
本文来自 Kingshion 投稿。欢迎更多朋友参与到 JavaGuide 的维护工作,这是一件非常有意义的事情。详细信息请看:JavaGuide 贡献指南 。
面向对象设计鼓励模块间基于接口而非具体实现编程,以降低模块间的耦合,遵循依赖倒置原则,并支持开闭原则(对扩展开放,对修改封闭)。然而,直接依赖具体实现会导致在替换实现时需要修改代码,违背了开闭原则。为了解决这个问题,SPI 应运而生,它提供了一种服务发现机制,允许在程序外部动态指定具体实现。这与控制反转(IoC)的思想相似,将组件装配的控制权移交给了程序之外。
SPI 机制也解决了 Java 类加载体系中双亲委派模型带来的限制。双亲委派模型虽然保证了核心库的安全性和一致性,但也限制了核心库或扩展库加载应用程序类路径上的类(通常由第三方实现)。SPI 允许核心或扩展库定义服务接口,第三方开发者提供并部署实现,SPI 服务加载机制则在运行时动态发现并加载这些实现。例如,JDBC 4.0 及之后版本利用 SPI 自动发现和加载数据库驱动,开发者只需将驱动 JAR 包放置在类路径下即可,无需使用显式加载驱动类。
SPI 即 Service Provider Interface ,字面意思就是:“服务提供者的接口”,我的理解是:专门提供给服务提供者或者扩展框架功能的开发者去使用的一个接口。
SPI 将服务接口和具体的服务实现分离开来,将服务调用方和服务实现者解耦,能够提升程序的扩展性、可维护性。修改或者替换服务实现并不需要修改调用方。
很多框架都使用了 Java 的 SPI 机制,比如:Spring 框架、数据库加载驱动、日志接口、以及 Dubbo 的扩展实现等等。

那 SPI 和 API 有啥区别?
说到 SPI 就不得不说一下 API(Application Programming Interface) 了,从广义上来说它们都属于接口,而且很容易混淆。下面先用一张图说明一下:
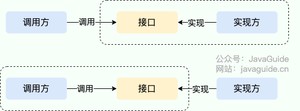
一般模块之间都是通过接口进行通讯,因此我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
- 当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 API。这种情况下,接口和实现都是放在实现方的包中。调用方通过接口调用实现方的功能,而不需要关心具体的实现细节。
- 当接口存在于调用方这边时,这就是 SPI 。由接口调用方确定接口规则,然后由不同的厂商根据这个规则对这个接口进行实现,从而提供服务。
举个通俗易懂的例子:公司 H 是一家科技公司,新设计了一款芯片,然后现在需要量产了,而市面上有好几家芯片制造业公司,这个时候,只要 H 公司指定好了这芯片生产的标准(定义好了接口标准),那么这些合作的芯片公司(服务提供者)就按照标准交付自家特色的芯片(提供不同方案的实现,但是给出来的结果是一样的)。
SLF4J (Simple Logging Facade for Java)是 Java 的一个日志门面(接口),其具体实现有几种,比如:Logback、Log4j、Log4j2 等等,而且还可以切换,在切换日志具体实现的时候我们是不需要更改项目代码的,只需要在 Maven 依赖里面修改一些 pom 依赖就好了。

这就是依赖 SPI 机制实现的,那我们接下来就实现一个简易版本的日志框架。
新建一个 Java 项目 目录结构如下:(注意直接新建 Java 项目就好了,不用新建 Maven 项目,Maven 项目会涉及到一些编译配置,如果有私服的话,直接 deploy 会比较方便,但是没有的话,在过程中可能会遇到一些奇怪的问题。)
新建 接口,这个就是 SPI , 服务提供者接口,后面的服务提供者就要针对这个接口进行实现。
接下来就是 类,这个主要是为服务使用者(调用方)提供特定功能的。这个类也是实现 Java SPI 机制的关键所在,如果存在疑惑的话可以先往后面继续看。
新建 类(服务使用者,调用方),启动程序查看结果。
程序结果:
此时我们只是空有接口,并没有为 接口提供任何的实现,所以输出结果中没有按照预期打印相应的结果。
你可以使用命令或者直接使用 IDEA 将整个程序直接打包成 jar 包。
接下来新建一个项目用来实现 接口
新建项目 目录结构如下:
新建 类
将 的 jar 导入项目中。
新建 lib 目录,然后将 jar 包拷贝过来,再添加到项目中。
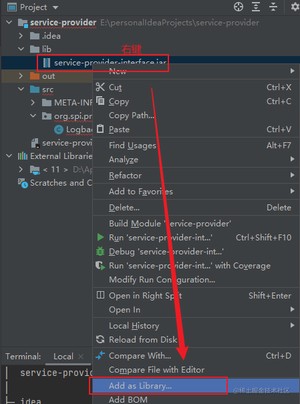
再点击 OK 。
接下来就可以在项目中导入 jar 包里面的一些类和方法了,就像 JDK 工具类导包一样的。
