
所有的集合类和集合接口都在java.util包下。
在内存中申请一块空间用来存储数据,在Java中集合就是替换掉定长的数组的一种引用数据类型。
长度区别
数组长度固定,定义长了造成内存空间的浪费,定义短了不够用。
集合大小可以变,用多少空间拿多少空间。
内容区别
数组可以存储基本数据类型和引用数据类型
集合中能存储引用数据类型(存储的为对象的内存地址)
list.add(100);//为自动装箱,100为Integer包装的
元素区别
数组中只能存储同一种类型成员
集合中可以存储不同类型数据(一般情况下也只存储同一种类型的数据)
集合结构
在java中每一个不同的集合,底层会对应不同的数据结构。往不同的集合中
存储元素,等于将数据放到了不同的数据结构当中。什么是数据结构?数据存储的
结构就是数据结构。不同的数据结构,数据存储方式不同。
- 单列集合 Collection
- List可以重复:ArrayList/LinkedList
- Set不可重复:HashSet/TreeSet
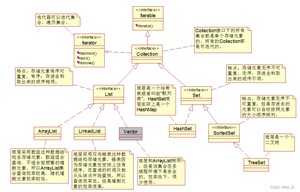
(大量文字插入会导致图片不清,所以在此进行更详细的描述)
- List特点:此处顺序并不是大小顺序,而是存入数据的先后顺序。有序因为List集合都有下标,下标从0开始,以递增。
- Set特点:取出顺序不一定为存入顺序,另外Set集合没有下标。
- ArrayList是非线程安全的。
- HashSet集合在new的时候,底层实际上new了一个HashMap集合。向HashSet集合中存储元素,实际上是存储到了HashMap的key中了。HashMap集合是一个Hash表数据结构。
- SortedSet集合存储元素的特点:由于继承了Set集合,所以他的特点也是无序不可重复,但是放在SortedSet集合中的元素可以自动排序。放到该集合中的元素是自动按照大小顺序排序的。
- TreeSet集合底层实际上是TreeMap。TreeSet集合在new的时候,底层实际上new了一个TreeMap集合。向TreeSet集合中存储元素,实际上是存储到了TreeMap的key中了。TreeMap集合是一个二叉树数据结构。
- 双列集合Map:HashMap/TreeMap
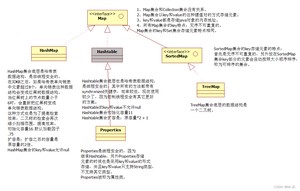
粗体是接口 斜体是实现类
单列集合的顶层接口,既然是接口就不能直接使用,需要通过实现类!~
以下迭代方式,是所有Collection通用的一种方式。在Map集合中不能使用,在所有的Collection以及子类中使用。
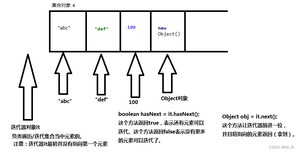
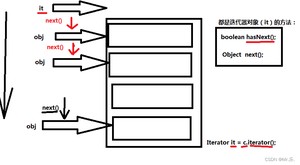
- ArrayList是一个List接口的实现类,底层使用的是一个可以调整大小的数组实现的。
- :是一种特殊的数据类型(引用数据类型) -- 泛型
- ArrayList<String> 或者 ArrayList<Integer> 或者 ArrayList<Student>
底层代码:
属性:
DEFAULT_CAPACITY = 10 默认长度,初始化容量为10 Object[] EMPTY_ELEMENTDATA = {} //有参构造所创建 Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {} //无参构造所创建的 Object[] elementData;底层为Object类型的数组,存储的元素都在此。 int size 实际存放的个数
构造方法 :
add方法源码:(jdk1.8与之不同,此处为jdk16)
ArrayList集合底层是数组,怎么优化? 尽可能少的扩容。因为数组扩容效率比较低,建议在使用ArrayList集合 的时候预估计元素的个数,给定一个初始化容量。 数组优点: 检索效率比较高。(每个元素占用空间大小相同,内存地址是连续的,知道首元素内存地址, 然后知道下标,通过数学表达式计算出元素的内存地址,所以检索效率最高。) 数组缺点: 随机增删元素效率比较低。 另外数组无法存储大数据量。(很难找到一块非常巨大的连续的内存空间。) 向数组末尾添加元素,效率很高,不受影响。
底层代码
属性:
add方法源码:(jdk1.8与之不同,此处为jdk16)
LinkedList和ArrayList方法一样,只是底层实现不一样。ArrayList底层为数组存储,LinkedList是以双向链表存储。LinkedList集合没有初始化容量。最初这个链表中没有任何元素。first和last引用都是null。
链表的优点: 由于链表上的元素在空间存储上内存地址不连续。 所以随机增删元素的时候不会有大量元素位移,因此随机增删效率较高。 在以后的开发中,如果遇到随机增删集合中元素的业务比较多时,建议 使用LinkedList。 链表的缺点: 不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头 节点开始遍历,直到找到为止。所以LinkedList集合检索/查找的效率 较低。 ArrayList:把检索发挥到极致。(末尾添加元素效率还是很高的。) LinkedList:把随机增删发挥到极致。 加元素都是往末尾添加,所以ArrayList用的比LinkedList多。
