
目录
一、uptime
1、使用 uptime 命令
2、以更人性化的格式显示时间
3、让 uptime 显示系统启动的日期/时间
4、获取版本信息和帮助信息
结论
二、top
1.输入top命令
1.1 系统运行时间和平均负载:
1.2 任务:
1.3 CPU 状态:
1.4 内存使用:
1.5 各进程(任务)的状态监控:
2.交互命令
2.1 ‘h’: 帮助
2.2 ‘’ 或者 ‘’: 刷新显示
三、vmstat
望名生义,uptime 命令告诉你系统up了(运行了)多长时间。这是语法:
这个工具的 man 页是这么说的:
uptime 的基础用法很简单 —— 只需要输入命令名称然后按下回车就行。这是输出:

下面每一列代表的含义:
19:40:29 //当前时间
up 3 days, 7:32 //系统运行时间
3users //正在登录用户数
最后三个数依次是 1分钟,5分钟,15分钟系统的平均负载(load average)。
什么是平均负载呢?
简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和CPU使用率并没有直接关系。
这里是 uptime man 页中关于最后一项信息的说明:
最理想的平均活跃进程数是什么?
就是刚好每个CPU上都刚好运行着一个进程,这样每个CPU都得到了充分的利用。比如平均负载为4时意味着什么呢?
- 在只有4个CPU的系统上,意味着所有的CPU都刚好被完全占用。
- 在8个CPU的系统上,意味着CPU有50%的空闲。
- 而在有2个CPU系统上,意味着有一半的进程竞争不到CPU。
平均负载为多少时合理?
平均负载比CPU个数大的时候,系统就已经出现了过载。
- 如果1分钟,5分钟,15分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
- 如果1分钟的值远小于15分钟的值,就说明系统最近1分钟负载在减少,而过去15分钟内却有很大负载。
- 反之则相反,如果1分钟的值远大于15分钟的值,说明近1分钟负载在增加,这种情况可能是临时性的,也可能还会持续,要持续观察,一旦1分钟的平均负载超过了CPU的数量,意味着系统正在发生过载的问题。
例如:一个单核系统上,平均负载为1.78,0.60,6.56,说明1分钟内,系统有78%的超载,而在15分钟内有556%的超载。
实际生产中,平均负载多高时需要关注呢?
平均负载高于CPU数量70%时,就应该分析排查负载高问题了。(不绝对)
平均负载与CPU使用率
- CPU密集型进程,使用大量CPU会导致平均负载升高,此时两者时一致的。
- I/O密集型进程,等待I/O也会导致平均负载升高,但CPU使用率不一定很高。
- 大量等待CPU的进程调度也会导致平均负载升高,此时的CPU使用率也会比较高。
若你只想知道系统运行了多长时间,而且希望以更人性化的格式来显示,那么可以使用 -p 项
这是输出:![]()
你也可以指定 uptme 显示系统开始运行的时间和日期。方法是使用 -s 命令项。
这是输出:![]()
-V 获取版本信息,-h 获取帮助信息。
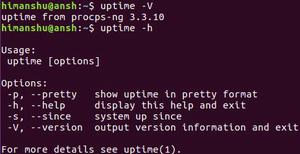
结论
可以看到,uptime 命令很容易理解也很容易使用。它没有提供很多的功能(命令选项也很少)。这里已经覆盖了它的所有功能了。因此只需要练习一下这些选项你就能在日常工作中使用它了。如果需要的话,可以查看它的 man 页[1]。
top命令经常用来监控linux的系统状况,比如cpu、内存的使用,程序员基本都知道这个命令,但比较奇怪的是能用好它的人却很少,例如top监控视图中内存数值的含义就有不少的曲解。
本文通过一个运行中的WEB服务器的top监控截图,讲述top视图中的各种数据的含义,还包括视图中各进程(任务)的字段的排序。
语法:
参数说明:
d:指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。
p:通过指定监控进程ID来仅仅监控某个进程的状态。
q:该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
S:指定累计模式。
s:使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i:使top不显示任何闲置或者僵死进程。
c:显示整个命令行而不只是显示命令名。
n : 更新的次数,完成后将会退出 top
b : 批次档模式,搭配 "n" 参数一起使用,可以用来将 top 的结果输出到档案内
常用命令说明:
Ctrl+L:擦除并且重写屏幕
