
对称密钥加密概述
通讯双方预先共享某种秘密信息(密钥,或称对称密钥 symmetric key)。发送方采用密钥来加密信息,接收方通过相同的密钥来解密信息。消息本身称为明文(plaintext),加密后的消息成为密文(ciphertext).
对称密钥的应用,至少需要一个基础:key本身的传递是秘密的。这限制了对称加密的应用场景。当然,在之后,通过 Diffie-Hellman 密钥协商机制(透过不安全的信道,协商出只有双方知道的一个数),可以部分地解决这个问题。
对称密钥方案由三个部分组成:密钥产生、加密、解密。
- 密钥产生算法 :是一个概率算法,能从方案所定义的分布里面选一个密钥 $k$ 出来。
- 加密算法 :输入密钥 $k$ 和明文 $m$,输出密文 $c = ext{Enc}_k(m)$.
- 解密算法 :输入密钥 $k$ 和密文 $c$,输出明文 $m = ext{Dec}_k(c)$.
输出的所有可能值,构成了密钥空间 $mathcal{K}$. 我们上面声称它是从方案所定义的分布里面取密钥,实际上一般情况下可以假设这个分布是均匀的。
所有能作为 输入的信息构成了明文空间 $mathcal{M}$. 显然,$langle mathcal{K,M} angle$ 唯一定义了密文空间 $mathcal{C}$,也就是所有可能出现的密文。
由此我们知道,一个对称加密算法,可以由三个算法 $( ext{Gen, Enc, Dec})$ 以及明文空间 $mathcal{M}$ 来定义。显然,若一个对称加密算法是有效的,必须满足 是 的逆运算,亦即 $$ ext{Dec}_k( ext{Enc}_k (m) ) = m, uad forall m in mathcal{M}$$
对称加密方案的工作流程如下:首先,运行 来得到密钥,通讯双方得知密钥;当发送方需要发出消息时,计算 $c := ext{Enc}_k(m)$,然后可以透过公开的信道发送 $c$. 接收方收到 $c$ 之后,计算 $m:= ext{Dec}_k(m)$,即可恢复原信息。
Kerckhoffs 原则
柯克霍夫原则要求,一个加密方案的安全性,仅取决于密钥的安全性,而不取决于算法的秘密。接受 Kerckhoffs 原则会带来很多好处:首先,由于加密算法是公开的,通讯各方只需要保密密钥(这显然比加密算法要短,按常理来讲,越短的东西越容易保密)。另外,如果密钥泄露了,双方只需要改个新的密钥就能继续安全通信(若不遵循 Kerckhoffs 原则,一旦泄露算法就需要重新设计加密方案)。最后,遵循 Kerckhoffs 原则可以带来标准化的好处:多人通讯时,可以采用相同的算法而选择不同的密钥,这样程序可以复用。
密码学的攻击场景
我们把攻击的严重程度由高到低归类(当然,攻击难度也依次递减):
- 唯密文攻击(Ciphertext-only Attack, COA). 敌方观察到一个或多个密文,试图确定明文。
- 已知明文攻击(Known-plaintext Attack, KPA). 地方已知一个或多个使用相同密钥加密的明文-密文对。攻击目标是,对于其他密文,可以确定明文。
- 选择明文攻击(Chosen-plaintext attack, CPA). 敌方可以选择明文要求加密,并得到加密结果。攻击目标同上。
- 选择密文攻击(Chosen-ciphertext attack, CCA). 敌方可以选择密文要求解密。攻击目标同上。
当今,被广泛应用的密码方案,未必能对抗以上四种攻击(尤其是CCA)。对于特定的应用场景,需要兼顾安全性和效率。
古典密码:Caesar
凯撒密码企图通过字母代换达到加密的目的。也就是说:
- $ ext{Gen}$ 输出一个 $[0, 25]$ 范围的随机数 $k$.
- $ ext{Enc}_k(m) equiv (m + k) pmod {26}$.
- $ ext{Enc}_k(c) equiv (c - k) pmod {26}$.
显然,只需要枚举密钥 $k$,就能获得 26 个候选明文,从而判断真正的明文。
充分密钥空间原则
根据当前计算机的计算能力,密钥空间需要非常大,例如$2^{70}$.
需要注意的是,满足充分密钥空间原则的加密方案,未必就是安全的。来看下面的例子。
古典密码:单表代换 / 单字母替换
单字母替换(substitution)为每一个明文字母指派了一个密文字母。显然,$mathcal{K}$ 的大小是 $26! approx 2^{88}$,这是符合充分密钥空间原则的。然而,通过我们关于明文的统计知识,单表替换密码很容易被攻破。
一个正常的英文文本,每个字符的概率分布是已知的。文本越长,这个现象越显著(亦即,各个字母的出现频率越接近标准的英文字母频率)。从而可以快速猜测密码。
IoC 可以将这一判断过程自动化。
index of coincidence (IoC,重合因子)
英文的字频统计规律,在单表替换之后会错位。但我们考虑另一种统计方式:若每个字母的出现概率是 $p_i$,那么对于普通的英文文本,不难计算出 $$sum p_i^2 approx 0.065$$
判断一个串是否由英文单表替换而来:现在假设我们想要判断一个代换之后的串,在代换之前是否满足英文字母频率,那么我们记代换后字频为 $q_i$,它的集合显然与 $p_i$ 的集合相同。从而有 $$sum q_i^2 approx sum p_i ^2 approx 0.065$$
否则,若 $q_i$ 是随机的,那计算结果应该约为 $0.038$.
