
故事的开头
虽然我们程序员不干爬虫的活,但是工作中确实偶尔有需要网络上的数据的时候,手动复制粘贴的话数据量少还好说,万一数据量大,浪费时间不说,真的很枯燥。
所以现学现卖研究了一个多小时写出了个爬虫程序
新建个Maven项目,导入爬虫工具包Jsoup

首先要拿到我们请求的网页的地址
用Jsoup的parse()方法解析网页,传入连个参数第一个参数是new URL(url),第二个参数设置解析时间如果超过30秒就放弃
然后获取到一个Document对象
之后就像我们操作JS代码一样,Document对象可以实现JS的所有操作
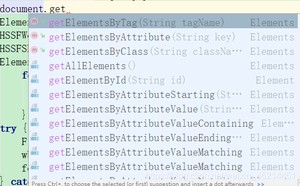
这时候我们用浏览器打开网页,F12审查元素,找到数据所在的div的id名,如果没有id名就用calss名,这里是没有id名的。

然后我们通过class名获取到元素,这时候可以System.out.println(chinajobs);的输出一下看看日否拿到了我们想要的数据

可以看到确实拿到了我们想要的数据

将chinajobs中的第一个元素转换成Element对象(首先要确认我们需要的数据在将chinajobs中的第一个元素中)
通过分析发现我们需要的数据可以在title这个属性中提取出来

输出一下试试
确实过滤到了所有我们想要的数据

最后一步导出到excel,这里我是用的是poi工具包
通过el.getElementsByAttribute(“title”).size()确定元素的数量
采用循环遍历输出
el.getElementsByAttribute(“title”).eq(i)通过eq(i)传入索引值确定元素值
在D盘新建一个上海招聘公司一览表.xls文件
大功告成

版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/1456.html