K:终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i:忽略闲置和僵死进程。这是一个开关式命令。
q:退出程序
r:重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
S:切换到累计模式。
s:改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f或者F:从当前显示中添加或者删除项目。
o或者O:改变显示项目的顺序
l:切换显示平均负载和启动时间信息。
m:切换显示内存信息。
t:切换显示进程和CPU状态信息。
c:切换显示命令名称和完整命令行。
M:根据驻留内存大小进行排序。
P:根据CPU使用百分比大小进行排序。
T:根据时间/累计时间进行排序。
W:将当前设置写入~/.toprc文件中。
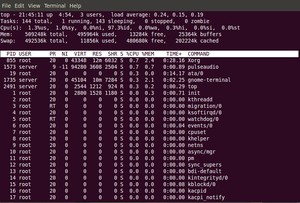
1.1 系统运行时间和平均负载:

top命令的顶部显示与uptime命令相似的输出:
21:45:11 — 当前系统时间
0 days, 4:54 — 系统已经运行了4小时54分钟(在这期间没有重启过)
2 users — 当前有2个用户登录系统
load average:0.24, 0.15, 0.19 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
1.2 任务:

Tasks — 任务(进程),系统现在共有144个进程,其中处于运行中的有1个,143个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第二行显示的是任务或者进程的总结。进程可以处于不同的状态。这里显示了全部进程的数量。除此之外,还有正在运行、睡眠、停止、僵尸进程的数量(僵尸是一种进程的状态)。这些进程概括信息可以用't'切换显示
1.3 CPU 状态:

这里显示不同模式下所占cpu时间百分比,这些不同的cpu时间表示:
1.3% us — 用户空间占用CPU的百分比。
1.0% sy — 内核空间占用CPU的百分比。
0.0% ni — 用户空间改变过优先级的进程占用CPU的百分比
97.3% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.3% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si — 软中断(Software Interrupts)占用CPU的百分比
0.0% st— 这个虚拟机被hypervisor偷去的CPU时间(译注:如果当前处于一个hypervisor下的vm,实际上hypervisor也是要消耗一部分CPU处理时间的)。
在这里CPU的使用比率和windows概念不同,如果你不理解用户空间和内核空间,需要充充电了。
1.4 内存使用:

接下来两行显示内存使用率,有点像'free'命令。第一行是物理内存使用,第二行是虚拟内存使用(交换空间)。
物理内存显示如下:全部可用内存、已使用内存、空闲内存、缓冲内存。相似地:交换部分显示的是:全部、已使用、空闲和缓冲交换空间。
内存显示可以用'm'命令切换。
k total — 物理内存总量(509M)
k used — 使用中的内存总量(495M)
13284k free — 空闲内存总量(13M)
25364k buffers — 缓存的内存量 (25M)
swap交换分区
k total — 交换区总量(492M)
11856k used — 使用的交换区总量(11M)
k free — 空闲交换区总量(480M)
k cached — 缓冲的交换区总量(202M)
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:
13284+25364+ = 240M。
上述最后提到的缓冲的交换区总量,这里解释一下,所谓缓冲的交换区总量,即内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入。
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第六行是空行
1.5 各进程(任务)的状态监控:
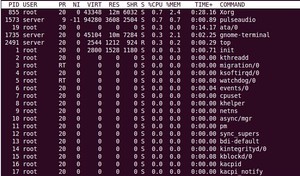
序号 列名 含义
a PID 进程id
b PPID 父进程id
c RUSER Real user name
d UID 进程所有者的用户id
e USER 进程所有者的用户名
f GROUP 进程所有者的组名
g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ?
