
这里举两个例子:
- 机器翻译:把一种语言翻译成另一种语言
- 语音识别:把一段语音识别出来,用文字表示
两个例子都有一个共同的特点,就是输入一段序列,然后输出也是一段序列,即Sequence-to-sequence。
所谓的Sequence2Sequence任务主要是泛指一些Sequence到Sequence的映射问题,Sequence在这里可以理解为一个字符串序列,当我们在给定一个字符串序列后,希望得到与之对应的另一个字符串序列(如 翻译后的、如语义上对应的)时,这个任务就可以称为Sequence2Sequence了。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
Seq2seq的本质还是encoder-decoder结构,Encoder-Decoder的一个显著特征就是:它是一个end-to-end的学习算法。只要符合这种框架结构的模型都可以统称为Encoder-Decoder模型。
Seq2Seq可以看作是Encoder-Decoder针对某一类任务的模型框架,它们的范围关系如下所示:
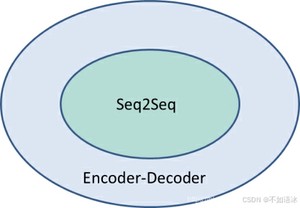
Encoder-Decoder强调的是模型设计(编码-解码的一个过程),Seq2Seq强调的是任务类型(序列到序列的问题)。
所以Seq2seq模型由三个部分组成:编码器、中间状态向量和解码器。其中中间状态向量是编码器的输出,也是解码器的输入,如何设置中间状态向量也是学习研究的重点之一。
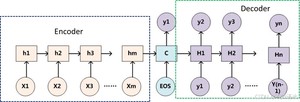
不论输入和输出的长度是什么,中间的“向量c”长度都是固定的(这是它的缺陷所在)。
信息丢失的问题
通过上文可以知道编码器和解码器之间有一个共享的向量(上图中的向量c),来传递信息,而且它的长度是固定的。这会产生一个信息丢失的问题,也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息,那么解码的准确度自然也就要打个折扣了。如果编码过程产生的不是一个固定长度的向量而是一系列向量,是不是会保留更多的信息呢。
便于理解,我们把“编码-解码”的过程类比为“压缩-解压”的过程:将一张 800X800 像素的图片压缩成 100KB,看上去还比较清晰。而将一张 3000X3000 像素的图片也压缩到 100KB,看上去就模糊了。
seq2seq是一个解决具体任务的框架,根据不同的任务可以选择不同的编码器和解码器(例如,CNN、RNN、LSTM、GRU等)。只是在处理序列任务时,一般选用RNN系列模型作为seq2seq的组件,即encoder和decoder的实现模型。
编码器和解码器分别对应输入序列和输出序列的两个循环神经网络。通常会在输入序列和输出序列后面分别附上一个特殊字符 '<eos>'(end of sequence)表示序列的终止。在测试模型时,一旦输出 '<eos>' 就终止当前的输出序列
在Seq2Seq结构中,编码器Encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由解码器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个时刻t-1的输出作为后一个时刻t的输入,循环解码,直到输出停止符为止。
为什么LSTM等也可以输入输出不等长,为什么还需要seq2seq?
编码器
编码器的作用是把一个不定长的输入序列转化成一个定长的背景词向量c0。该背景词向量包含了输入序列的信息。常用的编码器是循环神经网络。
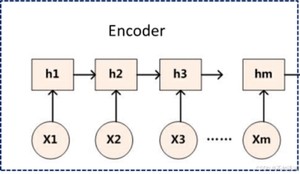
如上图所示,编码器就是一个RNN模型,它的输入同RNN系列模型一致,需要设置输入特征维度,隐藏层维度,隐藏网络层数。这里不需要额外关注输出层的维度设置,因为编码器输出即中间状态向量是由编码器的隐状态向量决定的。
中间状态向量
从图中可以看到,最简单的中间状态向量即是编码器的最后一个隐藏状态向量,后续文章继续介绍如何进行优化以及引入attention。
解码器
解码器和单纯的RNN系列模型相比有些变化,主要体现在输入的选择上,而且在训练和预测时也有不同之处。
一般来说,解码器的输入有以下三种结构:
(1)中间状态向量作为最初输入,后面每一个隐状态的输入都是前一个隐状态,如下图。
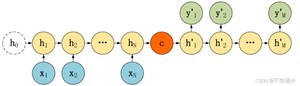
(2)每一个隐状态的输入都是前一个隐状态和中间状态向量,需要手动设置一个初始隐状态,如下图。
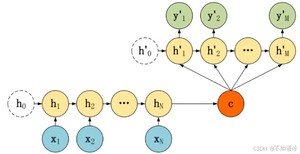
(3)每一个隐状态的输入都是前一个隐状态和前一个输出向量以及中间状态向量,需要手动设置一个初始隐状态,如下图。
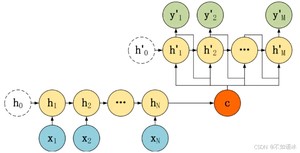
在模型训练和预测时,如果输入是有前一个输出向量的,预测时可以直接使用前一个预测出来的输出值,但是训练时一般使用的是真实文本的输出向量,不然一旦预测错误一个输出值,后面的也都将会受到影响,所谓一步错,步步错。而使用真实的文本向量,则可以进行纠正,也叫做teacher forcing。这种操作的目的就是为了使得训练过程更容易。但弊端就是预测时没有teacher纠正了,只依靠前面预测输出很容易出现错误。
所以训练时更常用的办法,是部分使用真实文本向量,部分使用模型预测的输出向量。即设置一个概率p,每一步,以概率p靠模型上一步的输出作为输入来预测,以概率1-p根据真实文本的输入向量来预测,这种方法称为「计划采样」(scheduled sampling)
https://blog.csdn.net/xziyuan/article/details/
Cho et al., Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Sutskever et al., Sequence to Sequence Leaerning with Neural Networks
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/4927.html