
命名实体识别(Named Entity Recognition,NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括:
- 人名
- 地名
- 机构名
- 专有名词等
NER是:
- 信息提取
- 问答系统
- 句法分析
- 机器翻译
- 面向Semantic Web的元数据标注等
应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要的地位。
例如在搜索场景下,NER是深度查询理解(Deep Query Understanding,简称 DQU)的底层基础信号,主要应用于搜索召回、用户意图识别、实体链接等环节,NER信号的质量,直接影响到用户的搜索体验,是NLP中一项非常基础的任务。
这里针对搜索召回稍微展开一些细节。
在O2O搜索中,对商家POI的描述是商家名称、地址、品类等多个互相之间相关性并不高的文本域。如果对O2O搜索引擎也采用全部文本域命中求交的方式,就可能会产生大量的误召回。一种解决方法如下图所示,

即让特定的查询只在特定的文本域做倒排检索,我们称之为“结构化召回”,可保证召回商家的强相关性。
举例来说,对于“海底捞”这样的请求,有些商家地址会描述为“海底捞附近几百米”,若采用全文本域检索这些商家就会被召回,显然这并不是用户想要的。而结构化召回基于NER将“海底捞”识别为商家,然后只在商家名相关文本域检索,从而只召回海底捞品牌商家,精准地满足了用户需求。
要了解NER是一回什么事,首先要先说清楚,什么是实体。简单的理解,实体,可以认为是某一个概念的实例。
例如,
- “人名”是一种概念,或者说实体类型,那么“蔡英文”就是一种“人名”实体了。
- “时间”是一种实体类型,那么“中秋节”就是一种“时间”实体了。
所谓实体识别,就是将你想要获取到的实体类型,从一句话里面挑出来的过程。
如上面的例子所示,句子“小明在北京大学的燕园看了中国男篮 的一场比赛”,通过NER模型,将“小明 ”以PER,“北京大学”以ORG,“燕园”以LOC,“中国男篮”以ORG为类别分别挑了出来。
NER是一种序列标注问题,因此他们的数据标注方式也遵照序列标注问题的方式,主要是以下几种方法:
- IOB
- BIOES
- Markup
先列出来BIOES分别代表什么意思:
- B,即Begin,表示开始
- I,即Intermediate,表示中间
- E,即End,表示结尾
- S,即Single,表示单个字符
- O,即Other,表示其他,用于标记无关字符
将“小明在北京大学的燕园看了中国男篮的一场比赛”这句话,进行标注,结果就是:
换句话说,NER的过程,就是根据输入的句子,预测出其标注序列的过程。
- I,表示内部
- O,表示外部
- B,表示开始
例子:B/I-XXX,其中:
- B/I,表示这个词属于命名实体的开始或内部
- XXX,表示命名实体的类型
基本思想是匹配规则,

在很多搜索场景实体识别的工业实践中,整体技术选型往往是“实体词典匹配+模型预测”的框架,如下图所示,

实体词典匹配,通俗来说就是”规则匹配“,这种算法主要有如下优点:
- 1、搜索中用户查询的头部流量通常较短、表达形式简单,且集中在商户、品类、地址等三类实体搜索,实体词典匹配虽简单但处理这类查询准确率也可达到90%以上。
- 2、词典是NER领域强相关的,通过挖掘业务数据资源获取业务实体词典,经过在线词典匹配后可保证识别结果是领域适配的。
- 3、新业务接入更加灵活,只需提供业务相关的实体词表就可完成新业务场景下的实体识别。
- 4、NER下游使用方中有些对响应时间要求极高,词典匹配速度快,基本不存在性能问题。
- 1、随着搜索体量的不断增大,中长尾搜索流量表述复杂,越来越多OOV(Out Of Vocabulary)问题开始出现,实体词典已经无法满足日益多样化的用户需求,模型预测具备泛化能力,可作为词典匹配的有效补充。
- 2、实体词典匹配无法解决歧义问题,比如“黄鹤楼美食”,“黄鹤楼”在实体词典中同时是武汉的景点、北京的商家、香烟产品,词典匹配不具备消歧能力,这三种类型都会输出,而模型预测则可结合上下文,不会输出“黄鹤楼”是香烟产品。
HMM的相关细节可以参阅这篇文章。
CRF的相关细节可以参阅这篇文章。
抽象来说,基于深度学习进行NER任务可以分为如下两个步骤:
- representation extraction(词向量化):旨在获取输入序列中每个标记的高维表示。为了嵌入每个输入单词x,首先将输入句子X输入到编码器模型(例如BERT)。然后,将单词嵌入模型的最后一层的输出用作高维表示hi ∈ Rm×1,其中n表示输入句子的长度,m表示向量的维数的可变参数。
- classification(多分类):对于分类,每个嵌入的高维向量h被发送到一个多层感知器,然后使用softmax函数生成命名实体词汇的分布: pNER = softmax MLP( h ∈ Rm×1 )
1)LSTM+CRF
采用LSTM作为特征抽取器,再接一个CRF层来作为输出层。
2)CNN+CRF
3)BERT+(LSTM)+CRF