h PR 优先级
i NI nice值。负值表示高优先级,正值表示低优先级
j P 最后使用的CPU,仅在多CPU环境下有意义
k %CPU 上次更新到现在的CPU时间占用百分比
l TIME 进程使用的CPU时间总计,单位秒
m TIME+ 进程使用的CPU时间总计,单位1/100秒
n %MEM 进程使用的物理内存百分比
o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
r CODE 可执行代码占用的物理内存大小,单位kb
s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
t SHR 共享内存大小,单位kb
u nFLT 页面错误次数
v nDRT 最后一次写入到现在,被修改过的页面数。
w S 进程状态。(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程)
x COMMAND 命令名/命令行
y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
z Flags 任务标志,参考 sched.h
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
2.1 ‘h’: 帮助
可以用h或?显示交互命令的帮助菜单。
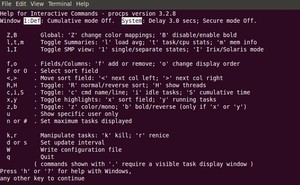
2.2 ‘<ENTER>’ 或者 ‘<SPACE>’: 刷新显示
top命令默认在一个特定间隔(3秒)后刷新显示。要手动刷新,用户可以输入回车或者空格。
多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
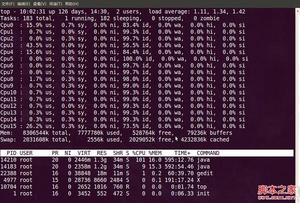
top视图 02
观察上图,服务器有16个逻辑CPU,实际上是4个物理CPU。
进程字段排序
默认进入top时,各进程是按照CPU的占用量来排序的,在【top视图 01】中进程ID为14210的Java进程排在第一(cpu占用100%),进程ID为14183的java进程排在第二(cpu占用12%)。可通过键盘指令来改变排序字段,比如想监控哪个进程占用MEM最多,我一般的使用方法如下:
1. 敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下:
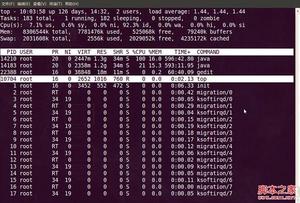
top视图 03
我们发现进程id为10704的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。
2. 敲击键盘“x”(打开/关闭排序列的加亮效果),top的视图变化如下:
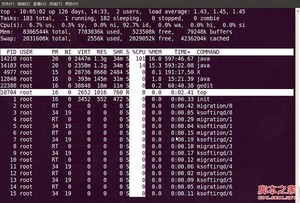
top视图 04
可以看到,top默认的排序列是“%CPU”。
3. 通过”shift + >”或”shift + <”可以向右或左改变排序列,下图是按一次”shift + >”的效果图:
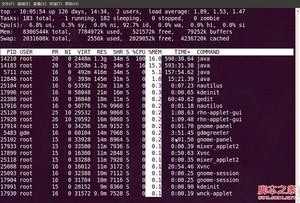
top视图 05
视图现在已经按照%MEM来排序了。
改变进程显示字段
1. 敲击“f”键,top进入另一个视图,在这里可以编排基本视图中的显示字段:
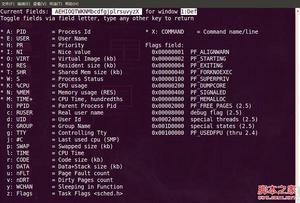
top视图 06
这里列出了所有可在top基本视图中显示的进程字段,有”*”并且标注为大写字母的字段是可显示的,没有”*”并且是小写字母的字段是不显示的。如果要在基本视图中显示“CODE”和“DATA”两个字段,可以通过敲击“r”和“s”键:
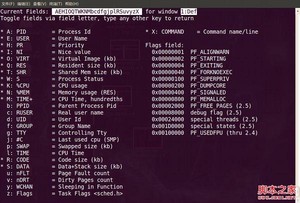
top视图 07
2. “回车”返回基本视图,可以看到多了“CODE”和“DATA”两个字段:
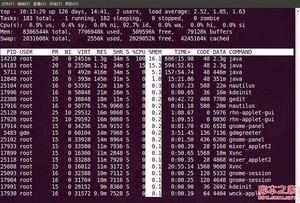
top视图 08
top命令的补充
top命令是Linux上进行系统监控的首选命令,但有时候却达不到我们的要求,比如当前这台服务器,top监控有很大的局限性。这台服务器运行着websphere集群,有两个节点服务,就是【top视图 01】中的老大、老二两个java进程,top命令的监控最小单位是进程,所以看不到我关心的java线程数和客户连接数,而这两个指标是java的web服务非常重要的指标,通常我用ps和netstate两个命令来补充top的不足。
代码如下:
监控java线程数:
ps -eLf | grep java | wc -l
监控网络客户连接数:
netstat -n | grep tcp | grep 侦听端口 | wc -l
上面两个命令,可改动grep的参数,来达到更细致的监控要求。
在Linux系统“一切都是文件”的思想贯彻指导下,所有进程的运行状态都可以用文件来获取。系统根目录/proc中,每一个数字子目录的名字都是运行中的进程的PID,进入任一个进程目录,可通过其中文件或目录来观察进程的各项运行指标,例如task目录就是用来描述进程中线程的,因此也可以通过下面的方法获取某进程中运行中的线程数量(PID指的是进程ID):
