
我用python开发了一个爬虫采集软件,可自动按关键词抓取小红书笔记数据。
为什么有了源码还开发界面软件呢?方便不懂编程代码的小白用户使用,无需安装python,无需改代码,双击打开即用!
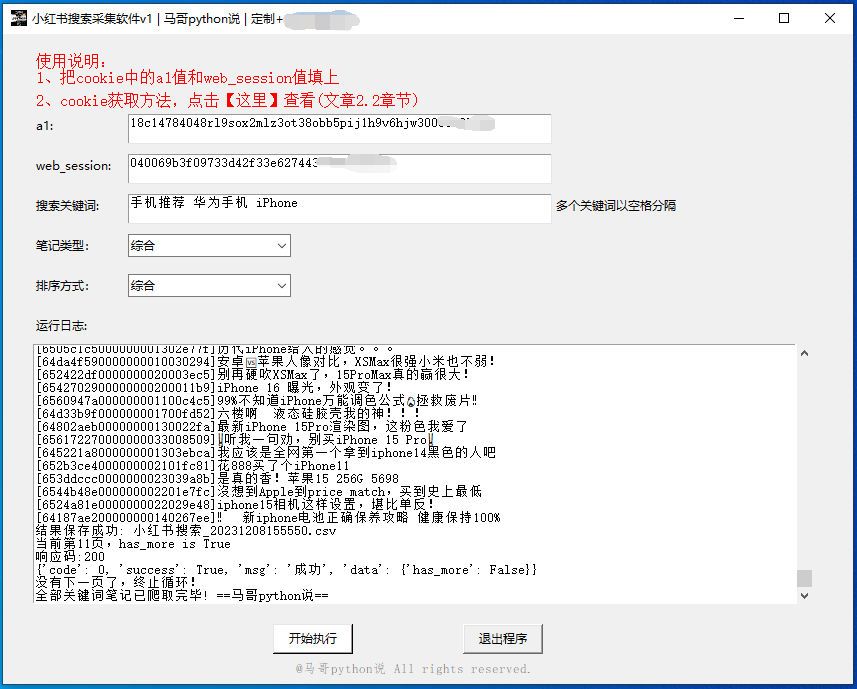
软件界面截图:
爬取结果截图:

1.2 演示视频
【软件演示】爬小红书关键词搜索软件
1.3 软件亮点说明
几点重要说明: 以上。
以上。
二、代码讲解
2.1 爬虫核心模块
为了提升代码的复用性和可维护性,我们将爬虫的核心功能封装成了独立的class类,并通过tkinter框架进行界面调用。具体的爬虫实现逻辑,可查阅原文档获取详细解析。
2.2 图形用户界面设计
tkinter框架应用:软件界面采用流行的tkinter库进行开发,确保了跨平台的兼容性和良好的用户体验。
主窗口布局:主窗口设置了合理的尺寸(850x650像素),并包含了必要的日志目录创建逻辑,以确保日志文件的顺利生成。
输入控件:
Cookie输入:用户可在此区域输入个人Cookie信息,以便软件能够成功登录并采集数据。
笔记链接填写:提供文本输入框,允许用户粘贴需要采集评论的笔记链接。
版权信息展示:在界面底部,我们添加了版权说明,以尊重和保护软件的知识产权。
2.3 日志记录与管理
日志系统的重要性:高效的日志功能对于软件的问题排查和bug修复至关重要。
核心代码实现:
利用logging模块,我们设置了详细的日志格式和级别,确保日志信息的全面性和可读性。
采用了TimedRotatingFileHandler,实现了日志文件的按天滚动生成和自动备份,有效管理了日志文件的存储空间。

·
完整讲解、想你所想:
https://www.bilibili.com/read/cv
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/503.html