- 数量无穷:业务不断发展,用户量不断增加,命名实体的数量不断增加
- 构词灵活:例如”广州恒大淘宝俱乐部“、”广州恒大“、”恒大“
- 类别模糊:例如”广州未赢够“、“广州下雪嘞”
参考链接:
中文命名实体识别工具有很多,




参考链接:
近年来,随着硬件计算能力的发展以及词的分布式表示(word embedding)的提出,神经网络可以有效处理许多NLP任务。这类方法对于序列标注任务(如CWS、POS、NER)的处理方式是类似的:将token从离散one-hot表示映射到低维空间中成为稠密的embedding,随后将句子的embedding序列输入到RNN中,用神经网络自动提取特征,Softmax来预测每个token的标签。
这种方法使得模型的训练成为一个端到端的过程,而非传统的pipeline,不依赖于特征工程,是一种数据驱动的方法,但网络种类繁多、对参数设置依赖大,模型可解释性差。此外,这种方法的一个缺点是对每个token打标签的过程是独立的进行,不能直接利用上文已经预测的标签(只能靠隐含状态传递上文信息),进而导致预测出的标签序列可能是无效的,例如标签I-PER后面是不可能紧跟着B-PER的,但Softmax不会利用到这个信息。
为了解决这个问题,学界提出了DL-CRF模型做序列标注。在神经网络的输出层接入CRF层(重点是利用标签转移概率)来做句子级别的标签预测,使得标注过程不再是对各个token独立分类。

应用于NER中的BiLSTM-CRF模型主要由Embedding层(主要有词向量,字向量以及一些额外特征),双向LSTM层,以及最后的CRF层构成。
实验结果表明BiLSTM-CRF已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。
在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步提升效果。
接下里的问题是,什么是CRF层?为什么要用CRF?
首先,句子xxx中的每个单词表达成一个向量,该向量包含了上述的word embedding和character embedding,其中character embedding随机初始化,word embedding通常采用预训练模型初始化。所有的embeddings 将在训练过程中进行微调。
其次,BiLSTM-CRF模型的的输入是上述的embeddings,输出是该句子xxx中每个单词的预测标签
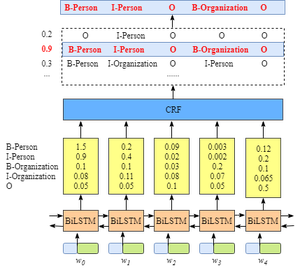
从上图可以看出,BiLSTM层的输出是每个标签的得分,如单词w0w_0w0,BiLSTM的输出为1.5(B-Person),0.9(I-Person),0.1(B-Organization), 0.08 (I-Organization) and 0.05 (O),这些得分就是CRF层的输入。
将BiLSTM层预测的得分喂进CRF层,具有最高得分的标签序列将是模型预测的最好结果。
根据上文,能够发现,如果没有CRF层,即我们用下图所示训练BiLSTM命名实体识别模型:

因为BiLSTM针对每个单词的输出是标签得分,对于每个单词,我们可以选择最高得分的标签作为预测结果。
例如,对于w0w_0w0,“B-Person"得分最高(1.5),因此我们可以选择“B-Person”最为其预测标签;同样的,w1w_1w1的标签为"I-Person”,w2w_2w2的为"O", w3w_3w3的标签为"B-Organization",w4w_4w4的标签为"O"。
按照上述方法,对于xxx虽然我们得到了正确的标签,但是大多数情况下是不能获得正确标签的,例如下图的例子:

显然,输出标签“I-Organization I-Person” 和 “B-Organization I-Person”是不对的。
CRF层可以对最终的约束标签添加一些约束条件,从而保证预测标签的有效性。而这些约束条件是CRF层自动从训练数据中学到。
约束可能是:
有了这些约束条件,无效的预测标签序列将急剧减少。
项目使用了conll2003_v2数据集,其中标注的命名实体共计九类:
- 'O'
- 'B-LOC'
- 'B-PER'
- 'B-ORG'
- 'I-PER'
- 'I-ORG'
- 'B-MISC'
- 'I-LOC'
- 'I-MISC'
实现了将输入识别为命名实体的模型,如下所示:
数据下载并解压,以供训练,下载解压后可以看到三个文件:
- test.txt
- train.txt
- valid.txt
打开后可以看到,数据格式如下:

我们只需要每行开头和最后一个数据,他们分别是文本信息和命名实体。
我们需要将数据进行处理,使之成为网络能接收的形式。




模型结构:

需要提醒读者朋友注意的是,这里仅仅演示了基于分词后的语料进行命名实体识别的过程,从原始连续文本分词语料这一步同样是需要额外处理的。分词是分词,命名实体识别是命名实体识别。
参考链接:
这里使用开源框架“Kashgari”完成该任务。
序列标注任务是中文自然语言处理(NLP)领域在句子层面中的主要任务,在给定的文本序列上预测序列中需要作出标注的标签。常见的子任务有:
- 命名实体识别(NER)
- Chunk 提取
- 词性标注(POS)等
- Python 3.6 环境
- BERT-Base, Chinese 中文模型
打印测试数据:

参考链接:
命名实体识别(NER)是一种典型的序列标注任务,它将给定句子X = {x1, ..., xn} 中的每个单词x分配一个实体类型y∈Y,其中Y表示实体标签集合,n表示给定句子的长度。
大规模语言模型(LLMs)表现出令人印象深刻的在上下文学习方面的能力:只需少量特定任务的示例作为演示,LLMs就能为新的测试输入生成结果。在上下文学习框架下,LLMs在各种自然语言处理任务中取得了有希望的结果,包括机器翻译(MT),问答(QA)和命名实体抽取(NEE)。
尽管取得了进展,LLMs在NER任务上的性能仍远低于监督基准,这主要是因为如下几个原因:
- 1、第一个问题是NER和LLMs之间固有的差距:NER本质上是一个序列标注任务,模型需要为句子中的每个标记分配一个实体类型标签,而LLMs是在文本生成任务下形式化的。语义标注任务与文本生成模型之间的差距导致了将LLMs应用于解决NER任务时性能较差。
- 2、LLMs在NER任务中的另一个大问题是幻觉问题,即LLMs倾向于过于自信地将NULL输入标记为实体。
为了解决第一个问题,GPT-NER被提出,主要的解决方案思路如下:
GPT-NER将NER任务转化为一项可以被LLMs轻松适应的文本生成任务。具体而言,将在输入文本“Columbus is a city”中找到位置实体的任务转化为生成文本序列“@@Columbus is a city”,其中特殊标记@@表示实体。我们发现,与其他形式化方法相比,所提出的策略可以显著降低生成完全编码输入序列标签信息的文本的难度,因为模型只需标记实体的位置并为其余标记复制。实验证明,所提出的策略显著提高了性能。
为了解决第二个问题,提出了一种自我验证策略,该策略位于实体提取阶段之后,促使LLMs自问提取的实体是否属于已标记的实体标签。自我验证策略作为一种调节功能来抵消LLMs过度自信的效果,在解决幻觉问题方面非常有效,导致性能显著提升。
特别值得注意的是,GPT-NER在低资源和少样本NER设置中表现出令人印象深刻的熟练程度:当训练数据极为稀缺时,GPT-NER比监督模型表现显著更好。这说明了GPT-NER在实际的NER应用中的潜力,即使标记样本的数量很少。
GPT-NER使用大型语言模型来解决NER任务。GPT-NER遵循基于上下文学习的一般范例,可以分解为三个步骤:
- (1)提示构建:对于给定的输入句子X,我们为X构建一个提示(表示为Prompt(X)),few-shot prompt如下图所示。
- (2)将构建的提示输入到大型语言模型(LLM)中,以获得生成的文本序列W = {w1, ..., wn}。对于这个文件序列W的格式有两点约束要求:(i) 很容易被转换成实体标签序列;(ii) 很容易被LLM以高准确率的方式生成,即要考虑到LLM文本序列生成任务的难度。
- (3)将文本序列W转换为实体标签序列,从而获得最终结果。

