
它用于在查询结果中执行聚合操作,而不会影响查询的分组行数,同时在每个分组内进行计数。
- COUNT(): 这表示要计算在窗口内的行数, 代表计算所有行。
- OVER: 这引入了窗口函数的定义,它告诉数据库引擎在什么样的窗口内执行计数。
- (PARTITION BY …): 这部分定义了窗口的分区方式,即如何将数据划分为不同的分组。PARTITION BY
子句指定一个或多个列,根据这些列的值将数据划分为不同的窗口。
编写一个 SQL 语句,将某个员工与具有相同许可证的所有其他员工进行匹配。
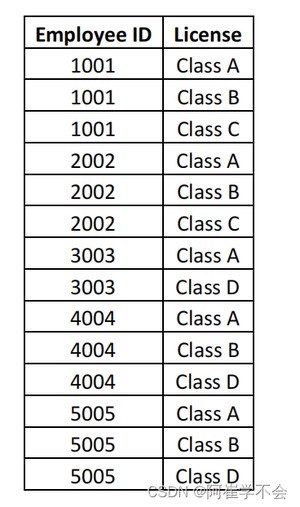
输出的结果为:
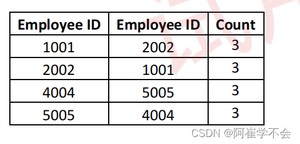
- 员工 ID 1001 和 2002 将在预期输出中,因为它们都带有 A 类、B 类和C 类许可证。
- 员工 ID 4004 和 5005 将在预期输出中,因为它们都带有 A 类、B 类和 D类许可证。
- 尽管员工 ID 3003 与员工 ID 4004 和 5005 具有相同的许可证,但这些员工 ID没有与 3003 相同的许可证。
如果直接用自己关联(#Employees A inner join #Employees B
on A.License=B.License and A.EmployeeID<>B.EmployeeID
group by A.EmployeeID,B.EmployeeID)就是只计算匹配上的个数,没有都匹配上,且没匹配总数量,那要怎么既单个都匹配上且总数也对的上呢?有什么函数是可以显示单个和总数的之间的关系?
就要用到COUNT(*) OVER (PARTITION BY …)窗口函数
每行都显示出匹配上的总数,这样就不用再group by算一遍总数再匹配,省了很多的时间。
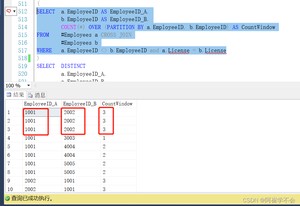
COUNT(*) OVER (PARTITION BY …)显示了分组后的每行数据与总的数据的关系,利用这个关系,可以匹配上总数一致。
COUNT(*) OVER (PARTITION BY …) 通常应用于窗口函数中,用于分析和报告需要在结果集中的每行上执行聚合操作的场景。以下是一些常见的应用场景:
- 计算每组的行数:窗口函数允许你在结果集中的每一行上计算分组内的行数,而不需要使用 GROUP BY子句。这对于需要在保持所有行的情况下查看每个分组的大小的情况非常有用。
- 计算累积和或平均值:你可以使用窗口函数来计算每一行的累积和、平均值或其他聚合指标,而不必创建中间结果或更改结果集的结构。
- 识别排名和百分比:窗口函数允许你为每一行计算排名或百分比,例如,找出每个销售员的销售额在总销售额中的百分比。
- 查找首次出现或最后出现的事件:你可以使用窗口函数来确定每组内首次或最后一次出现某个事件的时间戳或行。
- 分析前后行:你可以使用窗口函数来分析前一行和后一行的数据,例如,计算每个时间点的收益与前一个时间点的差异。
- 分组内数据分布分析:窗口函数可用于查找每组内数据的分布情况,如查找每组内的最大、最小值,或者计算分位数。
- 复杂的累积计算:在某些情况下,你可能需要执行复杂的累积计算,包括多次计算和分组。窗口函数可以帮助你处理这些需求,而不必使用复杂的子查询或连接。
总之,窗口函数允许你在结果集的每一行上执行聚合操作,而不会减少结果集的行数,从而提供了更灵活和强大的数据分析工具。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/6698.html