实现 接口,在 目录下新建 文件夹,然后新建文件 (SPI 的全类名),文件里面的内容是: (Logback 的全类名,即 SPI 的实现类的包名 + 类名)。
这是 JDK SPI 机制 ServiceLoader 约定好的标准。
这里先大概解释一下:Java 中的 SPI 机制就是在每次类加载的时候会先去找到 class 相对目录下的 文件夹下的 services 文件夹下的文件,将这个文件夹下面的所有文件先加载到内存中,然后根据这些文件的文件名和里面的文件内容找到相应接口的具体实现类,找到实现类后就可以通过反射去生成对应的对象,保存在一个 list 列表里面,所以可以通过迭代或者遍历的方式拿到对应的实例对象,生成不同的实现。
所以会提出一些规范要求:文件名一定要是接口的全类名,然后里面的内容一定要是实现类的全类名,实现类可以有多个,直接换行就好了,多个实现类的时候,会一个一个的迭代加载。
接下来同样将 项目打包成 jar 包,这个 jar 包就是服务提供方的实现。通常我们导入 maven 的 pom 依赖就有点类似这种,只不过我们现在没有将这个 jar 包发布到 maven 公共仓库中,所以在需要使用的地方只能手动的添加到项目中。
为了更直观的展示效果,我这里再新建一个专门用来测试的工程项目:
然后先导入 的接口 jar 包,再导入具体的实现类的 jar 包。
新建 Main 方法测试:
运行结果如下:
说明导入 jar 包中的实现类生效了。
如果我们不导入具体的实现类的 jar 包,那么此时程序运行的结果就会是:
通过使用 SPI 机制,可以看出服务()和 服务提供者两者之间的耦合度非常低,如果说我们想要换一种实现,那么其实只需要修改 项目中针对 接口的具体实现就可以了,只需要换一个 jar 包即可,也可以有在一个项目里面有多个实现,这不就是 SLF4J 原理吗?
如果某一天需求变更了,此时需要将日志输出到消息队列,或者做一些别的操作,这个时候完全不需要更改 Logback 的实现,只需要新增一个服务实现(service-provider)可以通过在本项目里面新增实现也可以从外部引入新的服务实现 jar 包。我们可以在服务(LoggerService)中选择一个具体的 服务实现(service-provider) 来完成我们需要的操作。
那么接下来我们具体来说说 Java SPI 工作的重点原理—— ServiceLoader 。
想要使用 Java 的 SPI 机制是需要依赖 来实现的,那么我们接下来看看 具体是怎么做的:
是 JDK 提供的一个工具类, 位于包下。
这是 JDK 官方给的注释:一种加载服务实现的工具。
再往下看,我们发现这个类是一个 类型的,所以是不可被继承修改,同时它实现了 接口。之所以实现了迭代器,是为了方便后续我们能够通过迭代的方式得到对应的服务实现。
可以看到一个熟悉的常量定义:
下面是 方法:可以发现 方法支持两种重载后的入参;
其解决第三方类加载的机制其实就蕴含在 中, 就是线程上下文类加载器(Thread Context ClassLoader)。这是每个线程持有的类加载器,JDK 的设计允许应用程序或容器(如 Web 应用服务器)设置这个类加载器,以便核心类库能够通过它来加载应用程序类。
线程上下文类加载器默认情况下是应用程序类加载器(Application ClassLoader),它负责加载 classpath 上的类。当核心库需要加载应用程序提供的类时,它可以使用线程上下文类加载器来完成。这样,即使是由引导类加载器加载的核心库代码,也能够加载并使用由应用程序类加载器加载的类。
根据代码的调用顺序,在 方法中是通过一个内部类 实现的。先继续往下面看。
实现了 接口的方法后,具有了迭代的能力,在这个 方法被调用时,首先会在 的 缓存中进行查找,如果缓存中没有命中那么则在 中进行查找。
在调用 时,具体实现如下:
可能很多人看这个会觉得有点复杂,没关系,我这边实现了一个简单的 的小模型,流程和原理都是保持一致的,可以先从自己实现一个简易版本的开始学:
我先把代码贴出来:
关键信息基本已经通过代码注释描述出来了,
主要的流程就是:
- 通过 URL 工具类从 jar 包的 目录下面找到对应的文件,
- 读取这个文件的名称找到对应的 spi 接口,
- 通过 流将文件里面的具体实现类的全类名读取出来,
- 根据获取到的全类名,先判断跟 spi 接口是否为同一类型,如果是的,那么就通过反射的机制构造对应的实例对象,
- 将构造出来的实例对象添加到 的列表中。
其实不难发现,SPI 机制的具体实现本质上还是通过反射完成的。即:我们按照规定将要暴露对外使用的具体实现类在 文件下声明。
