
目录
一、前言
二、网络层次结构
三、网络设备驱动核心数据结构和函数
网络设备驱动是 Linux 的第三大类驱动,也是我们学习的最后一类 Linux 驱动。这里我们首先简单学习一下网络协议层次结构,然后简单讨论 Linux 内核中网络实现的层次结构。接下来着重介绍了网络设备驱动所涉及的核心数据结构和函数接口。在此基础之上实现了一个虚拟的网络设备驱动,并以该驱动框架为蓝本,分析了 DM9000 网卡的驱动。最后简单介绍了 NAPI的意义和实现过程。
ISO (International Organization for Standardization, 国际标准化组织) 设计的 OSI(Open System Interconnection,开放系统互联)参考模型将网络划分成7个层次,这种参考模型虽然没有得到真正意义上的应用,但是几乎所有的互联系统的设计都参考了该模型,所以它称得上真正的参考模型。OSI在 Internet上的一个现实版的分层模型就是TCP/IP层次模型,两者的对应关系如图 所示。

Network Access(网络访问层)对应了 Data Link (数据链路层)和 Physical(物理层),包含了信号的电气特性,传输介质的机械特性(属于物理层) 和帧格式定义,差错处理,流量控制,链路的建立、维护和释放(属于数据链路层) 等的处理。每一个硬件设备都应该有一个唯一的ID,这个 ID 也叫硬件地址或 MAC 地址。
Internet (互联网络层) 对应了 Network (网络层),利用数据链路层提供的两个相邻端点之间的数据帧的传送功能,进一步管理网络中的数据通信,将数据设法从源端经过若干个中间节点传送到目的端,从而向运输层提供最基本的端到端的数据传送服务。本层提供重要的寻址和路由选择服务,在 TCP/IP 中,本层的地址是 IP 地址。
Host-to-Host(主机到主机)对应 Transport (传输层),提供端到端的传输,在 TCP/IP中,本层使用端口号进行寻址。
Application (应用层) 对应 Application、Presentation (表示层)和 Session (会话层),
从应用程序的角度来看网络连接,在两个应用之间建立通信连接之后,应用层负责传输实际的应用数据。
Linux 将网络协议实现在内核内部,整个系统的层次结构如图所示.
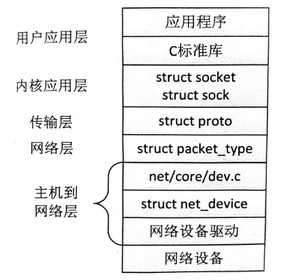
在这里,我们关注的是网络设备驱动,它负责了数据链路层的一部分工作。可以很容易地想见,网络设备驱动最主要的工作就是驱动网络设备 (通常也叫网卡) 将数据发送出去,或者将网络设备收到的数据往上层递交,更简单地说就是负责网络数据的收发。我们知道,网络数据是按包为单位来组织的,这样网络设备驱动就和块设备驱动非常类似。网络设备驱动负责将数据包“写入”网络或从网络中“读取”数据包,从而完成上层的请求。但是,它们之间还是有一些差别的。首先,网络设备没有设备节点,因此没有使用文件系统的那套接口对网络设备进行访问,使用的是另一套套接字编程接口。其次,网络设备通常是基于中断的方式工作的,在收到数据包后,会产生相应的中断,网络驱动从网卡中获取数据包后进行必要的验证,然后主动将数据包递交给上层。而块设备驱动在读取方向上也是被动地接受上层的请求。
(之前说的linux中万物皆文件不准却就是在这里,网络设备使用的是套接字接口而不是像文件系统那样抽象成一个文件驱操作)
网络设备驱动在这里担当了承上启下的作用,使上层的网络协议层不必关心底层的硬件细节信息。另外,驱动本身基本也与协议无关,不需要解析网络数据包,只负责数据包的收发。
当然,除了数据包收发的主要工作之外,网络设备驱动还要负责大量的管理任务,如设置硬件地址、修改传输参数、错误处理和统计、流量控制等。
(真的多结构体里套一堆自定义类型)
name: 网络设备的名字,如ethx 表示以太网设备、pppx 表示 PPP 连接类型的设备isdnx 表示ISDN 卡、lo 表示环回设备。
mem_end、mem start: 如 PCI 网卡之类的网络设备的共享内存的结束地址和起始地址。
base_addr:如 PCI 网卡之类的网络设备的I/O 端口地址。
irq:网卡使用的中断号。
stats: 网卡的统计信息,包括rx_packets、tx_packets、rx_bytes、tx_bytes、rx_errors、tx_errors、rx_dropped、tx_dropped 之类的收发统计信息。