-
(1) Task Description: It’s surrounded by a red rectangle, and instructs the GPT-3 model that the current task is to recognize Location entities using linguistic knowledge.
-
(2) Few-shot Demonstrations: It’s surrounded by a yellow rectangle giving the GPT-3 model few-shot examples for reference.
-
(3) Input Sentence: It’s surrounded by a blue rectangle indicating the input sentence, and the output of the GPT-3 model is colored green.
尽管基于上下文学习范例是直观的,但NER任务并不容易适应它,因为NER任务本质上是一个序列标注任务,而不是生成任务,上述方法存在如下几点问题:
- 采用few-shot prompt的方法,每次次只能提取一种实体,因为要提取出所有的实体,必须遍历实体列表,但是LLM对提示的长度有一个硬性的限制(例如GPT-3的4096个tokens)。
few-shot prompt提示构建这一步的目的主要有两个:
- 规范LLM输出的格式
- 给LLM提升生成输出的辅助证据
格式问题容易解决,这里主要需要解决的是实例样本质量的问题,我们需要按照一定的策略给LLM提供合适的实例样本,以提高LLM生成输出的质量。
1)Random Retrieval
最直接的策略是从训练集中随机选择k个示例。明显的缺点是:无法保证检索到的示例在语义上与输入接近。
2)kNN-based Retrieval
我们可以从训练集中检索输入序列的k个最近邻(kNN):我们首先计算所有训练示例的向量化表示,然后根据这些向量化表示获取输入测试序列的k个最近邻,并用这k个最近邻作为few-shot prompt中的实例样本。
向量化表示有两种可选的方法,
- kNN based on Sentence-level Representations
要在训练集中找到kNN示例,一种直观的方法是使用文本相似性模型,例如SimCSE:我们首先为训练示例和输入序列获取句子级表示,然后使用余弦相似度找到kNN。
基于句子级表示的kNN的缺点是显而易见的:NER是一个基于标记级别的任务,更关注局部证据,而不是句子级任务。很容易遇到一个问题,即检索到的句子(例如,他是一名士兵)与输入(例如,John是一名士兵)在句子级别上语义上相似,但对于标记输入不提供任何参考帮助。在上面的例子中,检索到的句子不包含NER,因此无法对标记输入提供证据。
- Entity-level Embedding
为了解决上述问题,我们需要基于标记级别的表示而不是句子级别的表示来检索kNN示例。
我们首先使用经过微调的NER标记模型从所有训练示例的所有标记中提取实体级表示作为数据存储。对于长度为N的给定输入序列,我们首先迭代遍历序列中的所有标记,为每个标记找到kNN,得到K×N个检索到的标记。接下来,我们从K×N个检索到的标记中选择前k个标记,并使用它们关联的句子作为示范。
整个过程如下图所示,

我们进行实验来估计示例数量的影响。实验是在100个样本的CoNLL 2003数据集上进行的。结果如下图所示。
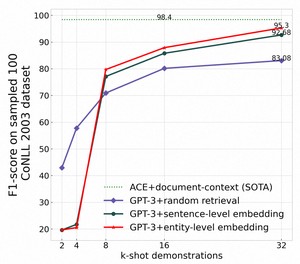
Comparisons by varying k-shot demonstrations.
我们可以观察到,随着k的增加,所有三种基于LLM的结果都在不断上升。当我们接近4096个示例的令牌限制时,结果仍未达到平稳状态。这意味着如果允许更多的示例,性能仍将提高。
有一个有趣的现象观察到,当示例数量较少时,即k = 2、4时,基于kNN的策略表现不如随机检索策略。一种可能的解释如下:基于kNN的检索倾向于选择与输入句子非常相似的演示。因此,如果输入句子不包含任何实体,检索到的示例很可能也不包含实体。在这种情况下,示例不包含我们希望强制执行的输出格式信息,导致LLM输出任意格式。
下面是一个例子: 当示例数量较少且GPT需要识别某种特定类型的实体(例如位置),但少量的示例句子都没有命名实体识别时,GPT会感到困惑,并以自己的格式输出,如下例所示:
参考链接:
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/1492.html