判断一个单表替换方案是否合适:假设我们认为明文的字母 $i$ 对应密文的字母 $s_i$. 那么,如果这个替换方案是正确的,则解密之后得到的明文,必然满足英文字母分布频率。亦即: $$sum p_i cdot q_{s_i} approx sum p_i^2 approx 0.065$$
Vigenere 密码
维吉尼亚密码是多表代换密码。它循环使用一个 key 表,对于每一个明文字母,加上 key 得到密文。显然,维吉尼亚密码的本质,即是用 Caesar 方法加密明文的第 $i, i+t, i+2tcdots$ 这些位置。
攻击维吉尼亚密码,一般先找到 key 长度,再确定 key. 要判断 key 长度,可以采用 Kasiski 方法:若一个串在密文中多次出现,则有很大概率它们由相同的明文加密而来;在这种情况下,一对重复串之间的距离,很大概率是 key 长度的倍数。于是可以判断 key 长度。
笔者更喜欢 Ioc 方法:首先猜测密文长度 $t$,要验证是否确实如此,只需要取出密文的 $i, i+t, i+2tcdots$ 这一共 $t$ 组加密结果。第 $i$ 组是由 key 的第 $i$ 位通过 Caesar 加密而来,故每一组的字频平方和(IoC)应该约等于 $0.065$. 找到最符合这个要求的 $t$,即为 key 长度,或者 key 长度的倍数。
在知道 key 长度之后,可以把密文划分为 $t$ 组,每组都是一个 Caesar。拿去字频分析即可,这一步也可以采用 IoC 方法,见上文的【判断一个单表替换方案是否合适】。
上述针对 Caesar 和 vigenere 的攻击都是唯密文攻击。vigenere 比 Caesar 稍微安全一些,但是仍然被频率分析方法攻破。我们意识到,通过简单的手段达到安全是不太现实的。
现代密码学的基本原则
我们提出密码学的三个主要原则:
- 对“安全”的定义必须是公式化的、表述严格且精确的。
- 若密码学方案的安全性依赖于某个未被证明的假设,这种假设必须精确陈述,且假设需要尽可能少。
- 密码学方案应该有严格的安全证明。
原则一:对安全的定义
把安全定义为“攻击者不能计算出密钥”是不行的。反例:$ ext{Enc}_k(m) := m$,没有任何人可以从 $c$ 里面猜出 $k$,但明文已经泄露干净了。把安全定义为“攻击者不能计算出明文”也是不行的,反例:加密算法只加密明文的前100个字节,后面部分原样输出。攻击者不能计算出明文,但显然这个加密方案是不安全的。把安全定义为“攻击者不能得知明文的任何一个字节”也是不太行的,若攻击者虽然不能得知明文的任何一个字节,但可以得知某些关键信息(例如,在一份加密的雇佣合同中,攻击者得知这个打工人的工资是大于1000块还是小于1000块),这也是不安全的。
一个合适的定义:若敌手无法从密文中计算出任何关于明文的函数,那么加密方案是安全的。也就是说,$key$未知的条件下,密文中不包含有明文的任何信息。这个对安全的定义,称为无条件安全。然而实践上,大部分的密码体系都达不到无条件安全的级别。
原则二:精确的假设
大部分密码方案达不到无条件安全。许多密码方案对这个问题做了让步——安全性依赖于某种假设。现代密码学要求,若一个方案的安全性依赖于假设,则假设必须被精确地陈述。
假设是暂无数学证明的、但据推测是正确的命题。例子:“大整数分解是无法在多项式时间内完成的”。
原则三:严格的安全证明
大部分的密码学安全证明采用了规约方法,也就是说,给出了定理:“若假设 X 是正确的,根据给定的定义,构造方案 Y 是安全的”。证明通常是展示如何将 X 归约到“攻破 Y”. 也就是说,假设敌手能攻破 Y,那么将会与 X 冲突。
$defGen{{ extsf{Gen}}} defEnc{{ extsf{Enc}}} defDec{{ extsf{Dec}}} defEnck{{ extsf{Enc} _ k}} defDeck{{ extsf{Dec} _ k}} defKK{{mathcal{K}}} defMM{{mathcal{M}}} defCC{{mathcal{C}}} defAA{{mathcal{A}}} defPrivK{{ extsf{PrivK}}} defeav{{ extsf{eav}}} defPrivKeav{{PrivK^eav}} $
一些定义
我们沿用之前讨论过的 Gen, Enc, Dec 三元组来定义加密方案。密钥产生算法 Gen 是概率的,每次运行会从 $mathcal{K}$ 里面选一个输出(这个 $KK$ 显然是有穷集)。加密算法 Enc 可能是概率的,也就是说 $Enck(m)$ 多次运行可能输出不同的密文。但是 Dec 是确定的。
约定一下符号:我们用 $c leftarrow Enck(m)$ 表示这是概率过程,用 $c := Enck(m)$ 表示 Enc 是确定的。
$KK$ 和 $MM$ 的分布是独立的。也就是说,密钥的选择与明文的选择互相独立。另外,$KK$ 的分布一般是由加密方案本身决定,但 $MM$ 的分布与这个加密方案的使用者有关。