netdev_ops: 网络设备的操作方法集合,后面会更详细地进行描述。
ethtool_ops: 用户层 ethtool 工具在驱动中对应的操作方法集合,例如使用ethtooleth0 命令可以查看 etho 网络设备的所有寄存器内容。
mtu: 接口的 MTU(最大传输单元) 值,对于以太网设备来说通常是 1500 个字节
type: 接口的硬件类型。
flags;一组接口的标志。
hard_header_len:硬件头长度,以太网是 14 个字节。
addr_len; 硬件地址长度,以太网为 MAC 地址,长度为6 个字节
uc:单播 MAC 地址列表。
mc:多播 MAC 地址列表。
dev_addr: 指向硬件地址的指针
broadcast: 广播的硬件地址。
_tx: 网络设备的发送数据包队列。
num_tx_queues: 由 alloc_netdev_mq 函数分配的属于当前网络设备的发送队列的数量
real_num_tx_queues:当前活动的发送队列的数量。
tx_queue_len: 每个队列允许的最大帧数量。
trans_start: 用jiffies 表示的数据包开始发送的时间
watchdog_timeo: 数据包发送的超时时间。
watchdog_timer: 发送超时的定时器,如果超时时间到期,数据包还没被发送出去那么驱动提供的超时函数将会被调用。
网络设备的操作方法集合由 struct net_device_ops 结构来描述,该结构中有很多函数指针指向不同的函数,用于对网络设备进行不同的操作,但我们最关心的还是与数据的发送处理相关的内容,
ndo_init: 当网络设备注册后,该函数被调用,用于网络设备的后期初始化操作,没有特殊要求则为 NULL。
ndo_open: 当激活网络设备时,该函数被调用。
ndo_stop: 当网络设备被禁用时,该函数被调用。
ndo_start_xmit:当一个网络数据包需要发送时,该函数被调用,函数应该返回
ndo_set_mac address:当需要改变 MAC 地址时,该函数被调用,可以为NULL。
NETDEV_TX_OK 或 NETDEV_TX_BUSY。
ndo_validate_addr: 用于验证 MAC 地址是否合法有效
ndo_do_ioctl: 用于处理通用接口代码不能处理的用户请求。
ndo_change_mtu:当用户想要改变设备的 MTU时,该函数被调用。
ndo_tx_timeout: 当发送超时时,该函数被调用。
ndo_get_stats: 用于获取网络设备的统计信息。
围绕 struct net_device 结构的主要函数和宏如下。
alloc_netdev: 用于分配并且初始化一个 struct net_device 结构对象,并且还在该对象的后面分配了 sizeof_priv 字节大小的空间用于存放驱动的私有数据。为了提高访问的效率,驱动私有的数据开始地址对齐到 32字节的边界,所以在内存上的布局大致如图所示。
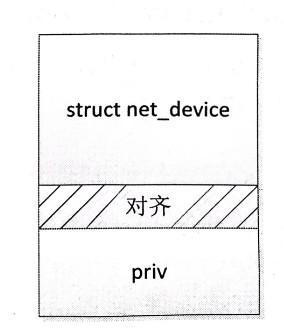
netdev_priv:用于获取驱动私有数据区的起始地址
free_netdev:释放 struct net_device 结构对象。
alloc_etherdev:是专门针对分配并初始化以太网设备的 struct net_device 结构对象的一个宏,它的名字为 eth%d,也就是 eth 后面跟一个设备序号的数字,setup 方法为ether_setup。另外,这个宏还给该网络设备在发送方向和接收方向上分别分配了一个队列。
ether_setup:针对以太网设备的 struct net_device 结构对象中相关成员的初始化。代码如下。
register_netdev:注册网络设备。
unregister_netdev:注销网络设备。
网络数据的收发是基于队列的,在收发方向上各有单独的队列,上层要发送的数据包先送入发送队列,然后再通过网络设备驱动发送,网卡接收到的数据包放入接收队列,然后上层从接收队列中取出数据包进行协议解析。与队列相关的主要操作有如下的函数。
netif_start_queue: 允许上层通过 hard_start_xmit 函数发送数据包
netif_stop_queue: 禁止上层通过 hard_start_xmit 函数发送数据包,这样可以在网络设备驱动中完成流控。
