
RapidXml尝试创建最快的XML解析器,同时保留可用性,可移植性和合理的W3C兼容性。它是一个用现代C ++编写的原位解析器,解析速度接近strlen在同一数据上执行的函数。它仅仅只由四个头文件组成,并不要单独进行配置编译,使用起来非常方便。
在RapidXml的官网上,它发布了与其他xml解析库的速度对比,应该可以说RapidXml是目前最快的xml解析器。
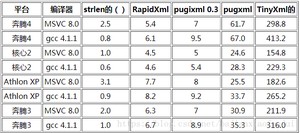
RapidXml通过使用以下几种技术实现了它的速度:
1,原位解析。构建DOM树时,RapidXml不会复制字符串数据,例如节点名称和值。相反,它存储指向源文本内部的指针。
2,使用模板元编程技术。这允许它将大部分工作转移到编译时。通过模板的魔力,C ++编译器为您使用的任何解析器标志组合生成解析代码的单独副本。在每个副本中,所有可能的决定都在编译时进行,并且省略所有未使用的代码。
3,广泛使用查找表进行解析。
4,手动调优的C ++,在几个最流行的CPU上进行了分析。
我们以下面这个xml为例,找到key值为"ReportIndex"的节点,并在这个节点前面插入一个新的节点"",同时将key值为"ReportIndex"的节点以及后面的节点的offset值都加上4。
CXmlParse解析类的头文件如下:
cpp实现文件:
RapidXml遍历节点跟TinyXml遍历节点的方式一样,都是先获取根节点,然后获取到根节点下方的first_node(),然后通过next_sibling()不停地指向下一个兄弟节点,同时兄弟节点也可以深度去遍历。获取节点的各个属性值也是一样的使用方式。
本程序为了和原xml文件作对比,就创建了新的文件,如果想在原文件上做修改,直接将std::ofstream out(m_strNewPath);中的m_strNewPath替换为m_strPath即可。
类封装好后,调用也非常方便。
附上完整例子代码:Demo
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/11824.html