现在,我们来定义完善保密加密的概念。假设敌手知道 $MM$ 的概率分布(priori,先验分布),也就是说敌手知道发送各种消息的可能性(例如,发送“下雨”的概率是30%,发送“晴天”的概率是70%)。在理想的情况下,敌手从密文中不会学习到任何知识,亦即在密文已知的情况下,明文的分布(posteriori,后验分布)应该与先验分布相同。这意味着,密文没有泄露任何明文信息。形式化的表述如下:
明文空间为 $MM$ 的加密方案 $(Gen, Enc, Dec)$ 是完善保密加密,当且仅当对于 $MM$ 上任意的概率分布,$forall min MM, cin CC$ 且 $Pr[C=c]>0$,有 $$Pr[M=mmid C=c] = Pr[M=m]$$
这个式子就是描述了“后验概率等于先验概率”。另一种等价的解释是:当且仅当明文和密文的分布是独立的,方案才是完善保密加密。
一个等价的公式:$$Pr[C=cmid M=m] = Pr[C=c]$$
也就是说,若密文的先验概率等于后验概率,则方案也是完善保密加密。现在我们证明这与原来的公式等价。
完美不可区分性
完善保密加密还有一个等价的表述:$CC$ 的分布独立于明文。亦即,用 $CC(m)$ 表示加密 $min M$ 时的密文分布(它取决于密钥的选择、加密算法),那么 $CC(m_0)$ 与 $CC(m_1)$ 的分布是相同的。我们称此为完美不可区分性,因为不可能区分 $m_0$ 的密文与 $m_1$ 的密文(因为它们的分布是一样的)。
明文空间为 $MM$ 的加密方案 (Gen, Enc, Dec) 是完善保密加密,当且仅当对于任意 $MM$ 的概率分布,每个 $m_0, m_1in MM$ 和每个 $cin CC$,均有 $$Pr[C=cmid M=m_0] = Pr[C=cmid M=m_1]$$
必要性:若方案是完善保密加密,那么它一定满足完美不可区分性。因为 $$Pr[C=cmid M=m_0] = Pr[C=c] = Pr[C=cmid M=m_1]$$
敌手不可区分性
这是完善保密加密的又一个等价定义。它基于一个涉及敌手 $AA$ 的实验,断言“$AA$ 不能区分出密文是来自哪个明文”,故称为敌手不可区分性。
考虑任意加密方案 $Pi=(Gen, Enc, Dec)$,任意敌手为 $AA$. 用 $PrivKeav$ 表示一个给定 $Pi$ 和 $AA$ 的实验。实验的定义如下:
窃听不可区分实验 $defPrivKA{{PrivK ^ eav_{AA, Pi}}} PrivKA $ :
1. 敌手 $AA$ 输出一对信息 $m_o, m_1 in MM$.
2. 由 $Gen$ 产生一个随机密钥 $k$,并且从 ${0, 1}$ 里面随机选择一个比特 $b$. 然后,计算密文 $cleftarrow Enck(m_b)$ 交给 $AA$.
3. $AA$ 输出一个比特 $b ^prime$.
4. 若 $b ^ prime = b$,定义实验的输出为 $1$;否则为 $0$. 若输出为 1,记为 $PrivKA = 1$,此时称 $AA$ 成功。
也就是说,$AA$ 的任务是尽可能猜出密文从哪个明文加密而来。显然,如果它随机猜测,有 50% 的概率成功。完善保密加密的另一种定义是:如果没有敌手能以大于 0.5 的概率成功,那么这种加密方案就是完善保密加密。注意这里 $AA$ 的计算能力没有限制。
方案 (Gen, Enc, Dec) 为完善保密加密,当且仅当对于所有敌手都满足 $$Pr[PrivKA = 1] = frac12$$
$deflb{{{}} def b{{}}}$
一次一密
一次一密方案定义如下:
令整数 $l>0$,设 $MM,KK,CC = lb 0, 1 b ^ l$.
Gen 从 $KK = lb 0,1 b ^ l$ 里面按均匀分布选取一个二进制串。
$Enck(m)$:输出 $c:= koplus m$
$Deck(c)$:输出 $m:= koplus c$
这个方案是完善保密加密,因为给定 $c$,敌手完全无法判断来自哪个 $m$. 密钥 $k$ 对敌手而言是未知的,且选中的概率一样高;对攻击者而言,明文与密钥是一一对应,故对攻击者而言,这个 $c$ 来自所有明文的概率都均等。下面给一个严格证明。
$$forall c, m:quad Pr[C=cmid M=m] = Pr[Moplus K = c mid M=m] = Pr[moplus K = c] = Pr[K = moplus c] = frac1{2^l}$$
从而 $P(cmid m_0) = P(cmid m_1)$. 证毕。
尽管一次一密理论上是完善保密加密的,但需要密钥与明文长度相同,这会导致通讯双方需要交换一个很长的密钥。另外,一次一密仅在密钥只使用一次的情况下是安全的,若攻击者截获两条用相同密钥加密的密文,则密文异或等于明文异或,这会泄露明文信息。
完善保密的局限性
上述的问题不仅是 Vernam 这一个方案的问题。所有的完善保密加密,密钥空间都不小于明文空间。
设 (Gen, Enc, Dec) 是完善保密加密方案,则 $|KK| geq |MM|$.