另外,SPI 机制在很多框架中都有应用:Spring 框架的基本原理也是类似的方式。还有 Dubbo 框架提供同样的 SPI 扩展机制,只不过 Dubbo 和 spring 框架中的 SPI 机制具体实现方式跟咱们今天学得这个有些细微的区别,不过整体的原理都是一致的,相信大家通过对 JDK 中 SPI 机制的学习,能够一通百通,加深对其他高深框的理解。
通过 SPI 机制能够大大地提高接口设计的灵活性,但是 SPI 机制也存在一些缺点,比如:
- 遍历加载所有的实现类,这样效率还是相对较低的;
- 当多个 同时 时,会有并发问题。

作者:Hollis
原文:https://mp.weixin..com/s/o4XdEMq1DL-nBS-f8Za5Aw
语法糖是大厂 Java 面试常问的一个知识点。
本文从 Java 编译原理角度,深入字节码及 class 文件,抽丝剥茧,了解 Java 中的语法糖原理及用法,帮助大家在学会如何使用 Java 语法糖的同时,了解这些语法糖背后的原理。
语法糖(Syntactic Sugar) 也称糖衣语法,是英国计算机学家 Peter.J.Landin 发明的一个术语,指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。简而言之,语法糖让程序更加简洁,有更高的可读性。

有意思的是,在编程领域,除了语法糖,还有语法盐和语法糖精的说法,篇幅有限这里不做扩展了。
我们所熟知的编程语言中几乎都有语法糖。作者认为,语法糖的多少是评判一个语言够不够牛逼的标准之一。很多人说 Java 是一个“低糖语言”,其实从 Java 7 开始 Java 语言层面上一直在添加各种糖,主要是在“Project Coin”项目下研发。尽管现在 Java 有人还是认为现在的 Java 是低糖,未来还会持续向着“高糖”的方向发展。
前面提到过,语法糖的存在主要是方便开发人员使用。但其实, Java 虚拟机并不支持这些语法糖。这些语法糖在编译阶段就会被还原成简单的基础语法结构,这个过程就是解语法糖。
说到编译,大家肯定都知道,Java 语言中,命令可以将后缀名为的源文件编译为后缀名为的可以运行于 Java 虚拟机的字节码。如果你去看的源码,你会发现在中有一个步骤就是调用,这个方法就是负责解语法糖的实现的。
Java 中最常用的语法糖主要有泛型、变长参数、条件编译、自动拆装箱、内部类等。本文主要来分析下这些语法糖背后的原理。一步一步剥去糖衣,看看其本质。
我们这里会用到反编译,你可以通过 Decompilers online 对 Class 文件进行在线反编译。
前面提到过,从 Java 7 开始,Java 语言中的语法糖在逐渐丰富,其中一个比较重要的就是 Java 7 中开始支持。
在开始之前先科普下,Java 中的自身原本就支持基本类型。比如、等。对于类型,直接进行数值的比较。对于类型则是比较其 ascii 码。所以,对于编译器来说,中其实只能使用整型,任何类型的比较都要转换成整型。比如。,(ascii 码是整型)以及。
那么接下来看下对的支持,有以下代码:
反编译后内容如下:
看到这个代码,你知道原来 字符串的 switch 是通过和方法来实现的。 还好方法返回的是,而不是。
仔细看下可以发现,进行的实际是哈希值,然后通过使用方法比较进行安全检查,这个检查是必要的,因为哈希可能会发生碰撞。因此它的性能是不如使用枚举进行 或者使用纯整数常量,但这也不是很差。
我们都知道,很多语言都是支持泛型的,但是很多人不知道的是,不同的编译器对于泛型的处理方式是不同的,通常情况下,一个编译器处理泛型有两种方式:和。C++和 C#是使用的处理机制,而 Java 使用的是的机制。
Code sharing 方式为每个泛型类型创建唯一的字节码表示,并且将该泛型类型的实例都映射到这个唯一的字节码表示上。将多种泛型类形实例映射到唯一的字节码表示是通过类型擦除()实现的。
也就是说,对于 Java 虚拟机来说,他根本不认识这样的语法。需要在编译阶段通过类型擦除的方式进行解语法糖。
类型擦除的主要过程如下:1.将所有的泛型参数用其最左边界(最顶级的父类型)类型替换。 2.移除所有的类型参数。
以下代码:
解语法糖之后会变成:
以下代码:
类型擦除后会变成:
虚拟机中没有泛型,只有普通类和普通方法,所有泛型类的类型参数在编译时都会被擦除,泛型类并没有自己独有的类对象。比如并不存在或是,而只有。
自动装箱就是 Java 自动将原始类型值转换成对应的对象,比如将 int 的变量转换成 Integer 对象,这个过程叫做装箱,反之将 Integer 对象转换成 int 类型值,这个过程叫做拆箱。因为这里的装箱和拆箱是自动进行的非人为转换,所以就称作为自动装箱和拆箱。原始类型 byte, short, char, int, long, float, double 和 boolean 对应的封装类为 Byte, Short, Character, Integer, Long, Float, Double, Boolean。
