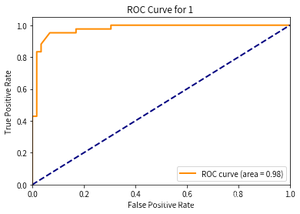
- 第2次:

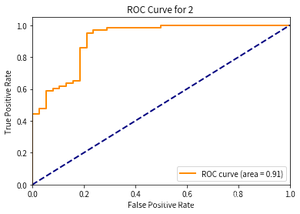
- 第3次:

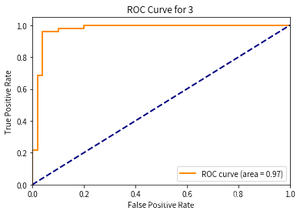
- 第4次:

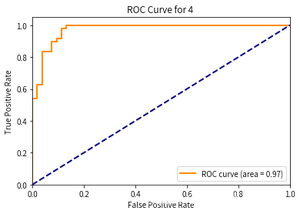
- 第5次:

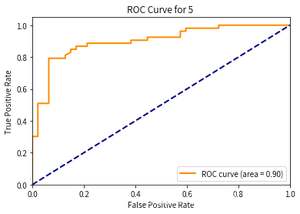
- 第6次:

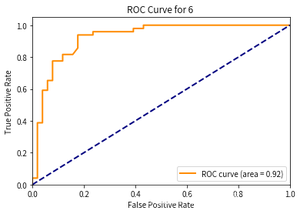
- 第7次:

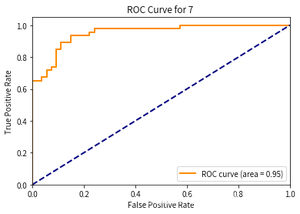
以上就是今天为大家整理的机器学习的代码教程(详解版)啦,希望对你有所帮助
欢迎转载、收藏、如果有所收获可以点赞支持一下~
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/7646.html