证明如下:若不然,则考虑攻击者截获到一个密文 $c$. 考虑攻击者利用所有的 $k$ 尝试解密,解密结果形成了集合 $MM(c)$. 显然 $|MM(c)| leq |MM|$,于是存在一些 $m_xin M$,却不在 $MM(c)$ 里面。于是,攻击者断言 $Pr[M=m_x mid C=c] = 0$,于是违背了完善保密加密。
香农定理
香农提出了完善保密加密的一种性质:若 $|KK| = |MM| = |CC|$,则 Gen 必须均匀随机选择 $k$,且对于任意明文、任意密文,存在唯一的 $k$ 来把这个明文加密成这个密文。
(香农定理)设加密方案 (Gen, Enc, Dec) 的明文空间为 $MM$,且 $|KK| = |MM| = |CC|$,则当且仅当下列条件成立时,此方案是完善保密加密:
1. Gen 产生任何密钥的概率都是 $1/|KK|$
2. 对任意 $min MM, cin CC$,存在唯一的密钥 $kinKK$,使得 $Enck(m) = c$
不难看出,香农定理的结论非常强。应用香农定理时,需要注意 $KK, MM, CC$ 必须大小相等。
若干定义
在上一章我们讨论了“假设敌手有无限的计算能力”情形下的密码学,这样的方案称为“信息理论安全”或“完美安全”,它们的安全性基于敌手没有足够的信息来完成攻击,而不管敌手的计算能力。
计算安全是更为可行的方案。它使得攻击者无法在可以接受的时间内完成攻击,从而达到实用的密码学目标。计算安全一般是这样的形式:
一个方案为 $(t, varepsilon)$ 安全,如果每个运行时间最多为 $t$ 的敌手以最多 $varepsilon$ 的概率成功攻破方案。
举个例子:某方案保证,在最多运行 $2^{80}$ 个 CPU 周期的情况下,没有人能以高于 $2^{-64}$ 的概率攻破方案。这显然提供了很高的安全性。
在接下来的内容中,我们采用渐进方法来研究。把敌手的运行时间和成功概率视为(关于某个参数的)函数,而不是具体数值。一个密码方案包含一个安全参数 $n$,双方生成密钥时,采取 $n$ 作为安全参数,敌手也知道这个 $n$,则敌手的运行时间和成功概率,都可以视为 $n$ 的函数。
这将帮助我们研究两个概念:
- “有效的算法”,其运行时间应该是 $n$ 的多项式级别。我们把多项式时间内运行的概率算法称为概率多项式算法。概率多项式时间简写为 PPT.
- “小的成功概率”,应该比任何关于 $n$ 的多项式的倒数级别更小。也就是说,$forall c$,当 $n$ 的值足够大,敌手成功的概率小于 $frac{1}{n ^ c}$. 比任何多项式的倒数都增长得慢的函数,称为可忽略的(negligible). 一个典型例子是,$2^{-n}$ 比任何多项式的倒数都增长得慢。
于是,渐进安全的定义一般采用下面的形式:
如果每一个 PPT 敌手攻破一个方案的概率是可忽略的,则方案是安全的。
举一个例子:一个方案可能保证,多项式运行时间的敌手,攻破方案的概率是 $2^{-n}$. 显然,$n=10$ 的时候几乎无法保证任何安全性,但 $n=100$ 的时候很安全。
更大的安全参数,提供了更高的安全性。很多加密方案采用密钥长度作为安全参数。
有效的算法
一个算法 A 在多项式时间内运行,当且仅当存在一个多项式 $p(cdot)$,使得对于每个输入 $xin lb 0, 1 b^*$,$A(x)$ 的计算在最多 $p(|x|)$ 个步骤内终止。
一个概率多项式时间(PPT)算法,是在多项式时间算法的基础上,还允许算法获取到随机数。
一个多项式时间算法,可以调用多项式时间的子算法。
需要注意的是,目前认为,概率多项式时间的敌手,未必一定比确定性的多项式时间敌手更强大。不过我们在这里把我们的对手建模成概率多项式的,提供只可能更强、不可能更弱的保证。
可忽略的成功率
设 $p$ 为某多项式。如果敌手攻破方案的概率是 $1/p(n)$ 级别,那么我们认为这是不安全的。如果敌手攻破方案的概率比每一个多项式还(渐进地)小,那我们认为方案安全。定义如下:
我们把一个可忽略函数表示为 negl,例如 $2^{-n}, 2^{-sqrt n}, n^{-log n}$ 都是可忽略的。
可忽略函数也有着闭包特性。
这意味着,一个可忽略概率的事件,重复实验多项式次,其发生的概率还是可忽略的。
如果一个攻破密码方案的事件发生概率是 negl,则是不重要的。
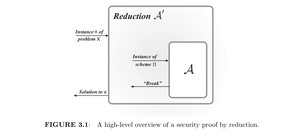
规约证明
许多方案依赖于假设(某难题难以攻破)的正确性。对它们的证明,一般方式如下:说明如何将任何概率不可忽略的攻破该方案的有效敌手 $AA$,转换为能用来成功解决该难题的敌手 $AA^prime$. 公式化地,步骤如下:
- 指定某个 PPT 敌手 $AA$ 来攻击 $Pi$. 将敌手的成功概率表示成 $varepsilon(n)$.