先来看个自动装箱的代码:
反编译后代码如下:
再来看个自动拆箱的代码:
反编译后代码如下:
从反编译得到内容可以看出,在装箱的时候自动调用的是的方法。而在拆箱的时候自动调用的是的方法。
所以,装箱过程是通过调用包装器的 valueOf 方法实现的,而拆箱过程是通过调用包装器的 xxxValue 方法实现的。
可变参数()是在 Java 1.5 中引入的一个特性。它允许一个方法把任意数量的值作为参数。
看下以下可变参数代码,其中 方法接收可变参数:
反编译后代码:
从反编译后代码可以看出,可变参数在被使用的时候,他首先会创建一个数组,数组的长度就是调用该方法是传递的实参的个数,然后再把参数值全部放到这个数组当中,然后再把这个数组作为参数传递到被调用的方法中。(注: 仅在修饰成员变量时有意义,此处 “修饰方法” 是由于在 javassist 中使用相同数值分别表示 以及 ,见 此处。)
Java SE5 提供了一种新的类型-Java 的枚举类型,关键字可以将一组具名的值的有限集合创建为一种新的类型,而这些具名的值可以作为常规的程序组件使用,这是一种非常有用的功能。
要想看源码,首先得有一个类吧,那么枚举类型到底是什么类呢?是吗?答案很明显不是,就和一样,只是一个关键字,他并不是一个类,那么枚举是由什么类维护的呢,我们简单的写一个枚举:
然后我们使用反编译,看看这段代码到底是怎么实现的,反编译后代码内容如下:
通过反编译后代码我们可以看到,,说明,该类是继承了类的,同时关键字告诉我们,这个类也是不能被继承的。
当我们使用来定义一个枚举类型的时候,编译器会自动帮我们创建一个类型的类继承类,所以枚举类型不能被继承。
内部类又称为嵌套类,可以把内部类理解为外部类的一个普通成员。
内部类之所以也是语法糖,是因为它仅仅是一个编译时的概念,里面定义了一个内部类,一旦编译成功,就会生成两个完全不同的文件了,分别是和。所以内部类的名字完全可以和它的外部类名字相同。
以上代码编译后会生成两个 class 文件:、 。当我们尝试对文件进行反编译的时候,命令行会打印以下内容: 。他会把两个文件全部进行反编译,然后一起生成一个文件。文件内容如下:
—般情况下,程序中的每一行代码都要参加编译。但有时候出于对程序代码优化的考虑,希望只对其中一部分内容进行编译,此时就需要在程序中加上条件,让编译器只对满足条件的代码进行编译,将不满足条件的代码舍弃,这就是条件编译。
如在 C 或 CPP 中,可以通过预处理语句来实现条件编译。其实在 Java 中也可实现条件编译。我们先来看一段代码:
反编译后代码如下:
首先,我们发现,在反编译后的代码中没有,这其实就是条件编译。当为 false 的时候,编译器就没有对其内的代码进行编译。
所以,Java 语法的条件编译,是通过判断条件为常量的 if 语句实现的。其原理也是 Java 语言的语法糖。根据 if 判断条件的真假,编译器直接把分支为 false 的代码块消除。通过该方式实现的条件编译,必须在方法体内实现,而无法在整个 Java 类的结构或者类的属性上进行条件编译,这与 C/C++的条件编译相比,确实更有局限性。在 Java 语言设计之初并没有引入条件编译的功能,虽有局限,但是总比没有更强。
在 Java 中,关键字是从 JAVA SE 1.4 引入的,为了避免和老版本的 Java 代码中使用了关键字导致错误,Java 在执行的时候默认是不启动断言检查的(这个时候,所有的断言语句都将忽略!),如果要开启断言检查,则需要用开关或来开启。
看一段包含断言的代码:
反编译后代码如下:
很明显,反编译之后的代码要比我们自己的代码复杂的多。所以,使用了 assert 这个语法糖我们节省了很多代码。其实断言的底层实现就是 if 语言,如果断言结果为 true,则什么都不做,程序继续执行,如果断言结果为 false,则程序抛出 AssertError 来打断程序的执行。会设置$assertionsDisabled 字段的值。
在 java 7 中,数值字面量,不管是整数还是浮点数,都允许在数字之间插入任意多个下划线。这些下划线不会对字面量的数值产生影响,目的就是方便阅读。
比如:
反编译后:
反编译后就是把删除了。也就是说 编译器并不认识在数字字面量中的,需要在编译阶段把他去掉。
增强 for 循环()相信大家都不陌生,日常开发经常会用到的,他会比 for 循环要少写很多代码,那么这个语法糖背后是如何实现的呢?