1、底层也是一个数组。 2、初始化容量:10 3、怎么扩容的? 扩容之后是原容量的2倍。 10--> 20 --> 40 --> 80 4、Vector中所有的方法都是线程同步的,都带有synchronized关键字, 是线程安全的。效率比较低,使用较少了。 5、怎么将一个线程不安全的ArrayList集合转换成线程安全的呢? 使用集合工具类: java.util.Collections; java.util.Collection 是集合接口。 java.util.Collections 是集合工具类。 Collections.synchronizedList();//将及格转换为线程安全的。
- Set集合也是一个接口,继承自Collection,与List类似,都需要通过实现类来进行操作。
- 特点
- 不允许包含重复的值
- 没有索引(就不能使用普通的for循环进行遍历)
例:双色球
Set集合的去重原理使用的是哈希值。
哈希值就是JDK根据对象地址 或者 字符串 或者数值 通过自己内部的计算出来的一个整数类型数据
- 用来获取哈希值,来自于Object顶层类
- 对象的哈希值特点
- 同一个对象多次调用方法,得到的结果是相同的。
- 默认情况下,不同的对象的哈希值也是不同的(特殊情况除外)
- HashSet集合的特点
- 底层结构是“哈希表”
- 集合对于读写顺序不做保证
- 没有索引
- Set集合中的内容不能重复
- 特点
- LinkedHashSet是哈希表和链表实现的Set接口,具有可预测的读写顺序。
- 有链表来保证元素有序
- 有哈希表来保证元素的唯一性
1、TreeSet集合底层实际上是一个TreeMap
2、TreeMap集合底层是一个二叉树。
3、放到TreeSet集合中的元素,等同于放到TreeMap集合key部分了。
4、TreeSet集合中的元素:无序不可重复,但是可以按照元素的大小顺序自动排序。
5.5.1 -自定义排序规则
对于自定义的类无法排序,因为类中对象之间没有比较规则,不知道谁大谁小。
匿名内部类方式
Comparable和Comparator怎么选择呢? 当比较规则不会发生改变的时候,或者说当比较规则只有1个的时候,建议实现Comparable接口。 如果比较规则有多个,并且需要多个比较规则之间频繁切换,建议使用Comparator接口。
双列集合:用来存储键值对的集合。
- : K(key)键 ,V(value)值
- 将键映射到值的对象,不能出现重复的键,每个键最多可以映射到一个值
1、Map和Collection没有继承关系。 2、Map集合以key和value的方式存储数据:键值对 key和value都是引用数据类型。 key和value都是存储对象的内存地址。 key起到主导的地位,value是key的一个附属品。
例子:
通过 数组 + 链表 实现的一种数据结构
哈希表的构造方法的参数是一个长度为16个元素的数组,通过哈希值 % 16 的值,作为头节点在数组中选择对应的位置,就形成了哈希表。
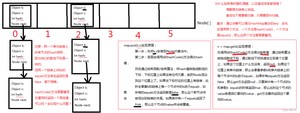 注:图转自动力节点。
注:图转自动力节点。
6.5.1 -底层源码
6.5.2 -特点
1、无序,不可重复。 为什么无序? 因为不一定挂到哪个单向链表上。 不可重复是怎么保证的? equals方法来保证HashMap集合的key不可重复。 如果key重复了,value会覆盖。 2、放在HashMap集合key部分的元素其实就是放到HashSet集合中了。 所以HashSet集合中的元素也需要同时重写hashCode()+equals()方法。3、HashMap集合的默认初始化容量是16,默认加载因子是0.75 这个默认加载因子是当HashMap集合底层数组的容量达到75%的时候,数组以二叉树开始扩容。 重点,记住:HashMap集合初始化容量必须是2的倍数,这也是官方推荐的, 这是因为达到散列均匀,为了提高HashMap集合的存取效率,所必须的。
6.5.3 -注意
1.向Map集合中存,以及从Map集合中取,都是先调用key的hashCode方法,然后再调用equals方法!
equals方法有可能调用,也有可能不调用。
拿put(k,v)举例,什么时候equals不会调用? k.hashCode()方法返回哈希值, 哈希值经过哈希算法转换成数组下标。 数组下标位置上如果是null,equals不需要执行。 拿get(k)举例,什么时候equals不会调用? k.hashCode()方法返回哈希值, 哈希值经过哈希算法转换成数组下标。 数组下标位置上如果是null,equals不需要执行。
4.假设将所有的hashCode()方法返回值固定为某个值,那么会导致底层哈希表变成了 纯单向链表。
这种情况我们成为:散列分布不均匀。
什么是散列分布均匀?
假设有100个元素,10个单向链表,那么每个单向链表上有10个节点,这是最好的, 是散列分布均匀的。假设将所有的hashCode()方法返回值都设定为不一样的值,可以吗,有什么问题? 不行,因为这样的话导致底层哈希表就成为一维数组了,没有链表的概念了。 也是散列分布不均匀。散列分布均匀需要你重写hashCode()方法时有一定的技巧。
Properties是一个Map集合,继承Hashtable,Properties的key和value都是String类型。 Properties被称为属性类对象。 Properties是线程安全的。
本篇文章介绍了集合的常用方法以及个别集合的底层是如何实现的。介绍了集合的继承与实现结构。各个集合的扩容方式及扩容大小以及各个集合的优点和用途。希望大家可以根据本篇文章可以更加深刻的理解java中的集合。

版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/3737.html