- 构造一个 PPT 算法 $AA^prime$,这个算法调用 $AA$,试图解决难题 $X$. 在这里,$AA^prime$ 将子程序 $AA$ 视为一个黑盒。$AA^prime$ 接受问题 $X$ 的输入,然后模拟出 $Pi$ 的环境,调用 $AA$;如果 $AA$ 成功攻破了由 $AA^prime$ 模拟出来的 $Pi$ 实例,则 $AA^prime$ 解决难题 $X$,成功率不可忽略(i.e. 至少为多项式的倒数)。
- 如果 $varepsilon(n)$ 是不可忽略的,则 $AA^prime$ 解决 $X$ 的概率也是不可忽略的。这与原假设矛盾,故完成证明,断言 $Pi$ 是计算安全的。
计算安全的加密
现在,我们来重新定义对称密钥加密的语法。现在我们有了安全参数可以用,默认消息空间是二进制串。
一个对称密钥加密方案是 PPT 算法 (Gen, Enc, Dec) 的三元组。
1. 密钥生成算法 Gen 的输入是安全参数 $1^n$,输出密钥 $k$. 记为 $kleftarrow Gen(1 ^ n)$
2. Enc 将密钥 $k$ 和明文 $min lb 0,1 b ^ *$ 作为输入,并输出密文 $c$. 记为 $c leftarrow Enck(m)$
3. Dec 将 $k,c $ 作为输入,输出消息 $m$. 它是确定性的,记为 $m := Deck(c)$
另外,需要满足 $Deck(Enck(m)) = m$.
若 (Gen, Enc, Dec) 满足:对每个由 $Gen(1^n)$ 输出的密钥 $k$,算法 $Enck$ 只对消息 $min lb 0,1 b ^ {ell(n)}$ 有定义,则 (Gen, Enc, Dec) 是一个消息长度为定长 $ell(n)$ 的对称密钥加密方案。
窃听不可区分实验
我们之前已经建立起敌手不可区分实验,来等价地描述完善保密加密。现在,为了描述计算安全,我们也定义一个实验。这个实验相比起之前的实验,只考虑PPT敌手;要求敌手判断正确的概率大于0.5的程度是 negl 的。
另外,为了方便,我们要求信息 $m_0, m_1$ 相等。
窃听不可区分实验 $PrivKA(n)$:
1. 给定输入 $1^n$ 给敌手 $AA$,$AA$ 输出一对长度相等的信息 $m_0, m_1$.
2. 运行 $Gen(1 ^ n)$ 生成一个密钥 $k$,选择一个随机比特 $b$,计算 $defla{{leftarrow}} cla Enck(m _ b)$ 并交给 $AA$. 这里的 $c$ 称为 挑战密文。
3. $AA$ 输出一个比特 $b^ prime$.
4. 若 $b=b ^ prime$,则实验输出为 1;否则为 $0$. 若 $PrivKA(n) =1$,则称 $AA$ 成功。
上面只限制了挑战明文的长度相等。如果是分析定长的加密方案,则添加约束条件,要求 $m_0, m_1$ 长度等于 $ell(n)$.
接下来,我们就可以利用窃听不可区分实验,来定义计算安全性:如果在上面的实验中,任何 PPT 敌手的成功概率高于 0.5 的部分可忽略,则这个加密方案是安全的。
如果对于所有 PPT 敌手 $AA$,存在一个可忽略函数 $def egl{{ extsf{negl}}} egl$ 使得 $$Pr[PrivKA(n) = 1] leq frac12 + egl(n)$$ 则对称加密方案 $Pi=(Gen, Enc, Dec)$ 是 在窃听者存在的情况下不可区分的加密。
之所以称之为“窃听者存在情况下”,是因为 $AA$ 只能收到单个挑战密文,与发送方没有更多的交互。这也就是说,$AA$ 只有窃听的能力。
语义安全
对于一个对称密钥方案 $(Gen, Enc, Dec)$,若对于所有 PPT 敌手 $AA$,存在一个 PPT $defAAp{{AA ^ prime}} AAp$,使得对于所有有效可采样的分布 $X=(X _ 1, cdots)$ ,以及所有多项式时间可计算的函数 $f, h$,存在一个可忽略函数 $ egl$ 满足 $$left | Pr[AA(1 ^ n, Enck(m), h(m) ) = f(m)] -Pr[AAp (1 ^ n, h(m)) = f(m)] ight | leq egl(n)$$ 则称其为 窃听者存在的情况下是 语义安全的。
上面的公式中,$h(m)$ 可以代表对 $m$ 的先验知识。如果一个方案是语义安全的,那么拥有密文的 $AA$ 并不比没有密文的 $AAp$ 高明(具体而言,在猜测某个关于 $m$ 的函数时,正确率是相等的),说明密文本身没有泄露关于明文的任何信息。
