
要开始带组内的小朋友了,特意出一个Pytorch教程来指导一下
[!] 这里是实战教程,默认读者已经学会了部分深度学习原理,若有不懂的地方可以先停下来查查资料
MNIST是计算机视觉领域中最为基础的一个数据集,也是很多人第一个神经网络模型
MNIST数据集(Mixed National Institute of Standards and Technology database)是美国国家标准与技术研究院收集整理的大型手写数字数据集,包含了60,000个样本的训练集以及10,000个样本的测试集。

MNIST中所有样本都会将原本28*28的灰度图转换为长度为784的一维向量作为输入,其中每个元素分别对应了灰度图中的灰度值。MNIST使用一个长度为10的one-hot向量作为该样本所对应的标签,其中向量索引值对应了该样本以该索引为结果的预测概率。
2.1 任务目的
如本文标题所示,MNIST手写数字识别的主要目为:训练出一个模型,让这个模型能够对手写数字图片进行分类。
2.2 开发环境
为了实现本文的目标,你需要安装如下Python库
Pytorch官网上有着详细的安装教程,你可以看着来进行安装 - 传送门
tqdm库是Python的一个动态显示库,我们需要他来进行训练可视化
matplotlib库是Python的一个数据可视化库,我们需要他来进行训练结果可视化
2.3 实现流程
本代码的实现流程如下所示
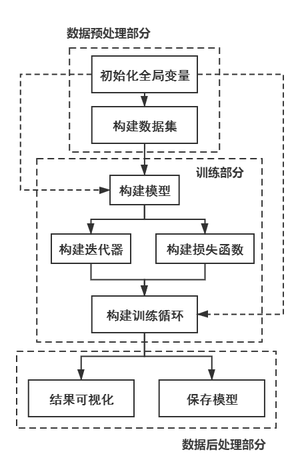
3.1 数据预处理部分
3.1.1 初始化全局变量
首先,我们需要导入上述提到的库,为了能够更全面的展示程序中每个函数的具体来源,因此本项目中的库不采用缩写的方式
对于Pytorch,我们需要手动去定义它是在CPU还是在GPU中训练;同时,我们需要使用到torchvision中的图片处理库torchvision.transforms来将图片转换为适用于网络的张量。
3.1.2 构建数据集
torchvision中的torchvision.datasets库中提供了MNIST数据集的下载地址,因此我们可以直接二调用对应的函数来下载MNIST的训练集和测试集
Pytorch中提供了一种叫做DataLoader的方法来让我们进行训练,该方法自动将数据集打包成为迭代器,能够让我们很方便地进行后续的训练处理
至此,数据集已经准备完毕。
3.2 训练部分
3.2.1 构建模型
在这里使用的是一个简单的卷积神经网络,其结构如下
其中torch.nn.Sequential函数能够自动将层数合并为一个模型,对于新手而言这种方式能够减少非常多的计算过程
随后,我们需要构建一个模型实例
to() 方法用于将张量放入到指定的设备(如CPU或GPU中),记住的是:不同设备的张量是无法进行运算的
如果一切正常,那么输出结果如下
读者也可以根据自己的兴趣去修改网络结构。
3.2.2 构建迭代器与损失函数
模型在构建迭代器的时候需要将所有参数传入到迭代器中,可以通过net.parameters()方法来得到模型的所有参数。
3.2.3 构建训练循环
训练循环是很多新手最头疼的地方,因此将会着重讲解这一部分
我们根据这个流程,构建一个循环框架
3.2.3.1 训练部分代码
对于训练部分,我们可以构造的模块为
3.2.3.2 测试部分代码
对于测试部分,我们可以构造的模块为
3.2.3.3 训练循环代码
将上述两个循环进行结合,就是最终的训练循环代码了
假如一切正常,能看到以下的训练过程
3.3 数据预后处理部分
数据后处理的部分包括训练结果可视化以及模型保存两个环节
3.3.1 训练结果可视化
我们需要使用到matplotlib来对结果进行可视化
结果如下图所示
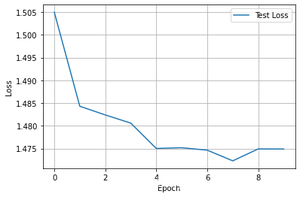
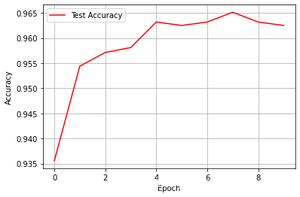
3.3.2 保存模型
对于新手而言,我们选择直接保存整个模型
若想对这一方面有进一步的了解,可以参考这篇文章 传送门
版权声明:
本文来源网络,所有图片文章版权属于原作者,如有侵权,联系删除。
本文网址:https://www.mushiming.com/mjsbk/10125.html