代码如下:
ls /proc/PID/task | wc -l
在linux中还有一个命令pmap,来输出进程内存的状况,可以用来分析线程堆栈:
查看多核CPU命令
mpstat -P ALL 和 sar -P ALL
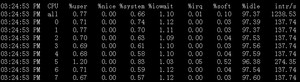
说明:sar -P ALL > aaa.txt 重定向输出内容到文件 aaa.txt
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、IO读写、CPU活动等进行监视。它是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。
命令语法:
命令参数:
不同版本Linux的cp命令参数有可能不同。不过默认应该都是[ delay [ count ] ] ,delay是间隔,count显示多少次信息。可以和上面的某些参数结合使用。
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
2表示每个两秒采集一次服务器状态,1表示只采集一次。
实际上,在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了,例如:
这表示vmstat每2秒采集数据,一直采集,直到我结束程序,这里采集了5次数据我就结束了程序。
好了,命令介绍完毕,现在开始实战讲解每个参数的意思。
输出字段的意义:
用来做buffer(缓存,主要用于块设备缓存)的内存数,
单位:KB
cache the amount of memory used as cache用来做cache(缓存,主要用于缓存文件)的内存,
单位:KB
inact the amount of inactive memory.(要用vmstat -a) inactive memory的总量(长时间未访问过的页面放进inactive list,该值大表明在必要时可以回收的页面很多) active the amount of active memory.
(要用vmstat -a) active memroy的总量(刚访问过的页面放进active list,无法马上回收,只能通过与文件或交换区进行页交换) Swap si Amount of memory swapped in from disk (/s) 从磁盘交换到内存的交换页数量,单位:KB/秒。 so Amount of memory swapped to disk (/s) 从内存交换到磁盘的交换页数量,单位:KB/秒 内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。当看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,这个是不正确的。不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。 当内存的需求大于RAM的数量,服务器启动了虚拟内存机制,通过虚拟内存,可以将RAM段移到SWAP DISK的特殊磁盘段上,这样会 出现虚拟内存的页导出和页导入现象,页导出并不能说明RAM瓶颈,虚拟内存系统经常会对内存段进行页导出,但页导入操作就表明了服务器需要更多的内存了, 页导入需要从SWAP DISK上将内存段复制回RAM,导致服务器速度变慢。 IO bi Blocks received from a block device (blocks/s) 每秒从块设备接收到的块数,单位:块/秒 也就是读块设备。 bo Blocks sent to a block device (blocks/s) 每秒发送到块设备的块数,单位:块/秒 也就是写块设备。 System in he number of interrupts per second, including the clock 每秒的中断数,包括时钟中断。与cs一般同步增长。in和cs两值越大,会看到由内核消耗的CPU时间(sy)也会越大。 cs The number of context switches per second 每秒的环境(上下文)切换次数。比如我们调用系统函数,就要进行上下文切换,而过多的上下文切换会浪费较多的cpu资源,这个数值应该越小越好,如果太大了,要考虑调低线程或者进程的数目,例如apache和nginx这种web服务进程。 CPU These are percentages of total CPU time. us Time spent running non-kernel code.(user time, including nice time) 用户CPU时间(非内核进程占用时间)(单位为百分比)。 us的值比较高时,说明用户进程消耗的CPU时间多。 sy Time spent running kernel code. (system time) 系统使用的CPU时间(单位为百分比)。sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。 id Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time. 空闲的CPU的时间(百分比),在Linux 2.5.41之前,这部分包含IO等待时间。 wa Time spent waiting for IO. Prior to Linux 2.5.41, shown as zero. 等待IO的CPU时间,在Linux 2.5.41之前,这个值为0 .这个指标意味着CPU在等待硬盘读写操作的时间,用百分比表示。wait越大则机器io性能就越差。说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。 st Time stolen from a virtual machine 针对虚拟技术,如果st不为0,说明本来分配给本机的CPU时间被其他虚拟机偷走了。
Vmstat是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析,所以我们再引入另一个工具dstat。dstat是一个可以取代vmstat、iostat、netstat和ifstat这些命令的多功能产品。dstat克服了这些命令的局限并增加了一些功能和监控项,也变得更灵活了。dstat可以很方便监控系统运行状况并用于基准测试和排除故障。
特性:
结合了vmstat,iostat,ifstat,netstat以及更多的信息
实时显示统计情况
在分析和排障时可以通过启用监控项并排序
模块化设计
使用python编写的,更方便扩展现有的工作任务
容易扩展和添加你的计数器(请为此做出贡献)
包含的许多扩展插件充分说明了增加新的监控项目是很方便的
可以分组统计块设备/网络设备,并给出总数
可以显示每台设备的当前状态
极准确的时间精度,即便是系统负荷较高也不会延迟显示
显示准确地单位和和限制转换误差范围
用不同的颜色显示不同的单位
显示中间结果延时小于1秒
支持输出CSV格式报表,并能导入到Gnumeric和Excel以生成图形
安装方法:
Ubuntu/Mint和Debin系统:
# sudo apt-get install dstat
RHEL/Centos和Fedora系统:
# yum install dstat
ArchLinux系统:
# pacman -S dstat
磁盘统计:磁盘的读写操作,这一栏显示磁盘的读、写总数。
网络统计:网络设备发送和接受的数据,这一栏显示的网络收、发数据总数。
分页统计:系统的分页活动。分页指的是一种内存管理技术用于查找系统场景,一个较大的分页表明系统正在使用大量的交换空间,或者说内存非常分散,大多数情况下你都希望看到page in(换入)和page out(换出)的值是0 0。
系统统计:这一项显示的是中断(int)和上下文切换(csw)。这项统计仅在有比较基线时才有意义。这一栏中较高的统计值通常表示大量的进程造成拥塞,需要对CPU进行关注。你的服务器一般情况下都会运行运行一些程序,所以这项总是显示一些数值。
默认情况下,dstat每秒都会刷新数据。如果想退出dstat,你可以按"CTRL-C"键。
需要注意的是报告的第一行,通常这里所有的统计都不显示数值的。这是由于dstat会通过上一次的报告来给出一个总结,所以第一次运行时是没有平均值和总值的相关数据。
但是dstat可以通过传递2个参数运行来控制报告间隔和报告数量。例如,如果你想要dstat输出默认监控、报表输出的时间间隔为3秒钟,并且报表中输出10个结果,你可以运行如下命令:
dstat 3 10
在dstat命令中有很多参数可选,你可以通过man dstat命令查看,大多数常用的参数有这些:
-l :显示负载统计量
-m :显示内存使用率(包括used,buffer,cache,free值)
-r :显示I/O统计
-s :显示交换分区使用情况
-t :将当前时间显示在第一行
–fs :显示文件系统统计数据(包括文件总数量和inodes值)
–nocolor :不显示颜色(有时候有用)
–socket :显示网络统计数据
–tcp :显示常用的TCP统计
–udp :显示监听的UDP接口及其当前用量的一些动态数据
当然不止这些用法,dstat附带了一些插件很大程度地扩展了它的功能。你可以通过查看/usr/share/dstat目录来查看它们的一些使用方法,常用的有这些:
-–disk-util :显示某一时间磁盘的忙碌状况
-–freespace :显示当前磁盘空间使用率
-–proc-count :显示正在运行的程序数量
-–top-bio :指出块I/O最大的进程
-–top-cpu :图形化显示CPU占用最大的进程
-–top-io :显示正常I/O最大的进程
-–top-mem :显示占用最多内存的进程
举一个我常用的例子,显示哪些进程在占用IO、内存、CPU:
# dstat -l -m -r -c --top-io --top-mem --top-cpu
如何输出一个csv文件
想输出一个csv格式的文件用于以后,可以通过下面的命令:
# dstat –output /tmp/sampleoutput.csv -cdn
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/1875.html