不难发现,语义安全是非常强的安全性。但其定义十分复杂,难以直接利用。但我们可以将之转化为窃听不可区分实验:
一个对称密钥加密方案,具备窃听者存在情况下的 不可区分性,当且仅当它在窃听者存在的情况下 语义安全。
从而,我们只需要证明一个加密算法是窃听者不可区分的,就能证明它是语义安全的。这大大简化了我们的工作。
伪随机性
一个伪随机的字符串,是看起来很像真正取自均匀分布的字符串(前提是,这个“看”的过程实在多项式时间内运行)。如果说一个长度为 $l$ 的字符串的分布 $defDD{{mathcal{D}}} DD$ 是伪随机的,那么意味着 $DD$ 与均匀分布是不可区分的。更准确地说:对于任何多项式时间算法,分辨出一个字符串是 $DD$ 的样本还是均匀分布的样本,是不可行的。
关于伪随机性在密码学中的作用,有一个直观的例子:考虑一个加密方案,如果密文是伪随机的,则在任何 PPT 敌手的角度上看,这个密文与真正的随机串没有任何区别:从而不会携带关于明文的任何信息。
伪随机发生器(PRG)
如果没有多项式时间的区分器能把一个 $DD$ 的样本与一个真随机的字符串区分开来,则这个分布 $DD$ 是伪随机的。一个伪随机发生器是一个确定性算法,接受一个较短的种子,将其扩展成为一个长的伪随机字符串。
令 $ell(cdot)$ 为多项式,令 $G$ 为确定多项式时间算法。这个算法满足:对于任何输入 $defb{{lb 0, 1 b}} defbn{{lb 0, 1 b ^ n}} sin bn$,$G$ 输出一个长度为 $ell(n)$ 的字符串。如果满足下面的两个条件,则称 $G$ 是一个伪随机发生器:
1. 扩展性:对于每个 $n$,有 $ell(n) > n$.
2. 伪随机性:对于所有的 PPT 区分器 $defDD{{mathcal{D}}} DD$ 来说:$$Big|Pr[D(r) = 1] - Pr [D(G(s)) =1] Big| leq egl(n)$$ 其中 $r$ 是从 $b ^ {ell(n)}$ 中均匀随机选择的;$s$ 是从 $bn$ 中均匀随机选择的。
可见,一个 PRG 接受短的种子,扩充到 $ell(n)$ 位长度,且对于任何 PPT 来说,无法区分“随机种子的 PRG 的输出”与“真随机串”。我们称 $ell(cdot)$ 为 $G$ 的扩展系数。
由于 $n$ 往往比 $ell(n)$ 小很多,故 PRG 实际能输出的数的个数,要远远少于 $b ^ {ell(n)}$. 这样来看,如果敌手的计算能力是无限的,那他可以不停地运行 PRG 来得到 PRG 所能产生的比特串的表,然后对于所有在表里的就输出 1;不在表里的就输出 0. 最终成功率会相当高。
伪随机数是真随机数在计算能力上的松弛。正因为敌手没有无限的计算能力,伪随机数才能骗过所有的 PPT 敌手。
显然,一个伪随机数发生器的种子,必须均匀选取,对区分器保密。另外,实践上,种子应该足够长,使得攻击者没办法在可行时间内暴力枚举所有种子。
目前,我们还不知道伪随机发生器是否真的存在。但我们倾向于认为存在,而且已经造出了许多在现实生活中可用的发生器。
用 PRG 构造定长加密方案
首先,令 $G$ 是一个扩展因子为 $ell$ 的PRG. 构造加密方案如下:
- Gen:随机选择 $k in bn$
- Enc: $c := G(k) oplus m$
- Dec: $m := G(k) oplus c$
也就是把一次一密方案修改一下,用于异或的流改用 PRG 来生成。密文、明文的长度都是 $ell(n)$.
现在我们来证明它是语义安全的,亦即窃听不可区分的。
考虑任意的 PPT 敌手 $AA$,定义 $defeps{{varepsilon}} eps$:$$eps(n) riangleq Pr[PrivKA(n) = 1] - frac12$$
显然,如果 $AA$ 能攻破 $Pi$(可以判断出密文来源),那么 $eps(n)$ 是不可忽略的,反之亦然。
接下来,我们构造一个针对 $G$ 的区分器 $DD$ 如下:
$DD$ 获取到输入 $ defbln{b ^ {ell(n)}} win bln$,然后 $DD$ 进行如下操作:
- 运行 $AA(1 ^ n)$,$AA$ 产生一对消息 $m_0, m_1$ 交回给 $DD$.
- $DD$ 随机选择一个比特 $b$,令 $c := w oplus m_b$.
- 把 $c$ 发给 $AA$,$AA$ 猜测 $c$ 是源于 $m_0$ 还是 $m_1$,将猜测结果 $defbp{{b ^ prime}} bp$ 交给 $DD$. 如果 $bp = b$,则 $DD$ 输出 1;否则输出 0.