上面的数据包操作都是关于发送的,在网络设备操作方法集合里也没有数据包接收方向的接口函数。其实我们在前面也说过,网络设备驱动应该在收到数据包的时候“主动”将数据包递交给上层,一般这是发生在网卡的接收中断函数中的 (网卡一般都是按中断的方式工作的)。前面学习软中断时我们也提到过,网卡的接收中断的下半部完成对数据包的进一步处理,包括校验和拆包等,这样就完成了数据包向上层逐层传递的过程。这个向上层递交数据包的操作通过下面的函数来进行。
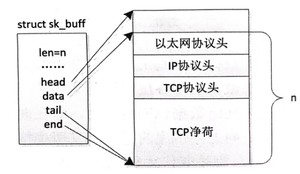
该函数返回 NET_RX_SUCCESS 表示成功,返回 NET_RX_DROP 表示包被丢弃。这里又引出一个关键的数据结构 struct sk_buff,即套接缓冲区,用于在各层之间传递数据包。但是该缓冲区不仅仅是一片容纳数据包的内存,还需要有额外的一些管理信息。数据包在网络协议层之间流动,处理它的效率必须要高。假如在下层向上层的递交过程中,下层的协议去掉协议头后将剩下的数据复制到上层,这会涉及大量的复制工作,显然这会影响效率。解决这个问题的方法就是要在各层协议间共享同一个缓冲区,在层与层之间传递缓冲区的指针。不过,因为网络数据包的特殊性,即在向下层传递的过程中要添加协议包头和可能在尾部的校验,向上层传递的过程中又要去掉协议包头和可能的尾部校验,因此层与层之间传递的指针必须要变化才行。struct sk_buff 这个巧妙的数据结构就能实现这一功能,如果不考虑分散/聚集 I/O 的处理,那么要理解它还是比较容易的。下面列出该结构最主要的成员。
tstammp: 收到数据包的时间戳。
dev: 指向收到该数包的网络设备结构对象的指针。
len: 所有数据的长度,包括了用于分散/聚集 (分片) 数据的长度。
data_len:分片数据的长度。
protocol: 网络设备驱动收到的数据包的协议类型。
transport_header:传输层的数据包头的偏移地址。
network_header: 网络层数据包头的偏移地址。
mac_header: 数据链路层的数据包头的偏移地址。
tail: 如果没有使用偏移来表示,那么 tail 是指向有效数据的尾部的指针,否则是有效数据尾部的偏移地址。
end: 如果没有使用偏来表示,那么 end 是指向数据缓冲区 (没有分片)的尾部的指针,否则是缓冲区尾部的偏移地址。
head: 指向数据缓冲区的头部。
data: 指向有效数据的头部。
可以通过一个比较简单的无分片 skb 来直观展示上述关键成员,如图所示
围绕 struct sk_buf 结构有一些操作函数,现在将最常用的函数和宏分别罗列如下,并给出操作的示意图。
kfree_skb、 dev_kfree_skb:释放skb, kfree_skb 和 alloc_skb 配对使用, dev_kfree_skb和dev_alloc_skb 配对使用。
刚分配的 skb 示意图如图所示,为了简化问题,忽略了为提高缓冲区访问效率的对齐处理。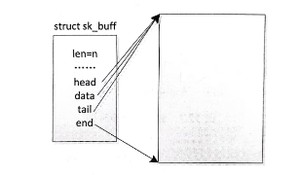
skb_reserve: 通过源码我们知道,该函数是将 data 和 tail 同时向 end 方向偏移 len 个字节。通常是在刚分配好 skb 后为了预留足够的协议头空间或为了对齐的操作,如图所示。
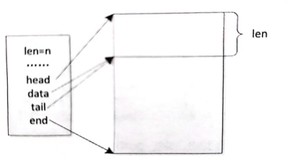
skb_put: 将 tail 向 end 方向偏 len 个字节,如图所示。在 put 操作之前, tail处于实线箭头的位置;在 put 操作之后,tail 在虚线箭头的位置,函数返回 put 操作之前的 tail 指针,通常用于添加尾部数据。
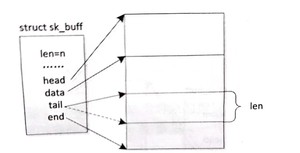
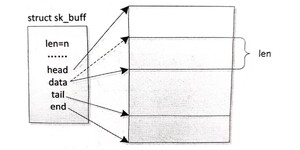
skb_pull: 将 data 向 end 方向偏 len 个字节,如图所示。在 pull 操作之前,data处于实线箭头的位置;在 push 作之后,data 在虚线箭头的位置。通数返回 pull 操作之后的 data 指针,通常用于去掉协议头数据。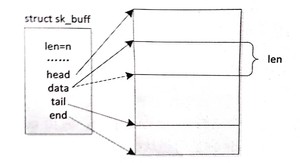
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/15015.html