
HashMap和Hashtable的区别
一、HashMap简介
HashMap是在JDK1.2中引入的Map的实现类。
1.HashMap是基于哈希表实现的,每一个元素是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
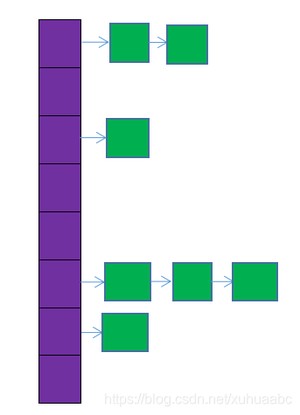
图中,紫色部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
二、Hashtable简介
三.分析二者不同
在hashmap的put方法调用addEntry()方法,假如A线程和B线程同时对同一个数组位置调用addEntry,两个线程会同时得到现在的头结点,然后A写入新的头结点之后,B也写入新的头结点,那B的写入操作就会覆盖A的写入操作造成A的写入操作丢失。
故解决方法就是使用 使用ConcurrentHashMap。
这里要说一下 就是HashMap的迭代器(Iterator)是fail-fast迭代器,故当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException异常,而Hashtable的enumerator迭代器不是fail-fast的。但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
HashMap是没有contains方法的,而包括containsValue和containsKey方法;hashtable则保留了contains方法,效果同containsValue,还包括containsValue和containsKey方法。
Hashmap是允许key和value为null值的,用containsValue和containsKey方法判断是否包含对应键值对;HashTable键值对都不能为空,否则包空指针异常。
为了得到元素的位置,首先需要根据元素的 KEY计算出一个hash值,然后再用这个hash值来计算得到最终的位置。
①:HashMap有个hash方法重新计算了key的hash值,因为hash冲突变高,所以通过一种方法重算hash值的方法:
注意这里计算hash值,先调用hashCode方法计算出来一个hash值,再将hash与右移16位后相异或,从而得到新的hash值。
②:Hashtable通过计算key的hashCode()来得到hash值就为最终hash值。
它们计算索引位置方法不同:
HashMap在求hash值对应的位置索引时,。将哈希表的大小固定为了2的幂,因为是取模得到索引值,故这样取模时,不需要做除法,只需要做位运算。位运算比除法的效率要高很多。
HashTable在求hash值位置索引时计算index的方法:
&0x7FFFFFFF的目的是为了将负的hash值转化为正值,因为hash值有可能为负数,而&0x7FFFFFFF后,只有符号位改变,而后面的位都不变。
当容量不足时要进行resize方法,而resize的两个步骤:
①扩容;
②rehash:这里HashMap和HashTable都会会重新计算hash值而这里的计算方式就不同了(看5);
HashMap 哈希扩容必须要求为原容量的2倍,而且一定是2的幂次倍扩容结果,而且每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入;
而Hashtable扩容为原容量2倍加1;
先看jdk8之前:
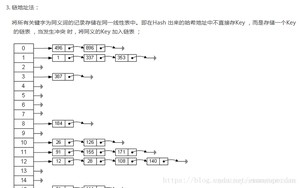
查找时间复杂度慢慢变高;
Java8,HashMap中,当出现冲突时可以:
而在HashTable中, 都是以链表方式存储。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/11967.html