现在,我们来分析这个 $DD$ 的行为。一共只有两种可能:
如果 $w$ 是随机选择的,此时 $AA$ 完全等同于做了一次一密,从而 $def Pi{{widetildePi}}Pr[DD(w) = 1] = Pr[PrivK ^ {eav} _ {AA, Pi} = 1] = frac12$,其中 $ Pi$ 是长度为 $ell(n)$ 的一次一密方案。
如果 $w$ 是取自伪随机发生器的,则此时 $AA$ 的行为完全与题设中的 $Pi$ 一致——加密方案是异或上 $G(k)$,故 $AA$ 的成功概率是 $frac12 + eps(n)$. 此时 $$Pr[D(w) = 1] = Pr[D(G(k)) = 1] = Pr[PrivKA(n) = 1] = frac12 + eps(n)$$
综上,我们得到 $Big | Pr[D(w) = 1] - Pr[D(G(k)) = 1] Big |= eps(n)$,按照 PRG 的性质,$eps(n) = egl$,从而 $AA$ 无法攻破 $Pi$,故 $Pi$ 是语义安全的。
处理变长信息
我们显然很希望造出一共伪随机发生器,来生成任意长度的比特流。具体而言,我们希望变长 PRG 接受两个输入:种子 $s$ 和长度 ell$,然后 $G$ 输出一个长度为 $ell$ 的伪随机字符串。
一个确定的多项式时间算法 $G$,如果满足以下三个条件,则它是一个输出长度可变的伪随机发生器:
- 令 $s$ 是一个字符串,$ell > 0$. 则 $G(s, 1 ^ ell)$ 输出一个长度为 $ell$ 的字符串。
- $forall s, ell, defellp{{ell ^ prime}} ellp$,有 $ell < ellp$,且字符串 $G(s, 1 ^ ell)$ 是 $G(s, 1 ^ ellp)$ 的前缀。
- 定义 $defGells{{G_ell(s)}} Gells riangleq G(s, 1 ^ {ell(|s|)})$,也就是说:对于每个多项式 $ell$,我们都可以给出一个扩展因子为 $ell$ 的伪随机发生器 $Gells$. 这个过程是通过可变长度的 PGR,造出定长的 PRG.
任何定长 PRG,都可以转化为不定长 PRG. 利用不定长 PRG,显然可以构造出一个不定长的私钥加密方案:利用 $G(k, 1 ^ {|m|})$ 来异或明文就行了。它可以支持任意长度的加密,而且也是语义安全的。
流密码
上面介绍的利用 PRG 的异或方案,称为流密码。想要执行加密,是先生成一个伪随机的比特流,然后用这个比特流来与明文异或,产生密文。由于流密码方案与生成比特流的方案是绑定的,我们以后直接用“流密码”来简称伪随机比特串发生器。
实际应用中,有 RC4 等流密码方案。RC4 不太安全,LFSR 非常不安全。目前来看,主张采用分组密码来进行加密;如果一定要用流密码,一般用分组密码造一个流出来。
多次加密的安全性
我们之前的讨论,全部是基于“敌手收到单个密文”的情况。但现实中,监听信道的窃听者往往可以听到多组密文,我们引入多消息窃听实验来对应这种情形。
多消息窃听实验 $defPrivKM{{PrivK ^ { extsf{mult}} _ {AA, Pi} }} PrivKM(n)$:
- 敌手 $AA$ 获取安全参数 $1 ^ n$,输出一对消息向量 $vec M _ 0 = (m _ 0 ^ 1, cdots, m _0 ^ t)$ 以及 $vec M _ 1 = (m _ 1 ^ 1, cdots, m _1 ^ t)$. 对于所有 $i$,需要满足 $|m _ 0 ^ i| = |m _ 1 ^ i|$(对应位置的明文必须等长)。
- 运行 $Gen(1 ^ n)$ 生成密钥 $k$,选择随机比特 $b$.
计算密文 $c ^ i la Enck(m _ b ^ i)$,将密文向量 $vec C = (c ^ 1, c^2, cdots c ^ t)$ 发给 $AA$.- $AA$ 输出一个比特 $bp$.
- 若 $bp =b$,则实验输出 1;否则输出 0.
利用这个多消息窃听实验,可以定义多次加密不可区分性。定义方法与窃听不可区分性一致:
对于一个对称密钥加密方案 $Pi$,若对于所有 PPT 敌手 $AA$ 有 $$Prleft [ PrivKM(n) = 1 ight ] leq frac12 + egl$$ 则称 $Pi$ 具备多次加密不可区分性。
显然,vernam 加密方法如果总是采用相同密钥,则它满足窃听不可区分性,但不满足多次加密不可区分性。构造方法如下:
- $AA$ 输出 $M_0 = (0 ^ n, 0 ^ n), M_1 = (0^n, 1^n)$
- $AA$ 对于返回的加密结果,只需要看看 $c^1$ 是否等于 $c^ 2$,如果相等则输出 $bp = 0$,否则输出 $bp = 1$.
容易证明,$AA$ 的成功概率是 100%.