反编译后代码如下:
代码很简单,for-each 的实现原理其实就是使用了普通的 for 循环和迭代器。
Java 里,对于文件操作 IO 流、数据库连接等开销非常昂贵的资源,用完之后必须及时通过 close 方法将其关闭,否则资源会一直处于打开状态,可能会导致内存泄露等问题。
关闭资源的常用方式就是在块里是释放,即调用方法。比如,我们经常会写这样的代码:
从 Java 7 开始,jdk 提供了一种更好的方式关闭资源,使用语句,改写一下上面的代码,效果如下:
看,这简直是一大福音啊,虽然我之前一般使用去关闭流,并不会使用在中写很多代码的方式,但是这种新的语法糖看上去好像优雅很多呢。看下他的背后:
其实背后的原理也很简单,那些我们没有做的关闭资源的操作,编译器都帮我们做了。所以,再次印证了,语法糖的作用就是方便程序员的使用,但最终还是要转成编译器认识的语言。
关于 lambda 表达式,有人可能会有质疑,因为网上有人说他并不是语法糖。其实我想纠正下这个说法。Lambda 表达式不是匿名内部类的语法糖,但是他也是一个语法糖。实现方式其实是依赖了几个 JVM 底层提供的 lambda 相关 api。
先来看一个简单的 lambda 表达式。遍历一个 list:
为啥说他并不是内部类的语法糖呢,前面讲内部类我们说过,内部类在编译之后会有两个 class 文件,但是,包含 lambda 表达式的类编译后只有一个文件。
反编译后代码如下:
可以看到,在方法中,其实是调用了方法,该方法的第四个参数 指定了方法实现。可以看到这里其实是调用了一个方法进行了输出。
再来看一个稍微复杂一点的,先对 List 进行过滤,然后再输出:
反编译后代码如下:
两个 lambda 表达式分别调用了和两个方法。
所以,lambda 表达式的实现其实是依赖了一些底层的 api,在编译阶段,编译器会把 lambda 表达式进行解糖,转换成调用内部 api 的方式。
一、当泛型遇到重载
上面这段代码,有两个重载的函数,因为他们的参数类型不同,一个是另一个是 ,但是,这段代码是编译通不过的。因为我们前面讲过,参数和编译之后都被擦除了,变成了一样的原生类型 List,擦除动作导致这两个方法的特征签名变得一模一样。
二、当泛型遇到 catch
泛型的类型参数不能用在 Java 异常处理的 catch 语句中。因为异常处理是由 JVM 在运行时刻来进行的。由于类型信息被擦除,JVM 是无法区分两个异常类型和的
三、当泛型内包含静态变量
以上代码输出结果为:2!
对象相等比较
输出结果:
在 Java 5 中,在 Integer 的操作上引入了一个新功能来节省内存和提高性能。整型对象通过使用相同的对象引用实现了缓存和重用。
适用于整数值区间-128 至 +127。
只适用于自动装箱。使用构造函数创建对象不适用。
会抛出异常。
Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 锁。 Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast 原则 Iterator 会马上抛出异常。
所以 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 本身的方法来删除对象, 方法会在删除当前迭代对象的同时维护索引的一致性。
前面介绍了 12 种 Java 中常用的语法糖。所谓语法糖就是提供给开发人员便于开发的一种语法而已。但是这种语法只有开发人员认识。要想被执行,需要进行解糖,即转成 JVM 认识的语法。当我们把语法糖解糖之后,你就会发现其实我们日常使用的这些方便的语法,其实都是一些其他更简单的语法构成的。
有了这些语法糖,我们在日常开发的时候可以大大提升效率,但是同时也要避过度使用。使用之前最好了解下原理,避免掉坑。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/1350.html