概率加密
上面的例子已经证明了重放攻击的巨大威力。事实上,不难看出,如果相同的明文总会被加密成相同的密文,那么上面这个例子始终可以攻击成功。
我们从而发现,任何确定性的加密方案,对于多次加密来讲,都是不安全的。
令 $defGED{{(Gen,Enc,Dec)}} Pi=GED$ 为一个加密方案,若 $Enc$ 是密钥和消息的一个确定性的函数,则 $Pi$ 不具备窃听者存在情况下的多次加密不可区分性。
从而,要想做到多次加密不可区分,必须当相同的消息多次加密时,每次都产生不同的密文。
流密码安全多次加密方案
一般有两种基于流密码的多次方案,分别为同步模式和非同步模式。
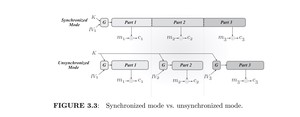
同步模式:双方使用密钥流的不同部分来加密每个信息。在这个模式下,双方必须同步通讯,来得知流的多少位已经被使用。这个算法虽然是确定性的,但在每一次加密过程中,密钥是互不重复的,因此对于每次加密来说,相同的明文也会被加密成不同的密文。
非同步模式:双方可以独立进行加密,无需维护状态。但是,这里需要 PRG 有两个输入:一个种子 $s$ 以及一个初始向量 $IV$. 如果两个 $IV$ 不一样,那么 PRG 的生成结果也不一样。
在非同步模式下,加密方法为 $$Enck(m) := langle IV, G(k,IV) oplus m angle$$ 其中 $IV$ 是随机选择,与异或结果一起输出。攻击者虽然能得到 $IV$,但由于没有种子 $k$,故仍然无法解密。
选择明文攻击(CPA)安全性
现在我们来考虑更强的攻击,即 CPA 攻击。敌手 $AA$ 允许访问一个 oracle,这个 oracle 能采用密钥 $k$ 加密信息并返回给敌手(敌手不知道 $k$)。
计算机科学常用 $defOO{{mathcal{O}}}defAO{{AA^{mathcal{O}(cdot)}}} AO$ 来表示 $AA$ 访问 oracle $OO$ 的过程。因此在这里,我们可以用 $defAE{{AA ^ {Enck(cdot)}}} AE$ 来表示 $AA$ 访问密钥为 $k$ 的加密 oracle.
如果 $Enc$ 过程是随机的,那么 oracle 每次回答一个询问,都会引入随机性。CPA 安全要求:即使敌手可以访问加密 oracle,敌手仍然不能区分两个任意消息的加密。
CPA不可区分实验 $defPrivKC{{ PrivK_{AA,Pi} ^ { extsf{cpa}} }} PrivKC(n)$:
- 运行 $Gen(1 ^ n)$ 生成密钥 $k$.
- 给敌手输入 $1 ^ n$,敌手可以访问 $defEnckd{Enck(cdot)} Enckd$,输出一对长度相等的信息 $m_0, m_1$.
- 选择一个随机比特 $b$,计算出 $c la Enck(m _ b)$ 交给 $AA$. $c$ 称为挑战密文。
- 敌手 $AA$ 可以继续访问 oracle. 最后输出一个比特 $bp$.
- 若 $bp = b$,则试验输出 1;否则输出 0. 若 $PrivKC(n) = 1$,则认为敌手 $AA$ 成功。
由此可以定义CPA 安全性。
一个对称密钥加密方案 $Pi=GED$,如果对于所有 PPT 敌手 $AA$,有 $$PrBig[ PrivKC(n) =1 Big] leq frac12 + egl(n)$$ 则称 $Pi$ 具有在选择明文攻击(CPA)条件下的不可区分性。
显然,“CPA安全”是比“窃听不可区分”更强的性质。任何确定性的加密方案,都不可能具有 CPA 安全性。换句话来讲,加密过程必须有随机性。
另有一点需要指出:单次加密 CPA 安全性,等价于多次加密 CPA 安全性。想要证明方案 $Pi$ 是多次加密 CPA 安全的,只需证明它是单次加密 CPA 安全的。
如果一个定长的加密方案是 CPA 安全的,我们只需要使用它来加密字符串的各个块,就能得到一个变长的加密方案。显然这也是 CPA 安全的。
伪随机函数
为了构造 CPA 安全的加密方案,我们有必要开始考虑伪随机函数(PRF)。接下来讨论的伪随机函数,用途都是把长度为 $n$ 的字符串映射到等长的字符串。
伪随机函数是带密钥的函数。一个带密钥的函数 $F$ 是双输入函数,$F:b ^ * imes b ^ * o b ^ *$,一个输入是密钥 $k$,另一个就叫输入。一般而言,密钥只选择一次,而会有很多个输入,故在选定密钥之后,我们关注单输入函数 $defFk{{F _ k}} Fk(x) riangleq F(k,x)$.
为讨论方便,我们只研究输入长度、输出长度、密钥长度都相等的 PRF. 如果存在一个确定的多项式时间算法,能够在给定 $k,x$ 的情况下计算出 $Fk(x)$,则称 $F$ 是有效的(加密方、解密方当然需要 $F$ 是可以计算的,才能用于加密)。
如果函数 $Fk$ 无法与一个从“拥有同样定义域、值域的函数集合”中均匀随机选出来的函数相区分,那么我们认为 $Fk$ 是看上去很随机的。换句话讲:如果没有 PPT 敌手可以区分 $Fk$ 和随机选择的 $f$,则称 $F$ 是伪随机的。
$f$ 是从高达 $2 ^ {ncdot 2 ^ n}$ 个候选函数里面选出来的,而 $F$ 是从 $2 ^ n$ 个函数里面选出来的。但 $F$ 的行为,对于任何 PPT 区分器来说,都应该看起来和真随机选择的 $f$ 相同。
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/10485.html